 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Circular Construction Product Ontology for End-of-Life Decision-Making
Mar 17, 2025Efficient management of end-of-life (EoL) products is critical for advancing circularity in supply chains, particularly within the construction industry where EoL strategies are hindered by heterogenous lifecycle data and data silos. Current tools like Environmental Product Declarations (EPDs) and Digital Product Passports (DPPs) are limited by their dependency on seamless data integration and interoperability which remain significant challenges. To address these, we present the Circular Construction Product Ontology (CCPO), an applied framework designed to overcome semantic and data heterogeneity challenges in EoL decision-making for construction products. CCPO standardises vocabulary and facilitates data integration across supply chain stakeholders enabling lifecycle assessments (LCA) and robust decision-making. By aggregating disparate data into a unified product provenance, CCPO enables automated EoL recommendations through customisable SWRL rules aligned with European standards and stakeholder-specific circularity SLAs, demonstrating its scalability and integration capabilities. The adopted circular product scenario depicts CCPO's application while competency question evaluations show its superior performance in generating accurate EoL suggestions highlighting its potential to greatly improve decision-making in circular supply chains and its applicability in real-world construction environments.
Towards Enhancing Linked Data Retrieval in Conversational UIs using Large Language Models
Sep 24, 2024



Despite the recent broad adoption of Large Language Models (LLMs) across various domains, their potential for enriching information systems in extracting and exploring Linked Data (LD) and Resource Description Framework (RDF) triplestores has not been extensively explored. This paper examines the integration of LLMs within existing systems, emphasising the enhancement of conversational user interfaces (UIs) and their capabilities for data extraction by producing more accurate SPARQL queries without the requirement for model retraining. Typically, conversational UI models necessitate retraining with the introduction of new datasets or updates, limiting their functionality as general-purpose extraction tools. Our approach addresses this limitation by incorporating LLMs into the conversational UI workflow, significantly enhancing their ability to comprehend and process user queries effectively. By leveraging the advanced natural language understanding capabilities of LLMs, our method improves RDF entity extraction within web systems employing conventional chatbots. This integration facilitates a more nuanced and context-aware interaction model, critical for handling the complex query patterns often encountered in RDF datasets and Linked Open Data (LOD) endpoints. The evaluation of this methodology shows a marked enhancement in system expressivity and the accuracy of responses to user queries, indicating a promising direction for future research in this area. This investigation not only underscores the versatility of LLMs in enhancing existing information systems but also sets the stage for further explorations into their potential applications within more specialised domains of web information systems.
Feasibility on Detecting Door Slamming towards Monitoring Early Signs of Domestic Violence
Oct 06, 2022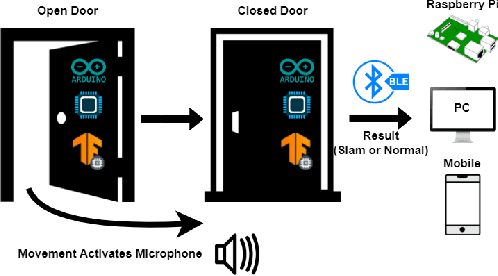

By using low-cost microcontrollers and TinyML, we investigate the feasibility of detecting potential early warning signs of domestic violence and other anti-social behaviors within the home. We created a machine learning model to determine if a door was closed aggressively by analyzing audio data and feeding this into a convolutional neural network to classify the sample. Under test conditions, with no background noise, accuracy of 88.89\% was achieved, declining to 87.50\% when assorted background noises were mixed in at a relative volume of 0.5 times that of the sample. The model is then deployed on an Arduino Nano BLE 33 Sense attached to the door, and only begins sampling once an acceleration greater than a predefined threshold acceleration is detected. The predictions made by the model can then be sent via BLE to another device, such as a smartphone of Raspberry Pi.
ForestQB: An Adaptive Query Builder to Support Wildlife Research
Oct 06, 2022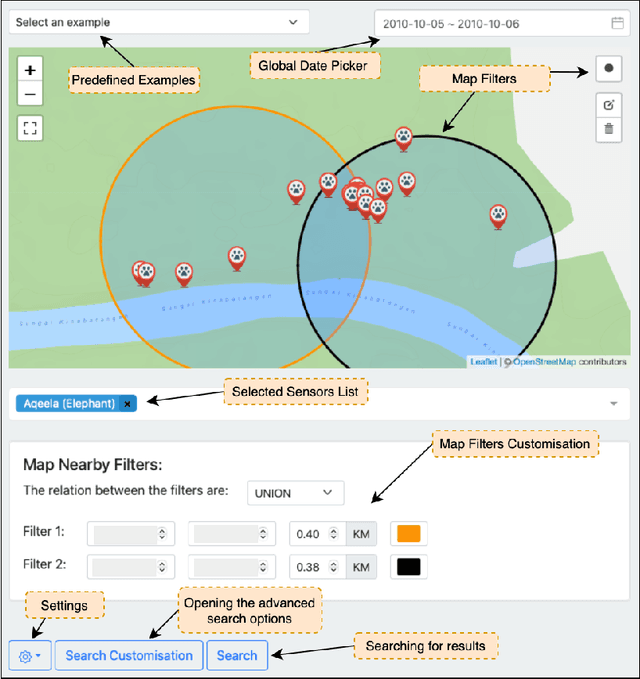
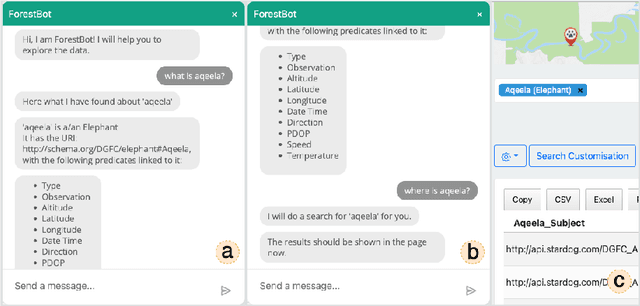
This paper presents ForestQB, a SPARQL query builder, to assist Bioscience and Wildlife Researchers in accessing Linked-Data. As they are unfamiliar with the Semantic Web and the data ontologies, ForestQB aims to empower them to benefit from using Linked-Data to extract valuable information without having to grasp the nature of the data and its underlying technologies. ForestQB is integrating Form-Based Query builders with Natural Language to simplify query construction to match the user requirements. Demo available at https://iotgarage.net/demo/forestQB
Detecting Anomalies within Smart Buildings using Do-It-Yourself Internet of Things
Oct 04, 2022Detecting anomalies at the time of happening is vital in environments like buildings and homes to identify potential cyber-attacks. This paper discussed the various mechanisms to detect anomalies as soon as they occur. We shed light on crucial considerations when building machine learning models. We constructed and gathered data from multiple self-build (DIY) IoT devices with different in-situ sensors and found effective ways to find the point, contextual and combine anomalies. We also discussed several challenges and potential solutions when dealing with sensing devices that produce data at different sampling rates and how we need to pre-process them in machine learning models. This paper also looks at the pros and cons of extracting sub-datasets based on environmental conditions.
* Journal of Ambient Intelligence and Humanized Computing (2022)
A Unified Knowledge Representation and Context-aware Recommender System in Internet of Things
May 24, 2018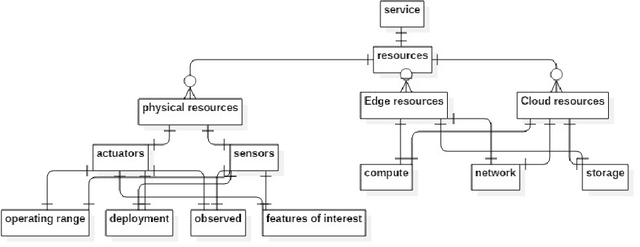
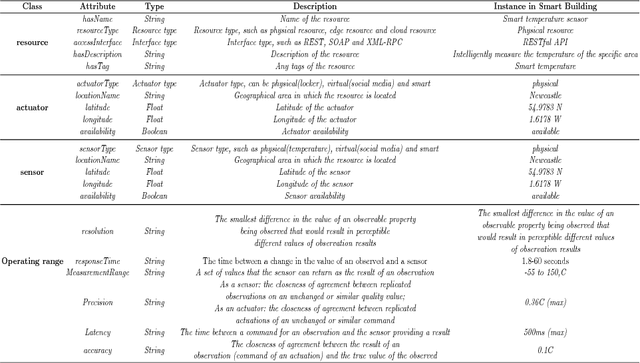
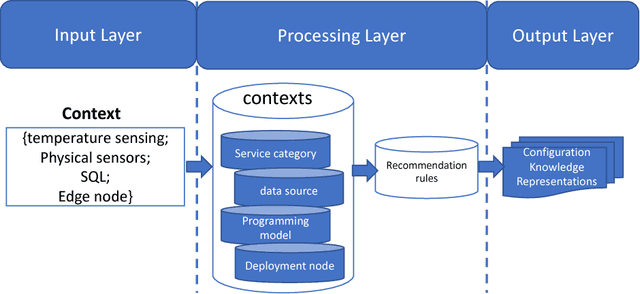
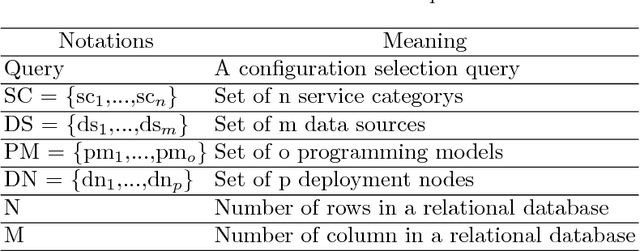
Within the rapidly developing Internet of Things (IoT), numerous and diverse physical devices, Edge devices, Cloud infrastructure, and their quality of service requirements (QoS), need to be represented within a unified specification in order to enable rapid IoT application development, monitoring, and dynamic reconfiguration. But heterogeneities among different configuration knowledge representation models pose limitations for acquisition, discovery and curation of configuration knowledge for coordinated IoT applications. This paper proposes a unified data model to represent IoT resource configuration knowledge artifacts. It also proposes IoT-CANE (Context-Aware recommendatioN systEm) to facilitate incremental knowledge acquisition and declarative context driven knowledge recommendation.
The Effects of Relative Importance of User Constraints in Cloud of Things Resource Discovery: A Case Study
Nov 16, 2016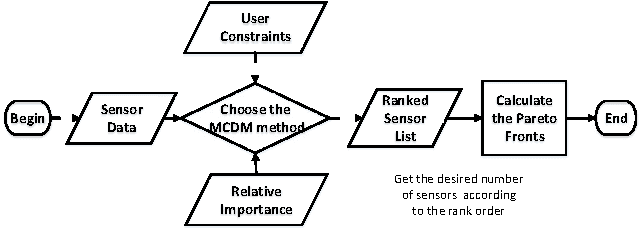


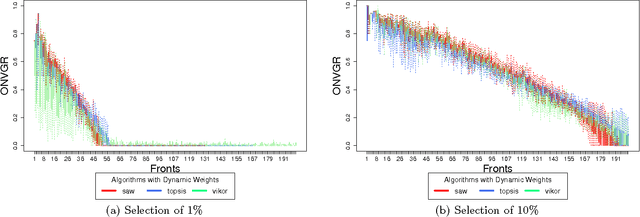
Over the last few years, the number of smart objects connected to the Internet has grown exponentially in comparison to the number of services and applications. The integration between Cloud Computing and Internet of Things, named as Cloud of Things, plays a key role in managing the connected things, their data and services. One of the main challenges in Cloud of Things is the resource discovery of the smart objects and their reuse in different contexts. Most of the existent work uses some kind of multi-criteria decision analysis algorithm to perform the resource discovery, but do not evaluate the impact that the user constraints has in the final solution. In this paper, we analyse the behaviour of the SAW, TOPSIS and VIKOR multi-objective decision analyses algorithms and the impact of user constraints on them. We evaluated the quality of the proposed solutions using the Pareto-optimality concept.
* Proceedings of the 9th IEEE/ACM International Conference on Utility and Cloud Computing (UCC 2016) Shaghai, China, December, 2016