 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2Fusion: Dual-domain Fusion with Feature Superposition for Deepfake Detection
Mar 21, 2025Deepfake detection is crucial for curbing the harm it causes to society. However, current Deepfake detection methods fail to thoroughly explore artifact information across different domains due to insufficient intrinsic interactions. These interactions refer to the fusion and coordination after feature extraction processes across different domains, which are crucial for recognizing complex forgery clues. Focusing on more generalized Deepfake detection, in this work, we introduce a novel bi-directional attention module to capture the local positional information of artifact clues from the spatial domain. This enables accurate artifact localization, thus addressing the coarse processing with artifact features. To further address the limitation that the proposed bi-directional attention module may not well capture global subtle forgery information in the artifact feature (e.g., textures or edges), we employ a fine-grained frequency attention module in the frequency domain. By doing so, we can obtain high-frequency information in the fine-grained features, which contains the global and subtle forgery information. Although these features from the diverse domains can be effectively and independently improved, fusing them directly does not effectively improve the detection performance. Therefore, we propose a feature superposition strategy that complements information from spatial and frequency domains. This strategy turns the feature components into the form of wave-like tokens, which are updated based on their phase, such that the distinctions between authentic and artifact features can be amplified. Our method demonstrates significant improvements over state-of-the-art (SOTA) methods on five public Deepfake datasets in capturing abnormalities across different manipulated operations and real-life.
FedSCA: Federated Tuning with Similarity-guided Collaborative Aggregation for Heterogeneous Medical Image Segmentation
Mar 19, 2025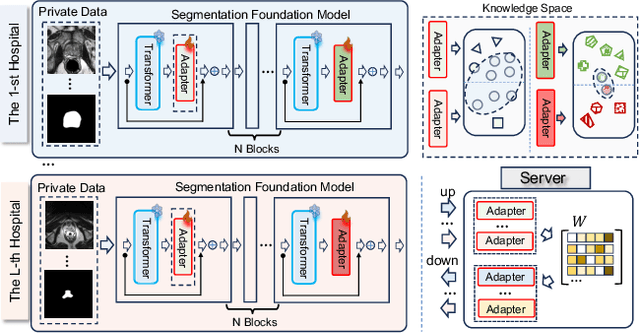
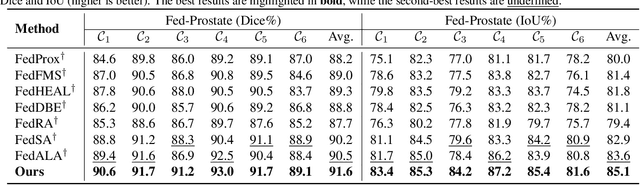
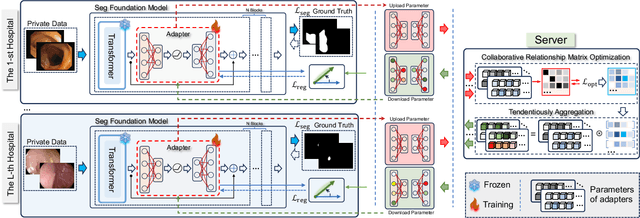
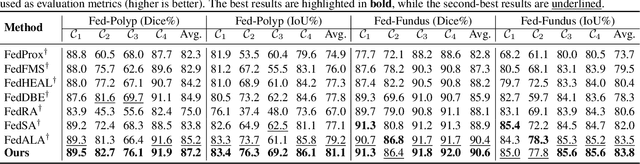
Transformer-based foundation models (FMs) have recently demonstrated remarkable performance in medical image segmentation. However, scaling these models is challenging due to the limited size of medical image datasets within isolated hospitals, where data centralization is restricted due to privacy concerns. These constraints, combined with the data-intensive nature of FMs, hinder their broader application. Integrating federated learning (FL) with foundation models (FLFM) fine-tuning offers a potential solution to these challenges by enabling collaborative model training without data sharing, thus allowing FMs to take advantage of a diverse pool of sensitive medical image data across hospitals/clients. However, non-independent and identically distributed (non-IID) data among clients, paired with computational and communication constraints in federated environments, presents an additional challenge that limits further performance improvements and remains inadequately addressed in existing studies. In this work, we propose a novel FLFM fine-tuning framework, \underline{\textbf{Fed}}erated tuning with \underline{\textbf{S}}imilarity-guided \underline{\textbf{C}}ollaborative \underline{\textbf{A}}ggregation (FedSCA), encompassing all phases of the FL process. This includes (1) specially designed parameter-efficient fine-tuning (PEFT) for local client training to enhance computational efficiency; (2) partial low-level adapter transmission for communication efficiency; and (3) similarity-guided collaborative aggregation (SGCA) on the server side to address non-IID issues. Extensive experiments on three FL benchmarks for medical image segmentation demonstrate the effectiveness of our proposed FedSCA, establishing new SOTA performance.
A Circular Construction Product Ontology for End-of-Life Decision-Making
Mar 17, 2025Efficient management of end-of-life (EoL) products is critical for advancing circularity in supply chains, particularly within the construction industry where EoL strategies are hindered by heterogenous lifecycle data and data silos. Current tools like Environmental Product Declarations (EPDs) and Digital Product Passports (DPPs) are limited by their dependency on seamless data integration and interoperability which remain significant challenges. To address these, we present the Circular Construction Product Ontology (CCPO), an applied framework designed to overcome semantic and data heterogeneity challenges in EoL decision-making for construction products. CCPO standardises vocabulary and facilitates data integration across supply chain stakeholders enabling lifecycle assessments (LCA) and robust decision-making. By aggregating disparate data into a unified product provenance, CCPO enables automated EoL recommendations through customisable SWRL rules aligned with European standards and stakeholder-specific circularity SLAs, demonstrating its scalability and integration capabilities. The adopted circular product scenario depicts CCPO's application while competency question evaluations show its superior performance in generating accurate EoL suggestions highlighting its potential to greatly improve decision-making in circular supply chains and its applicability in real-world construction environments.
Laser: Efficient Language-Guided Segmentation in Neural Radiance Fields
Jan 31, 2025



In this work, we propose a method that leverages CLIP feature distillation, achieving efficient 3D segmentation through language guidance. Unlike previous methods that rely on multi-scale CLIP features and are limited by processing speed and storage requirements, our approach aims to streamline the workflow by directly and effectively distilling dense CLIP features, thereby achieving precise segmentation of 3D scenes using text. To achieve this, we introduce an adapter module and mitigate the noise issue in the dense CLIP feature distillation process through a self-cross-training strategy. Moreover, to enhance the accuracy of segmentation edges, this work presents a low-rank transient query attention mechanism. To ensure the consistency of segmentation for similar colors under different viewpoints, we convert the segmentation task into a classification task through label volume, which significantly improves the consistency of segmentation in color-similar areas. We also propose a simplified text augmentation strategy to alleviate the issue of ambiguity in the correspondence between CLIP features and text. Extensive experimental results show that our method surpasses current state-of-the-art technologies in both training speed and performance. Our code is available on: https://github.com/xingy038/Laser.git.
Exemplar-condensed Federated Class-incremental Learning
Dec 25, 2024



We propose Exemplar-Condensed federated class-incremental learning (ECoral) to distil the training characteristics of real images from streaming data into informative rehearsal exemplars. The proposed method eliminates the limitations of exemplar selection in replay-based approaches for mitigating catastrophic forgetting in federated continual learning (FCL). The limitations particularly related to the heterogeneity of information density of each summarized data. Our approach maintains the consistency of training gradients and the relationship to past tasks for the summarized exemplars to represent the streaming data compared to the original images effectively. Additionally, our approach reduces the information-level heterogeneity of the summarized data by inter-client sharing of the disentanglement generative model. Extensive experiments show that our ECoral outperforms several state-of-the-art methods and can be seamlessly integrated with many existing approaches to enhance performance.
Dataset Distillation-based Hybrid Federated Learning on Non-IID Data
Sep 26, 2024In federated learning, the heterogeneity of client data has a great impact on the performance of model training. Many heterogeneity issues in this process are raised by non-independently and identically distributed (Non-IID) data. This study focuses on the issue of label distribution skew. To address it, we propose a hybrid federated learning framework called HFLDD, which integrates dataset distillation to generate approximately independent and equally distributed (IID) data, thereby improving the performance of model training. Particularly, we partition the clients into heterogeneous clusters, where the data labels among different clients within a cluster are unbalanced while the data labels among different clusters are balanced. The cluster headers collect distilled data from the corresponding cluster members, and conduct model training in collaboration with the server. This training process is like traditional federated learning on IID data, and hence effectively alleviates the impact of Non-IID data on model training. Furthermore, we compare our proposed method with typical baseline methods on public datasets. Experimental results demonstrate that when the data labels are severely imbalanced, the proposed HFLDD outperforms the baseline methods in terms of both test accuracy and communication cost.
ExactDreamer: High-Fidelity Text-to-3D Content Creation via Exact Score Matching
May 24, 2024



Text-to-3D content creation is a rapidly evolving research area. Given the scarcity of 3D data, current approaches often adapt pre-trained 2D diffusion models for 3D synthesis. Among these approaches, Score Distillation Sampling (SDS) has been widely adopted. However, the issue of over-smoothing poses a significant limitation on the high-fidelity generation of 3D models. To address this challenge, LucidDreamer replaces the Denoising Diffusion Probabilistic Model (DDPM) in SDS with the Denoising Diffusion Implicit Model (DDIM) to construct Interval Score Matching (ISM). However, ISM inevitably inherits inconsistencies from DDIM, causing reconstruction errors during the DDIM inversion process. This results in poor performance in the detailed generation of 3D objects and loss of content. To alleviate these problems, we propose a novel method named Exact Score Matching (ESM). Specifically, ESM leverages auxiliary variables to mathematically guarantee exact recovery in the DDIM reverse process. Furthermore, to effectively capture the dynamic changes of the original and auxiliary variables, the LoRA of a pre-trained diffusion model implements these exact paths. Extensive experiments demonstrate the effectiveness of ESM in text-to-3D generation, particularly highlighting its superiority in detailed generation.
Rehearsal-free Federated Domain-incremental Learning
May 22, 2024



We introduce a rehearsal-free federated domain incremental learning framework, RefFiL, based on a global prompt-sharing paradigm to alleviate catastrophic forgetting challenges in federated domain-incremental learning, where unseen domains are continually learned. Typical methods for mitigating forgetting, such as the use of additional datasets and the retention of private data from earlier tasks, are not viable in federated learning (FL) due to devices' limited resources. Our method, RefFiL, addresses this by learning domain-invariant knowledge and incorporating various domain-specific prompts from the domains represented by different FL participants. A key feature of RefFiL is the generation of local fine-grained prompts by our domain adaptive prompt generator, which effectively learns from local domain knowledge while maintaining distinctive boundaries on a global scale. We also introduce a domain-specific prompt contrastive learning loss that differentiates between locally generated prompts and those from other domains, enhancing RefFiL's precision and effectiveness. Compared to existing methods, RefFiL significantly alleviates catastrophic forgetting without requiring extra memory space, making it ideal for privacy-sensitive and resource-constrained devices.
Dreamer XL: Towards High-Resolution Text-to-3D Generation via Trajectory Score Matching
May 18, 2024In this work, we propose a novel Trajectory Score Matching (TSM) method that aims to solve the pseudo ground truth inconsistency problem caused by the accumulated error in Interval Score Matching (ISM) when using the Denoising Diffusion Implicit Models (DDIM) inversion process. Unlike ISM which adopts the inversion process of DDIM to calculate on a single path, our TSM method leverages the inversion process of DDIM to generate two paths from the same starting point for calculation. Since both paths start from the same starting point, TSM can reduce the accumulated error compared to ISM, thus alleviating the problem of pseudo ground truth inconsistency. TSM enhances the stability and consistency of the model's generated paths during the distillation process. We demonstrate this experimentally and further show that ISM is a special case of TSM. Furthermore, to optimize the current multi-stage optimization process from high-resolution text to 3D generation, we adopt Stable Diffusion XL for guidance. In response to the issues of abnormal replication and splitting caused by unstable gradients during the 3D Gaussian splatting process when using Stable Diffusion XL, we propose a pixel-by-pixel gradient clipping method. Extensive experiments show that our model significantly surpasses the state-of-the-art models in terms of visual quality and performance. Code: \url{https://github.com/xingy038/Dreamer-XL}.
From Sora What We Can See: A Survey of Text-to-Video Generation
May 17, 2024
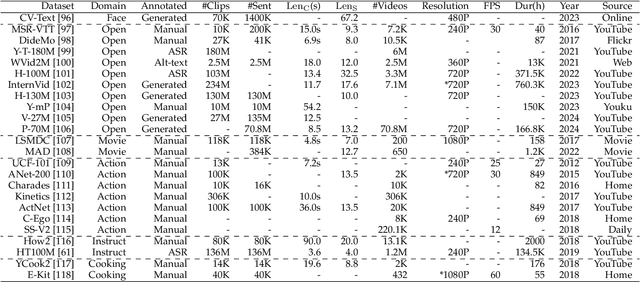
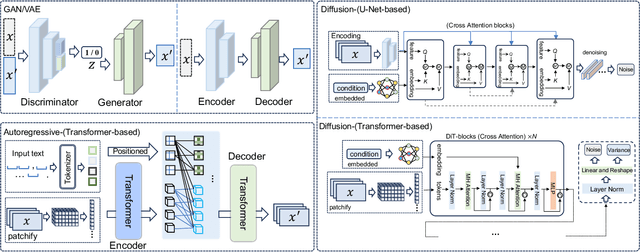

With impressive achievements made, artificial intelligence is on the path forward to artificial general intelligence. Sora, developed by OpenAI, which is capable of minute-level world-simulative abilities can be considered as a milestone on this developmental path. However, despite its notable successes, Sora still encounters various obstacles that need to be resolved. In this survey, we embark from the perspective of disassembling Sora in text-to-video generation, and conducting a comprehensive review of literature, trying to answer the question, \textit{From Sora What We Can See}. Specifically, after basic preliminaries regarding the general algorithms are introduced, the literature is categorized from three mutually perpendicular dimensions: evolutionary generators, excellent pursuit, and realistic panorama. Subsequently, the widely used datasets and metrics are organized in detail. Last but more importantly, we identify several challenges and open problems in this domain and propose potential future directions for research and development.