 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDream-Box: Object-wise Outlier Generation for Out-of-Distribution Detection
Apr 25, 2025Deep neural networks have demonstrated great generalization capabilities for tasks whose training and test sets are drawn from the same distribution. Nevertheless, out-of-distribution (OOD) detection remains a challenging task that has received significant attention in recent years. Specifically, OOD detection refers to the detection of instances that do not belong to the training distribution, while still having good performance on the in-distribution task (e.g., classification or object detection). Recent work has focused on generating synthetic outliers and using them to train an outlier detector, generally achieving improved OOD detection than traditional OOD methods. In this regard, outliers can be generated either in feature or pixel space. Feature space driven methods have shown strong performance on both the classification and object detection tasks, at the expense that the visualization of training outliers remains unknown, making further analysis on OOD failure modes challenging. On the other hand, pixel space outlier generation techniques enabled by diffusion models have been used for image classification using, providing improved OOD detection performance and outlier visualization, although their adaption to the object detection task is as yet unexplored. We therefore introduce Dream-Box, a method that provides a link to object-wise outlier generation in the pixel space for OOD detection. Specifically, we use diffusion models to generate object-wise outliers that are used to train an object detector for an in-distribution task and OOD detection. Our method achieves comparable performance to previous traditional methods while being the first technique to provide concrete visualization of generated OOD objects.
FEVER-OOD: Free Energy Vulnerability Elimination for Robust Out-of-Distribution Detection
Dec 02, 2024



Modern machine learning models, that excel on computer vision tasks such as classification and object detection, are often overconfident in their predictions for Out-of-Distribution (OOD) examples, resulting in unpredictable behaviour for open-set environments. Recent works have demonstrated that the free energy score is an effective measure of uncertainty for OOD detection given its close relationship to the data distribution. However, despite free energy-based methods representing a significant empirical advance in OOD detection, our theoretical analysis reveals previously unexplored and inherent vulnerabilities within the free energy score formulation such that in-distribution and OOD instances can have distinct feature representations yet identical free energy scores. This phenomenon occurs when the vector direction representing the feature space difference between the in-distribution and OOD sample lies within the null space of the last layer of a neural-based classifier. To mitigate these issues, we explore lower-dimensional feature spaces to reduce the null space footprint and introduce novel regularisation to maximize the least singular value of the final linear layer, hence enhancing inter-sample free energy separation. We refer to these techniques as Free Energy Vulnerability Elimination for Robust Out-of-Distribution Detection (FEVER-OOD). Our experiments show that FEVER-OOD techniques achieve state of the art OOD detection in Imagenet-100, with average OOD false positive rate (at 95% true positive rate) of 35.83% when used with the baseline Dream-OOD model.
Towards Open-World Object-based Anomaly Detection via Self-Supervised Outlier Synthesis
Jul 22, 2024Object detection is a pivotal task in computer vision that has received significant attention in previous years. Nonetheless, the capability of a detector to localise objects out of the training distribution remains unexplored. Whilst recent approaches in object-level out-of-distribution (OoD) detection heavily rely on class labels, such approaches contradict truly open-world scenarios where the class distribution is often unknown. In this context, anomaly detection focuses on detecting unseen instances rather than classifying detections as OoD. This work aims to bridge this gap by leveraging an open-world object detector and an OoD detector via virtual outlier synthesis. This is achieved by using the detector backbone features to first learn object pseudo-classes via self-supervision. These pseudo-classes serve as the basis for class-conditional virtual outlier sampling of anomalous features that are classified by an OoD head. Our approach empowers our overall object detector architecture to learn anomaly-aware feature representations without relying on class labels, hence enabling truly open-world object anomaly detection. Empirical validation of our approach demonstrates its effectiveness across diverse datasets encompassing various imaging modalities (visible, infrared, and X-ray). Moreover, our method establishes state-of-the-art performance on object-level anomaly detection, achieving an average recall score improvement of over 5.4% for natural images and 23.5% for a security X-ray dataset compared to the current approaches. In addition, our method detects anomalies in datasets where current approaches fail. Code available at https://github.com/KostadinovShalon/oln-ssos.
Performance Evaluation of Segment Anything Model with Variational Prompting for Application to Non-Visible Spectrum Imagery
Apr 18, 2024



The Segment Anything Model (SAM) is a deep neural network foundational model designed to perform instance segmentation which has gained significant popularity given its zero-shot segmentation ability. SAM operates by generating masks based on various input prompts such as text, bounding boxes, points, or masks, introducing a novel methodology to overcome the constraints posed by dataset-specific scarcity. While SAM is trained on an extensive dataset, comprising ~11M images, it mostly consists of natural photographic images with only very limited images from other modalities. Whilst the rapid progress in visual infrared surveillance and X-ray security screening imaging technologies, driven forward by advances in deep learning, has significantly enhanced the ability to detect, classify and segment objects with high accuracy, it is not evident if the SAM zero-shot capabilities can be transferred to such modalities. This work assesses SAM capabilities in segmenting objects of interest in the X-ray/infrared modalities. Our approach reuses the pre-trained SAM with three different prompts: bounding box, centroid and random points. We present quantitative/qualitative results to showcase the performance on selected datasets. Our results show that SAM can segment objects in the X-ray modality when given a box prompt, but its performance varies for point prompts. Specifically, SAM performs poorly in segmenting slender objects and organic materials, such as plastic bottles. We find that infrared objects are also challenging to segment with point prompts given the low-contrast nature of this modality. This study shows that while SAM demonstrates outstanding zero-shot capabilities with box prompts, its performance ranges from moderate to poor for point prompts, indicating that special consideration on the cross-modal generalisation of SAM is needed when considering use on X-ray/infrared imagery.
Exact-NeRF: An Exploration of a Precise Volumetric Parameterization for Neural Radiance Fields
Nov 22, 2022



Neural Radiance Fields (NeRF) have attracted significant attention due to their ability to synthesize novel scene views with great accuracy. However, inherent to their underlying formulation, the sampling of points along a ray with zero width may result in ambiguous representations that lead to further rendering artifacts such as aliasing in the final scene. To address this issue, the recent variant mip-NeRF proposes an Integrated Positional Encoding (IPE) based on a conical view frustum. Although this is expressed with an integral formulation, mip-NeRF instead approximates this integral as the expected value of a multivariate Gaussian distribution. This approximation is reliable for short frustums but degrades with highly elongated regions, which arises when dealing with distant scene objects under a larger depth of field. In this paper, we explore the use of an exact approach for calculating the IPE by using a pyramid-based integral formulation instead of an approximated conical-based one. We denote this formulation as Exact-NeRF and contribute the first approach to offer a precise analytical solution to the IPE within the NeRF domain. Our exploratory work illustrates that such an exact formulation Exact-NeRF matches the accuracy of mip-NeRF and furthermore provides a natural extension to more challenging scenarios without further modification, such as in the case of unbounded scenes. Our contribution aims to both address the hitherto unexplored issues of frustum approximation in earlier NeRF work and additionally provide insight into the potential future consideration of analytical solutions in future NeRF extensions.
UAV-ReID: A Benchmark on Unmanned Aerial Vehicle Re-identification
Apr 13, 2021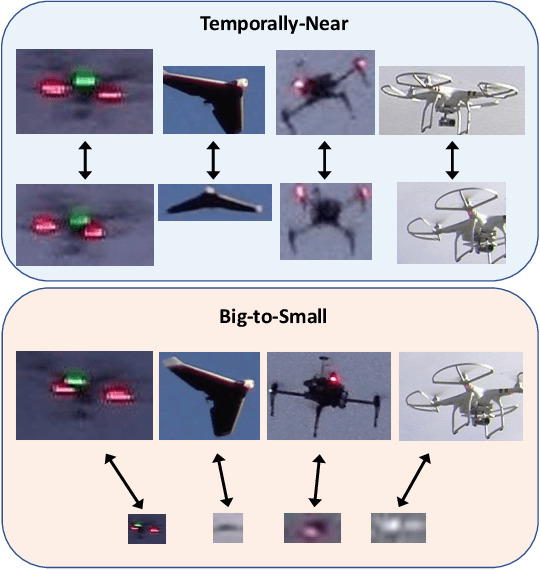
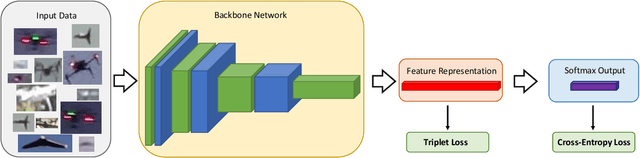

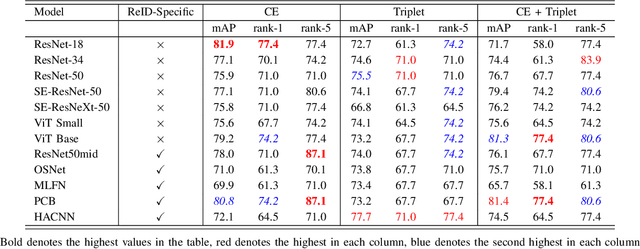
As unmanned aerial vehicles (UAVs) become more accessible with a growing range of applications, the potential risk of UAV disruption increases. Recent development in deep learning allows vision-based counter-UAV systems to detect and track UAVs with a single camera. However, the coverage of a single camera is limited, necessitating the need for multicamera configurations to match UAVs across cameras - a problem known as re-identification (reID). While there has been extensive research on person and vehicle reID to match objects across time and viewpoints, to the best of our knowledge, there has been no research in UAV reID. UAVs are challenging to re-identify: they are much smaller than pedestrians and vehicles and they are often detected in the air so appear at a greater range of angles. Because no UAV data sets currently use multiple cameras, we propose the first new UAV re-identification data set, UAV-reID, that facilitates the development of machine learning solutions in this emerging area. UAV-reID has two settings: Temporally-Near to evaluate performance across views to assist tracking frameworks, and Big-to-Small to evaluate reID performance across scale and to allow early reID when UAVs are detected from a long distance. We conduct a benchmark study by extensively evaluating different reID backbones and loss functions. We demonstrate that with the right setup, deep networks are powerful enough to learn good representations for UAVs, achieving 81.9% mAP on the Temporally-Near setting and 46.5% on the challenging Big-to-Small setting. Furthermore, we find that vision transformers are the most robust to extreme variance of scale.
Unmanned Aerial Vehicle Visual Detection and Tracking using Deep Neural Networks: A Performance Benchmark
Mar 29, 2021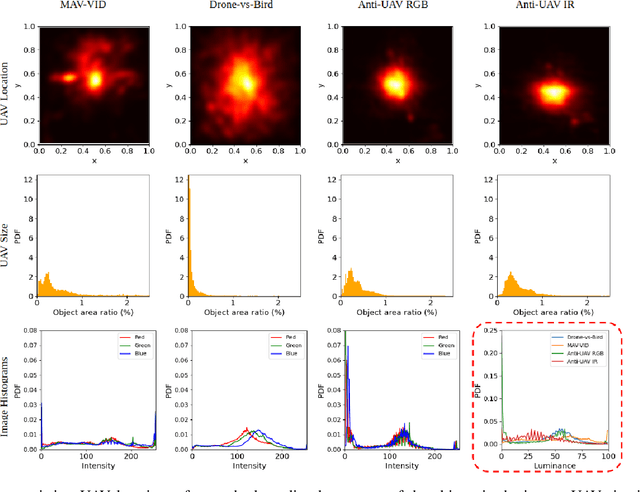
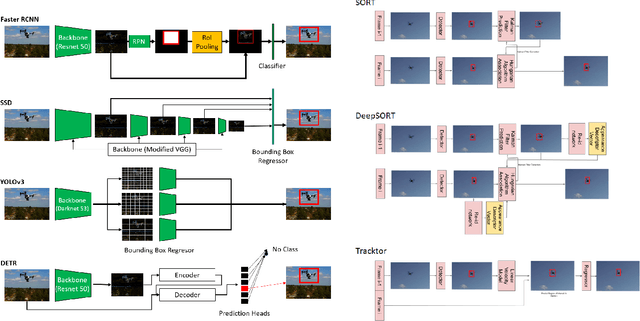

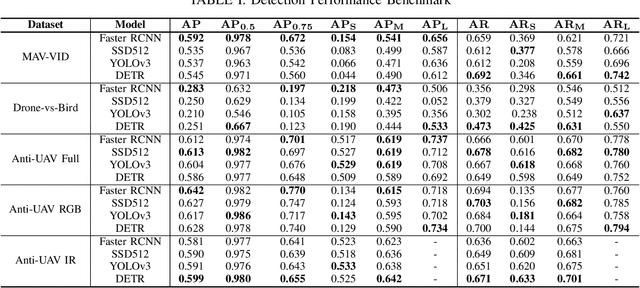
Unmanned Aerial Vehicles (UAV) can pose a major risk for aviation safety, due to both negligent and malicious use. For this reason, the automated detection and tracking of UAV is a fundamental task in aerial security systems. Common technologies for UAV detection include visible-band and thermal infrared imaging, radio frequency and radar. Recent advances in deep neural networks (DNNs) for image-based object detection open the possibility to use visual information for this detection and tracking task. Furthermore, these detection architectures can be implemented as backbones for visual tracking systems, thereby enabling persistent tracking of UAV incursions. To date, no comprehensive performance benchmark exists that applies DNNs to visible-band imagery for UAV detection and tracking. To this end, three datasets with varied environmental conditions for UAV detection and tracking, comprising a total of 241 videos (331,486 images), are assessed using four detection architectures and three tracking frameworks. The best performing detector architecture obtains an mAP of 98.6% and the best performing tracking framework obtains a MOTA of 96.3%. Cross-modality evaluation is carried out between visible and infrared spectrums, achieving a maximal 82.8% mAP on visible images when training in the infrared modality. These results provide the first public multi-approach benchmark for state-of-the-art deep learning-based methods and give insight into which detection and tracking architectures are effective in the UAV domain.