 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Learning-Based Intrusion Detection Systems for In-Vehicle Network
May 15, 2025Connected and Autonomous Vehicles (CAVs) enhance mobility but face cybersecurity threats, particularly through the insecure Controller Area Network (CAN) bus. Cyberattacks can have devastating consequences in connected vehicles, including the loss of control over critical systems, necessitating robust security solutions. In-vehicle Intrusion Detection Systems (IDSs) offer a promising approach by detecting malicious activities in real time. This survey provides a comprehensive review of state-of-the-art research on learning-based in-vehicle IDSs, focusing on Machine Learning (ML), Deep Learning (DL), and Federated Learning (FL) approaches. Based on the reviewed studies, we critically examine existing IDS approaches, categorising them by the types of attacks they detect - known, unknown, and combined known-unknown attacks - while identifying their limitations. We also review the evaluation metrics used in research, emphasising the need to consider multiple criteria to meet the requirements of safety-critical systems. Additionally, we analyse FL-based IDSs and highlight their limitations. By doing so, this survey helps identify effective security measures, address existing limitations, and guide future research toward more resilient and adaptive protection mechanisms, ensuring the safety and reliability of CAVs.
A Circular Construction Product Ontology for End-of-Life Decision-Making
Mar 17, 2025Efficient management of end-of-life (EoL) products is critical for advancing circularity in supply chains, particularly within the construction industry where EoL strategies are hindered by heterogenous lifecycle data and data silos. Current tools like Environmental Product Declarations (EPDs) and Digital Product Passports (DPPs) are limited by their dependency on seamless data integration and interoperability which remain significant challenges. To address these, we present the Circular Construction Product Ontology (CCPO), an applied framework designed to overcome semantic and data heterogeneity challenges in EoL decision-making for construction products. CCPO standardises vocabulary and facilitates data integration across supply chain stakeholders enabling lifecycle assessments (LCA) and robust decision-making. By aggregating disparate data into a unified product provenance, CCPO enables automated EoL recommendations through customisable SWRL rules aligned with European standards and stakeholder-specific circularity SLAs, demonstrating its scalability and integration capabilities. The adopted circular product scenario depicts CCPO's application while competency question evaluations show its superior performance in generating accurate EoL suggestions highlighting its potential to greatly improve decision-making in circular supply chains and its applicability in real-world construction environments.
Gotham Dataset 2025: A Reproducible Large-Scale IoT Network Dataset for Intrusion Detection and Security Research
Feb 05, 2025In this paper, a dataset of IoT network traffic is presented. Our dataset was generated by utilising the Gotham testbed, an emulated large-scale Internet of Things (IoT) network designed to provide a realistic and heterogeneous environment for network security research. The testbed includes 78 emulated IoT devices operating on various protocols, including MQTT, CoAP, and RTSP. Network traffic was captured in Packet Capture (PCAP) format using tcpdump, and both benign and malicious traffic were recorded. Malicious traffic was generated through scripted attacks, covering a variety of attack types, such as Denial of Service (DoS), Telnet Brute Force, Network Scanning, CoAP Amplification, and various stages of Command and Control (C&C) communication. The data were subsequently processed in Python for feature extraction using the Tshark tool, and the resulting data was converted to Comma Separated Values (CSV) format and labelled. The data repository includes the raw network traffic in PCAP format and the processed labelled data in CSV format. Our dataset was collected in a distributed manner, where network traffic was captured separately for each IoT device at the interface between the IoT gateway and the device. Our dataset was collected in a distributed manner, where network traffic was separately captured for each IoT device at the interface between the IoT gateway and the device. With its diverse traffic patterns and attack scenarios, this dataset provides a valuable resource for developing Intrusion Detection Systems and security mechanisms tailored to complex, large-scale IoT environments. The dataset is publicly available at Zenodo.
Towards Enhancing Linked Data Retrieval in Conversational UIs using Large Language Models
Sep 24, 2024



Despite the recent broad adoption of Large Language Models (LLMs) across various domains, their potential for enriching information systems in extracting and exploring Linked Data (LD) and Resource Description Framework (RDF) triplestores has not been extensively explored. This paper examines the integration of LLMs within existing systems, emphasising the enhancement of conversational user interfaces (UIs) and their capabilities for data extraction by producing more accurate SPARQL queries without the requirement for model retraining. Typically, conversational UI models necessitate retraining with the introduction of new datasets or updates, limiting their functionality as general-purpose extraction tools. Our approach addresses this limitation by incorporating LLMs into the conversational UI workflow, significantly enhancing their ability to comprehend and process user queries effectively. By leveraging the advanced natural language understanding capabilities of LLMs, our method improves RDF entity extraction within web systems employing conventional chatbots. This integration facilitates a more nuanced and context-aware interaction model, critical for handling the complex query patterns often encountered in RDF datasets and Linked Open Data (LOD) endpoints. The evaluation of this methodology shows a marked enhancement in system expressivity and the accuracy of responses to user queries, indicating a promising direction for future research in this area. This investigation not only underscores the versatility of LLMs in enhancing existing information systems but also sets the stage for further explorations into their potential applications within more specialised domains of web information systems.
Hierarchical and Decentralised Federated Learning
Apr 28, 2023



Federated learning has shown enormous promise as a way of training ML models in distributed environments while reducing communication costs and protecting data privacy. However, the rise of complex cyber-physical systems, such as the Internet-of-Things, presents new challenges that are not met with traditional FL methods. Hierarchical Federated Learning extends the traditional FL process to enable more efficient model aggregation based on application needs or characteristics of the deployment environment (e.g., resource capabilities and/or network connectivity). It illustrates the benefits of balancing processing across the cloud-edge continuum. Hierarchical Federated Learning is likely to be a key enabler for a wide range of applications, such as smart farming and smart energy management, as it can improve performance and reduce costs, whilst also enabling FL workflows to be deployed in environments that are not well-suited to traditional FL. Model aggregation algorithms, software frameworks, and infrastructures will need to be designed and implemented to make such solutions accessible to researchers and engineers across a growing set of domains. H-FL also introduces a number of new challenges. For instance, there are implicit infrastructural challenges. There is also a trade-off between having generalised models and personalised models. If there exist geographical patterns for data (e.g., soil conditions in a smart farm likely are related to the geography of the region itself), then it is crucial that models used locally can consider their own locality in addition to a globally-learned model. H-FL will be crucial to future FL solutions as it can aggregate and distribute models at multiple levels to optimally serve the trade-off between locality dependence and global anomaly robustness.
ForestQB: An Adaptive Query Builder to Support Wildlife Research
Oct 06, 2022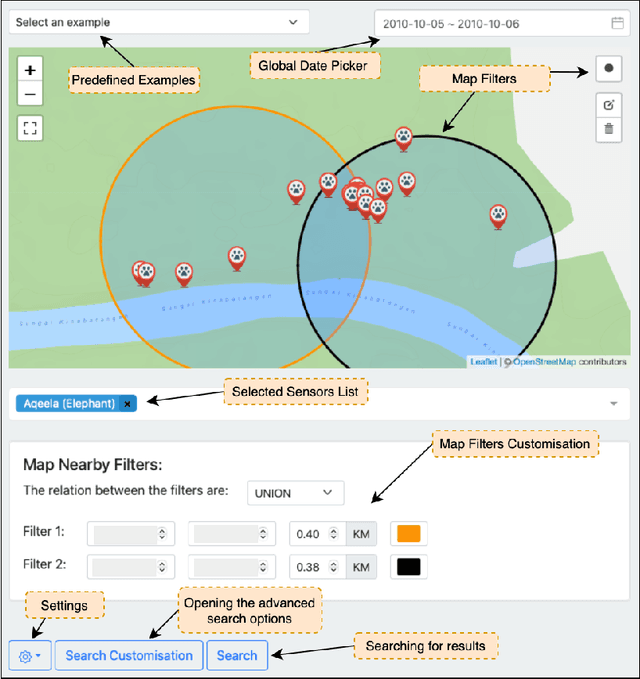
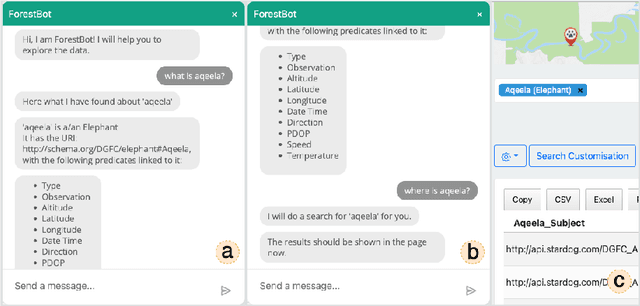
This paper presents ForestQB, a SPARQL query builder, to assist Bioscience and Wildlife Researchers in accessing Linked-Data. As they are unfamiliar with the Semantic Web and the data ontologies, ForestQB aims to empower them to benefit from using Linked-Data to extract valuable information without having to grasp the nature of the data and its underlying technologies. ForestQB is integrating Form-Based Query builders with Natural Language to simplify query construction to match the user requirements. Demo available at https://iotgarage.net/demo/forestQB
HUNTER: AI based Holistic Resource Management for Sustainable Cloud Computing
Oct 28, 2021
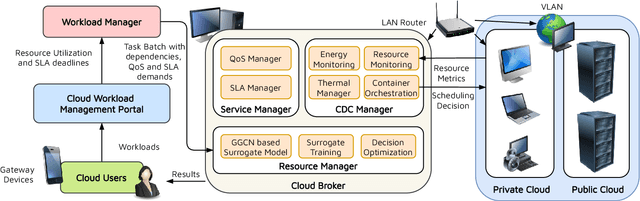
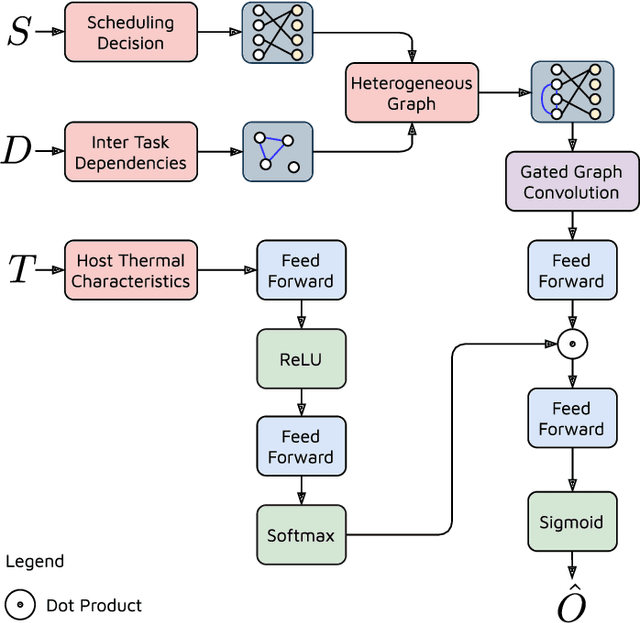
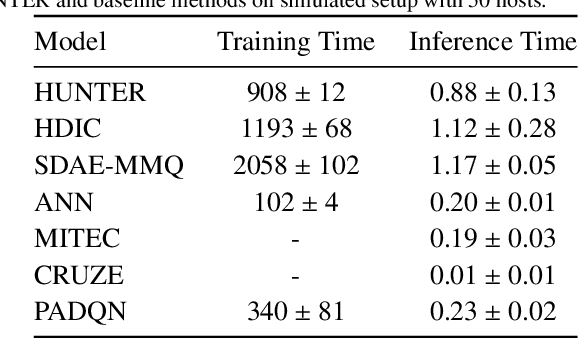
The worldwide adoption of cloud data centers (CDCs) has given rise to the ubiquitous demand for hosting application services on the cloud. Further, contemporary data-intensive industries have seen a sharp upsurge in the resource requirements of modern applications. This has led to the provisioning of an increased number of cloud servers, giving rise to higher energy consumption and, consequently, sustainability concerns. Traditional heuristics and reinforcement learning based algorithms for energy-efficient cloud resource management address the scalability and adaptability related challenges to a limited extent. Existing work often fails to capture dependencies across thermal characteristics of hosts, resource consumption of tasks and the corresponding scheduling decisions. This leads to poor scalability and an increase in the compute resource requirements, particularly in environments with non-stationary resource demands. To address these limitations, we propose an artificial intelligence (AI) based holistic resource management technique for sustainable cloud computing called HUNTER. The proposed model formulates the goal of optimizing energy efficiency in data centers as a multi-objective scheduling problem, considering three important models: energy, thermal and cooling. HUNTER utilizes a Gated Graph Convolution Network as a surrogate model for approximating the Quality of Service (QoS) for a system state and generating optimal scheduling decisions. Experiments on simulated and physical cloud environments using the CloudSim toolkit and the COSCO framework show that HUNTER outperforms state-of-the-art baselines in terms of energy consumption, SLA violation, scheduling time, cost and temperature by up to 12, 35, 43, 54 and 3 percent respectively.
Orchestrating Development Lifecycle of Machine Learning Based IoT Applications: A Survey
Oct 15, 2019
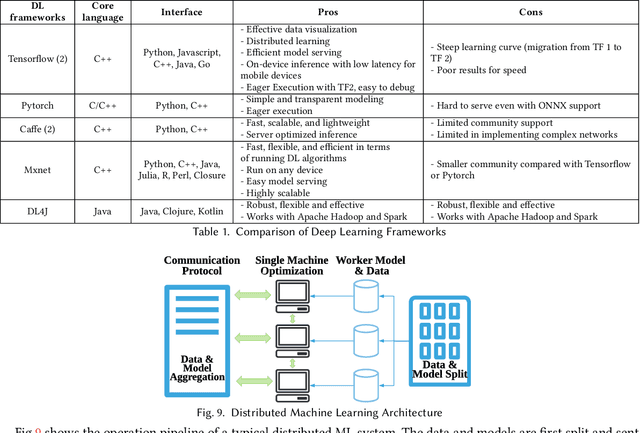
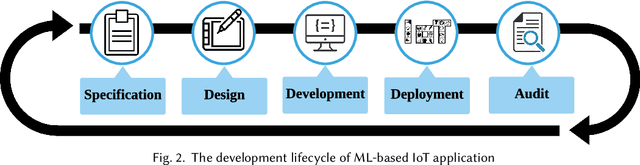

Machine Learning (ML) and Internet of Things (IoT) are complementary advances: ML techniques unlock complete potentials of IoT with intelligence, and IoT applications increasingly feed data collected by sensors into ML models, thereby employing results to improve their business processes and services. Hence, orchestrating ML pipelines that encompasses model training and implication involved in holistic development lifecycle of an IoT application often leads to complex system integration. This paper provides a comprehensive and systematic survey on the development lifecycle of ML-based IoT application. We outline core roadmap and taxonomy, and subsequently assess and compare existing standard techniques used in individual stage.
Predicting purchasing intent: Automatic Feature Learning using Recurrent Neural Networks
Jul 21, 2018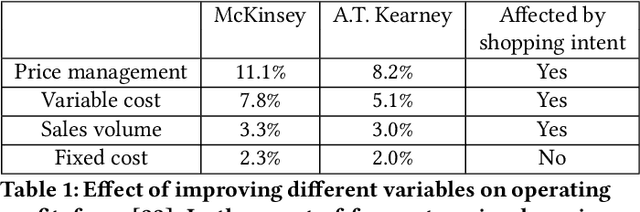
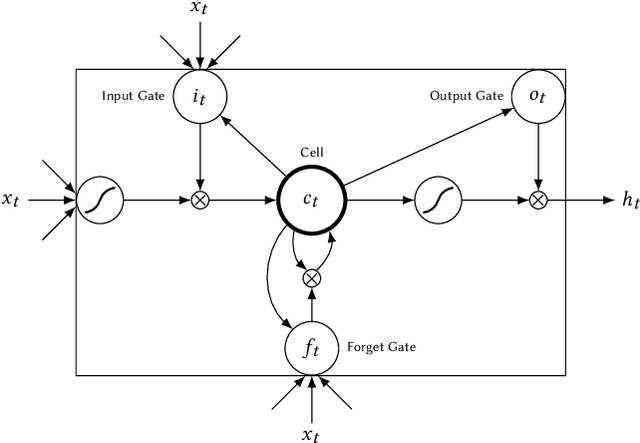
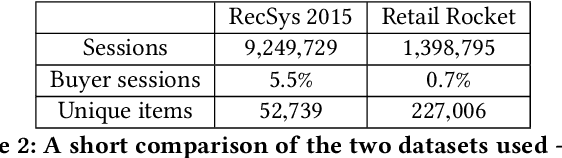
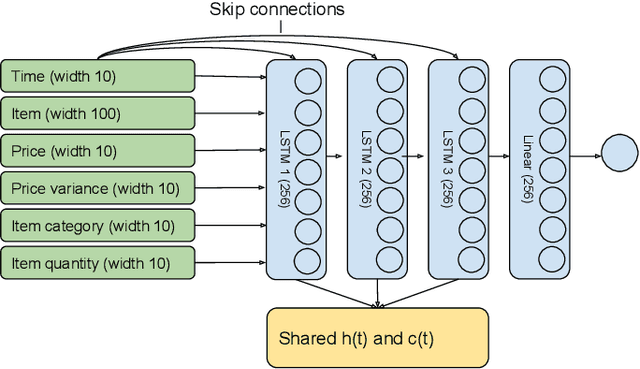
We present a neural network for predicting purchasing intent in an Ecommerce setting. Our main contribution is to address the significant investment in feature engineering that is usually associated with state-of-the-art methods such as Gradient Boosted Machines. We use trainable vector spaces to model varied, semi-structured input data comprising categoricals, quantities and unique instances. Multi-layer recurrent neural networks capture both session-local and dataset-global event dependencies and relationships for user sessions of any length. An exploration of model design decisions including parameter sharing and skip connections further increase model accuracy. Results on benchmark datasets deliver classification accuracy within 98% of state-of-the-art on one and exceed state-of-the-art on the second without the need for any domain / dataset-specific feature engineering on both short and long event sequences.