 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobIn: A Robust Interpretable Deep Network for Schizophrenia Diagnosis
Mar 31, 2022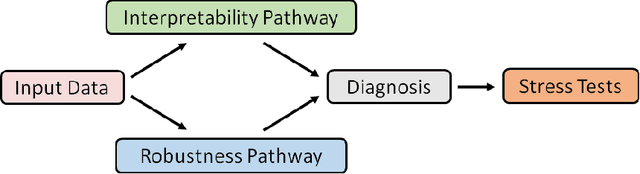
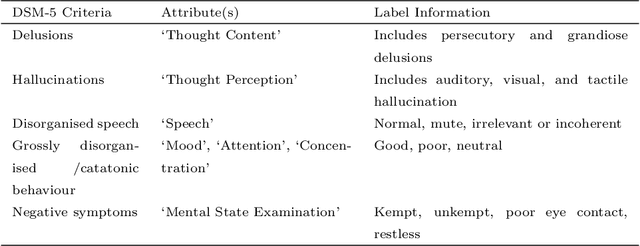

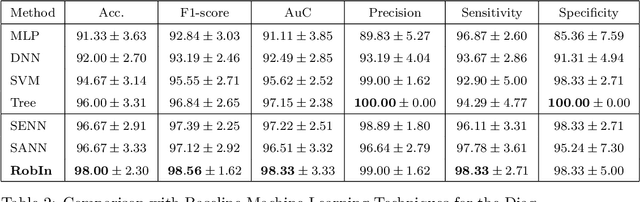
Schizophrenia is a severe mental health condition that requires a long and complicated diagnostic process. However, early diagnosis is vital to control symptoms. Deep learning has recently become a popular way to analyse and interpret medical data. Past attempts to use deep learning for schizophrenia diagnosis from brain-imaging data have shown promise but suffer from a large training-application gap - it is difficult to apply lab research to the real world. We propose to reduce this training-application gap by focusing on readily accessible data. We collect a data set of psychiatric observations of patients based on DSM-5 criteria. Because similar data is already recorded in all mental health clinics that diagnose schizophrenia using DSM-5, our method could be easily integrated into current processes as a tool to assist clinicians, whilst abiding by formal diagnostic criteria. To facilitate real-world usage of our system, we show that it is interpretable and robust. Understanding how a machine learning tool reaches its diagnosis is essential to allow clinicians to trust that diagnosis. To interpret the framework, we fuse two complementary attention mechanisms, 'squeeze and excitation' and 'self-attention', to determine global attribute importance and attribute interactivity, respectively. The model uses these importance scores to make decisions. This allows clinicians to understand how a diagnosis was reached, improving trust in the model. Because machine learning models often struggle to generalise to data from different sources, we perform experiments with augmented test data to evaluate the model's applicability to the real world. We find that our model is more robust to perturbations, and should therefore perform better in a clinical setting. It achieves 98% accuracy with 10-fold cross-validation.
Absolute Zero-Shot Learning
Feb 23, 2022
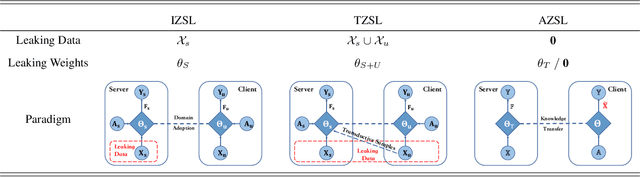
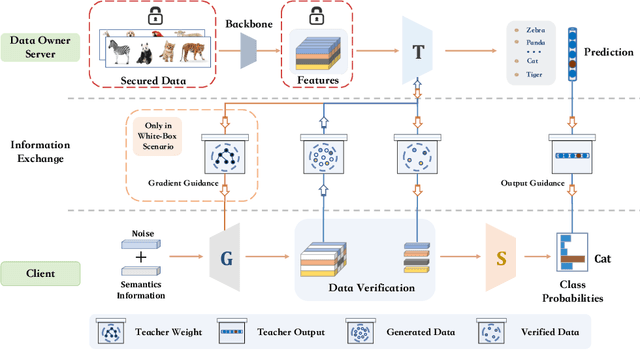

Considering the increasing concerns about data copyright and privacy issues, we present a novel Absolute Zero-Shot Learning (AZSL) paradigm, i.e., training a classifier with zero real data. The key innovation is to involve a teacher model as the data safeguard to guide the AZSL model training without data leaking. The AZSL model consists of a generator and student network, which can achieve date-free knowledge transfer while maintaining the performance of the teacher network. We investigate `black-box' and `white-box' scenarios in AZSL task as different levels of model security. Besides, we also provide discussion of teacher model in both inductive and transductive settings. Despite embarrassingly simple implementations and data-missing disadvantages, our AZSL framework can retain state-of-the-art ZSL and GZSL performance under the `white-box' scenario. Extensive qualitative and quantitative analysis also demonstrates promising results when deploying the model under `black-box' scenario.
UAV-ReID: A Benchmark on Unmanned Aerial Vehicle Re-identification
Apr 13, 2021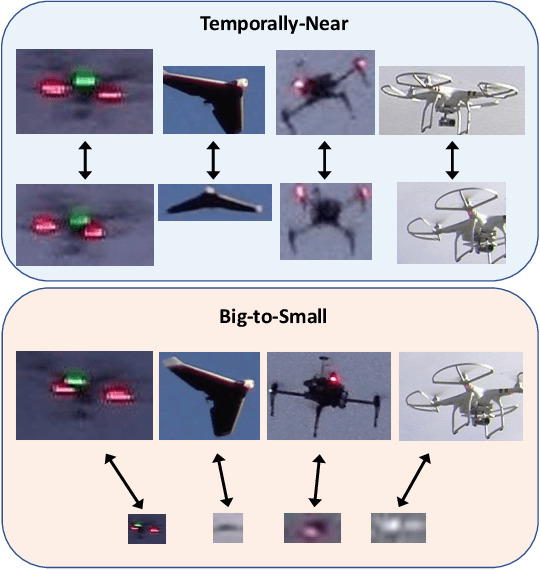
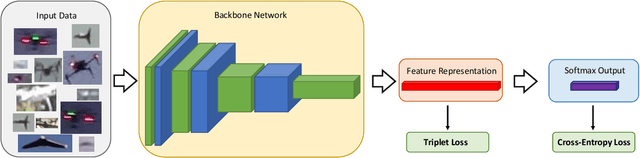

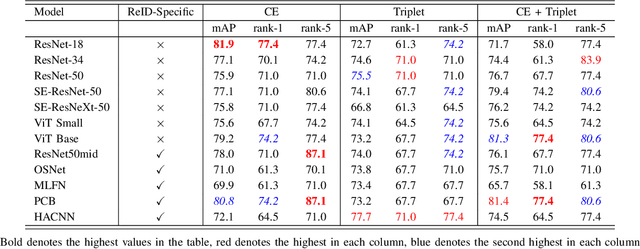
As unmanned aerial vehicles (UAVs) become more accessible with a growing range of applications, the potential risk of UAV disruption increases. Recent development in deep learning allows vision-based counter-UAV systems to detect and track UAVs with a single camera. However, the coverage of a single camera is limited, necessitating the need for multicamera configurations to match UAVs across cameras - a problem known as re-identification (reID). While there has been extensive research on person and vehicle reID to match objects across time and viewpoints, to the best of our knowledge, there has been no research in UAV reID. UAVs are challenging to re-identify: they are much smaller than pedestrians and vehicles and they are often detected in the air so appear at a greater range of angles. Because no UAV data sets currently use multiple cameras, we propose the first new UAV re-identification data set, UAV-reID, that facilitates the development of machine learning solutions in this emerging area. UAV-reID has two settings: Temporally-Near to evaluate performance across views to assist tracking frameworks, and Big-to-Small to evaluate reID performance across scale and to allow early reID when UAVs are detected from a long distance. We conduct a benchmark study by extensively evaluating different reID backbones and loss functions. We demonstrate that with the right setup, deep networks are powerful enough to learn good representations for UAVs, achieving 81.9% mAP on the Temporally-Near setting and 46.5% on the challenging Big-to-Small setting. Furthermore, we find that vision transformers are the most robust to extreme variance of scale.
Unmanned Aerial Vehicle Visual Detection and Tracking using Deep Neural Networks: A Performance Benchmark
Mar 29, 2021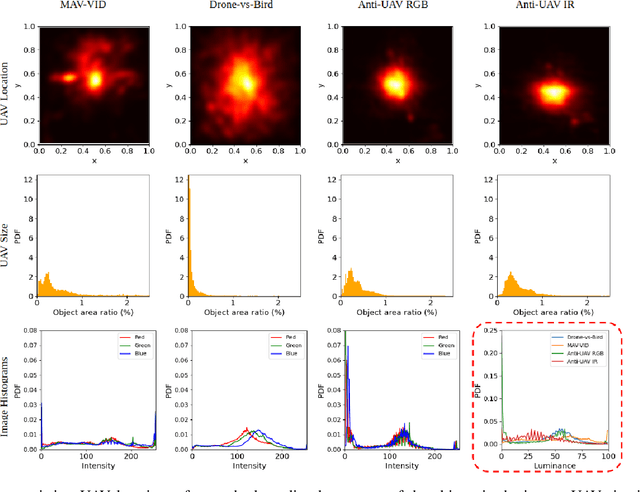
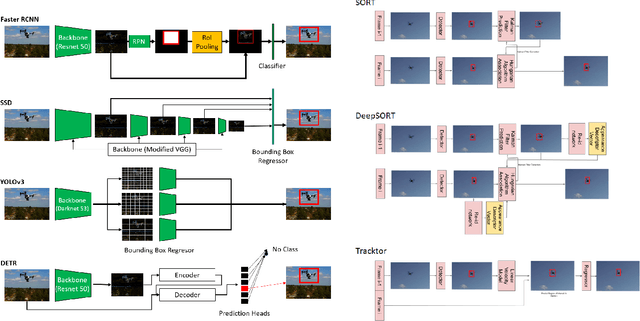

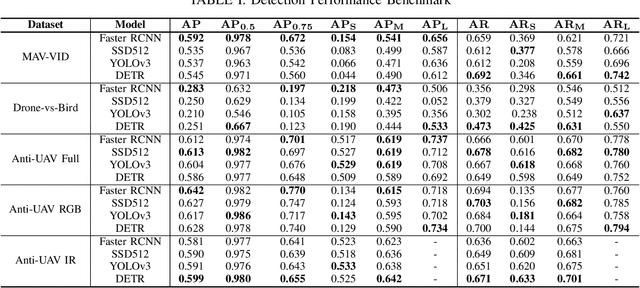
Unmanned Aerial Vehicles (UAV) can pose a major risk for aviation safety, due to both negligent and malicious use. For this reason, the automated detection and tracking of UAV is a fundamental task in aerial security systems. Common technologies for UAV detection include visible-band and thermal infrared imaging, radio frequency and radar. Recent advances in deep neural networks (DNNs) for image-based object detection open the possibility to use visual information for this detection and tracking task. Furthermore, these detection architectures can be implemented as backbones for visual tracking systems, thereby enabling persistent tracking of UAV incursions. To date, no comprehensive performance benchmark exists that applies DNNs to visible-band imagery for UAV detection and tracking. To this end, three datasets with varied environmental conditions for UAV detection and tracking, comprising a total of 241 videos (331,486 images), are assessed using four detection architectures and three tracking frameworks. The best performing detector architecture obtains an mAP of 98.6% and the best performing tracking framework obtains a MOTA of 96.3%. Cross-modality evaluation is carried out between visible and infrared spectrums, achieving a maximal 82.8% mAP on visible images when training in the infrared modality. These results provide the first public multi-approach benchmark for state-of-the-art deep learning-based methods and give insight into which detection and tracking architectures are effective in the UAV domain.