 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalRAG: Enhancing Global Reasoning in Multi-hop Question Answering via Reinforcement Learning
Oct 23, 2025Reinforcement learning has recently shown promise in improving retrieval-augmented generation (RAG). Despite these advances, its effectiveness in multi-hop question answering (QA) remains limited by two fundamental limitations: (i) global planning absence to structure multi-step reasoning, and (ii) unfaithful execution, which hinders effective query formulation and consistent use of retrieved evidence. We propose GlobalRAG, a reinforcement learning framework designed to enhance global reasoning in multi-hop QA. GlobalRAG decomposes questions into subgoals, coordinates retrieval with reasoning, and refines evidence iteratively. To guide this process, we introduce Planning Quality Reward and SubGoal Completion Reward, which encourage coherent planning and reliable subgoal execution. In addition, a progressive weight annealing strategy balances process-oriented and outcome-based objectives. Extensive experiments on both in-domain and out-of-domain benchmarks demonstrate that GlobalRAG significantly outperforms strong baselines while using only 8k training data (42% of the training data used by strong baselines), achieving average improvements of 14.2% in both EM and F1.
D2Fusion: Dual-domain Fusion with Feature Superposition for Deepfake Detection
Mar 21, 2025Deepfake detection is crucial for curbing the harm it causes to society. However, current Deepfake detection methods fail to thoroughly explore artifact information across different domains due to insufficient intrinsic interactions. These interactions refer to the fusion and coordination after feature extraction processes across different domains, which are crucial for recognizing complex forgery clues. Focusing on more generalized Deepfake detection, in this work, we introduce a novel bi-directional attention module to capture the local positional information of artifact clues from the spatial domain. This enables accurate artifact localization, thus addressing the coarse processing with artifact features. To further address the limitation that the proposed bi-directional attention module may not well capture global subtle forgery information in the artifact feature (e.g., textures or edges), we employ a fine-grained frequency attention module in the frequency domain. By doing so, we can obtain high-frequency information in the fine-grained features, which contains the global and subtle forgery information. Although these features from the diverse domains can be effectively and independently improved, fusing them directly does not effectively improve the detection performance. Therefore, we propose a feature superposition strategy that complements information from spatial and frequency domains. This strategy turns the feature components into the form of wave-like tokens, which are updated based on their phase, such that the distinctions between authentic and artifact features can be amplified. Our method demonstrates significant improvements over state-of-the-art (SOTA) methods on five public Deepfake datasets in capturing abnormalities across different manipulated operations and real-life.
Sentinel-Guided Zero-Shot Learning: A Collaborative Paradigm without Real Data Exposure
Mar 14, 2024



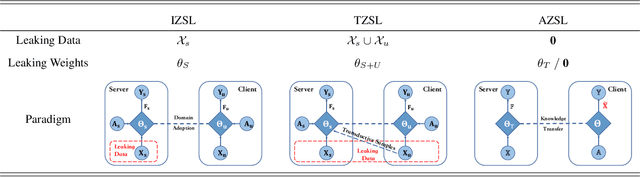
With increasing concerns over data privacy and model copyrights, especially in the context of collaborations between AI service providers and data owners, an innovative SG-ZSL paradigm is proposed in this work. SG-ZSL is designed to foster efficient collaboration without the need to exchange models or sensitive data. It consists of a teacher model, a student model and a generator that links both model entities. The teacher model serves as a sentinel on behalf of the data owner, replacing real data, to guide the student model at the AI service provider's end during training. Considering the disparity of knowledge space between the teacher and student, we introduce two variants of the teacher model: the omniscient and the quasi-omniscient teachers. Under these teachers' guidance, the student model seeks to match the teacher model's performance and explores domains that the teacher has not covered. To trade off between privacy and performance, we further introduce two distinct security-level training protocols: white-box and black-box, enhancing the paradigm's adaptability. Despite the inherent challenges of real data absence in the SG-ZSL paradigm, it consistently outperforms in ZSL and GZSL tasks, notably in the white-box protocol. Our comprehensive evaluation further attests to its robustness and efficiency across various setups, including stringent black-box training protocol.
ConRF: Zero-shot Stylization of 3D Scenes with Conditioned Radiation Fields
Feb 02, 2024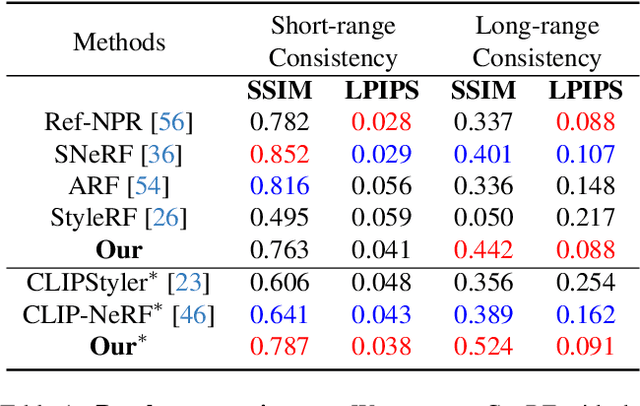
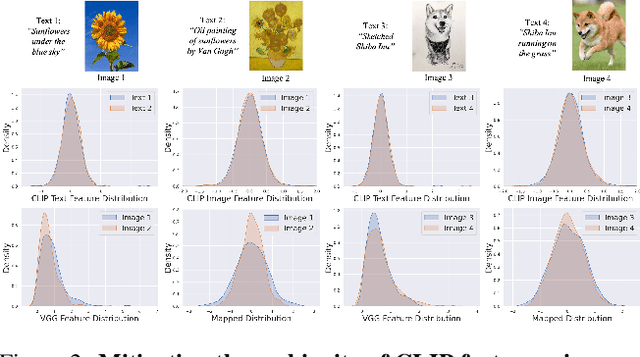
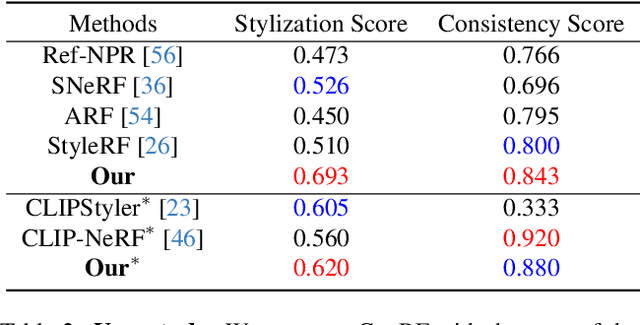
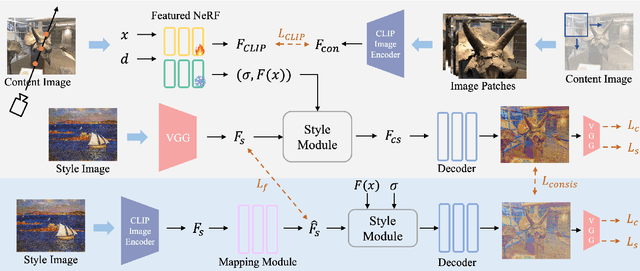
Most of the existing works on arbitrary 3D NeRF style transfer required retraining on each single style condition. This work aims to achieve zero-shot controlled stylization in 3D scenes utilizing text or visual input as conditioning factors. We introduce ConRF, a novel method of zero-shot stylization. Specifically, due to the ambiguity of CLIP features, we employ a conversion process that maps the CLIP feature space to the style space of a pre-trained VGG network and then refine the CLIP multi-modal knowledge into a style transfer neural radiation field. Additionally, we use a 3D volumetric representation to perform local style transfer. By combining these operations, ConRF offers the capability to utilize either text or images as references, resulting in the generation of sequences with novel views enhanced by global or local stylization. Our experiment demonstrates that ConRF outperforms other existing methods for 3D scene and single-text stylization in terms of visual quality.
CTNeRF: Cross-Time Transformer for Dynamic Neural Radiance Field from Monocular Video
Jan 10, 2024



The goal of our work is to generate high-quality novel views from monocular videos of complex and dynamic scenes. Prior methods, such as DynamicNeRF, have shown impressive performance by leveraging time-varying dynamic radiation fields. However, these methods have limitations when it comes to accurately modeling the motion of complex objects, which can lead to inaccurate and blurry renderings of details. To address this limitation, we propose a novel approach that builds upon a recent generalization NeRF, which aggregates nearby views onto new viewpoints. However, such methods are typically only effective for static scenes. To overcome this challenge, we introduce a module that operates in both the time and frequency domains to aggregate the features of object motion. This allows us to learn the relationship between frames and generate higher-quality images. Our experiments demonstrate significant improvements over state-of-the-art methods on dynamic scene datasets. Specifically, our approach outperforms existing methods in terms of both the accuracy and visual quality of the synthesized views.
DS-Depth: Dynamic and Static Depth Estimation via a Fusion Cost Volume
Aug 14, 2023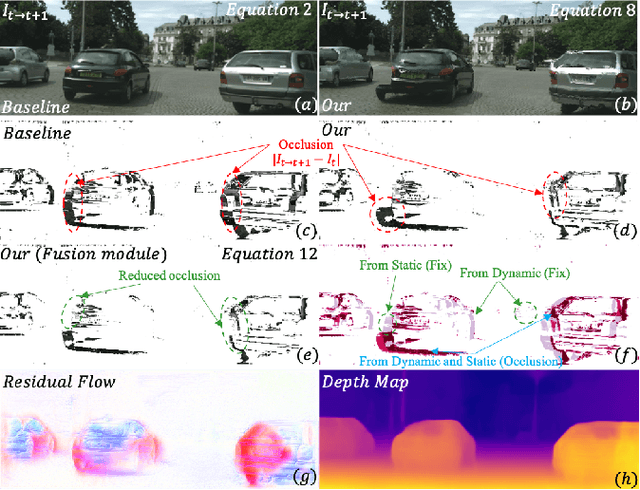
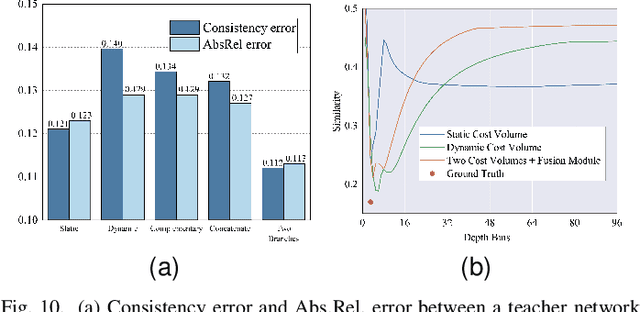
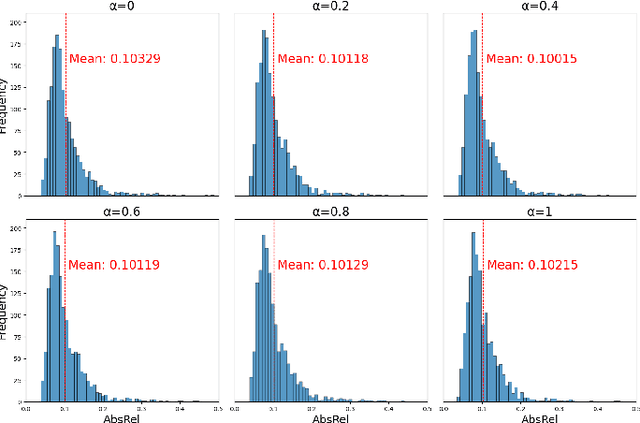
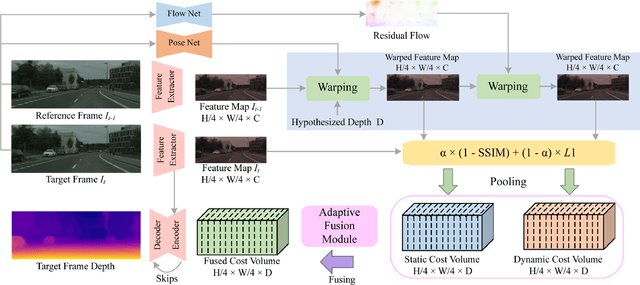
Self-supervised monocular depth estimation methods typically rely on the reprojection error to capture geometric relationships between successive frames in static environments. However, this assumption does not hold in dynamic objects in scenarios, leading to errors during the view synthesis stage, such as feature mismatch and occlusion, which can significantly reduce the accuracy of the generated depth maps. To address this problem, we propose a novel dynamic cost volume that exploits residual optical flow to describe moving objects, improving incorrectly occluded regions in static cost volumes used in previous work. Nevertheless, the dynamic cost volume inevitably generates extra occlusions and noise, thus we alleviate this by designing a fusion module that makes static and dynamic cost volumes compensate for each other. In other words, occlusion from the static volume is refined by the dynamic volume, and incorrect information from the dynamic volume is eliminated by the static volume. Furthermore, we propose a pyramid distillation loss to reduce photometric error inaccuracy at low resolutions and an adaptive photometric error loss to alleviate the flow direction of the large gradient in the occlusion regions. We conducted extensive experiments on the KITTI and Cityscapes datasets, and the results demonstrate that our model outperforms previously published baselines for self-supervised monocular depth estimation.
Absolute Zero-Shot Learning
Feb 23, 2022
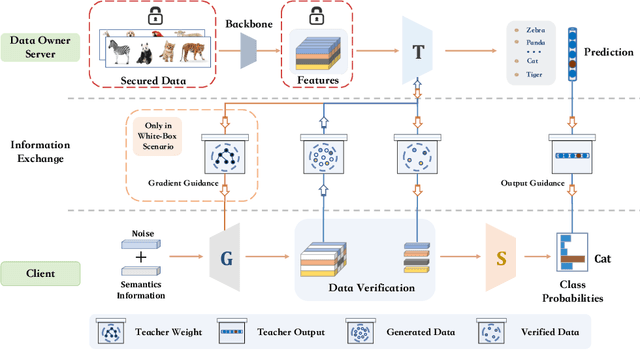

Considering the increasing concerns about data copyright and privacy issues, we present a novel Absolute Zero-Shot Learning (AZSL) paradigm, i.e., training a classifier with zero real data. The key innovation is to involve a teacher model as the data safeguard to guide the AZSL model training without data leaking. The AZSL model consists of a generator and student network, which can achieve date-free knowledge transfer while maintaining the performance of the teacher network. We investigate `black-box' and `white-box' scenarios in AZSL task as different levels of model security. Besides, we also provide discussion of teacher model in both inductive and transductive settings. Despite embarrassingly simple implementations and data-missing disadvantages, our AZSL framework can retain state-of-the-art ZSL and GZSL performance under the `white-box' scenario. Extensive qualitative and quantitative analysis also demonstrates promising results when deploying the model under `black-box' scenario.