 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGotham Dataset 2025: A Reproducible Large-Scale IoT Network Dataset for Intrusion Detection and Security Research
Feb 05, 2025In this paper, a dataset of IoT network traffic is presented. Our dataset was generated by utilising the Gotham testbed, an emulated large-scale Internet of Things (IoT) network designed to provide a realistic and heterogeneous environment for network security research. The testbed includes 78 emulated IoT devices operating on various protocols, including MQTT, CoAP, and RTSP. Network traffic was captured in Packet Capture (PCAP) format using tcpdump, and both benign and malicious traffic were recorded. Malicious traffic was generated through scripted attacks, covering a variety of attack types, such as Denial of Service (DoS), Telnet Brute Force, Network Scanning, CoAP Amplification, and various stages of Command and Control (C&C) communication. The data were subsequently processed in Python for feature extraction using the Tshark tool, and the resulting data was converted to Comma Separated Values (CSV) format and labelled. The data repository includes the raw network traffic in PCAP format and the processed labelled data in CSV format. Our dataset was collected in a distributed manner, where network traffic was captured separately for each IoT device at the interface between the IoT gateway and the device. Our dataset was collected in a distributed manner, where network traffic was separately captured for each IoT device at the interface between the IoT gateway and the device. With its diverse traffic patterns and attack scenarios, this dataset provides a valuable resource for developing Intrusion Detection Systems and security mechanisms tailored to complex, large-scale IoT environments. The dataset is publicly available at Zenodo.
Using Harmonics for Low-Cost Jamming
Feb 21, 2024



The digitalisation of the modern schooling system has led to multiple schools and organisations buying similar hardware. Electronic equipment like wireless microphones, projectors, touchscreen displays etc., have been almost standardised with a few well-known brands leading the market. This has led to the adoption of common frequency ranges between brands with many sticking between 600-670 MHz. The popularity of low-cost computing devices like the Raspberry Pi which has been used in a plethora of applications has also taken the path of being used as low-cost transmitters. There have been many implementations where the Raspberry Pi has been used as the target device but few cases where the PI is the actual threat. In this paper, we explore the use of the Raspberry Pi as a stealth radio frequency jamming device to disable wireless conference microphones. Harmonics were used to achieve frequencies outside the Pi's transmission frequency by taking advantage of its unfiltered transmission.
Topic Modelling: Going Beyond Token Outputs
Jan 16, 2024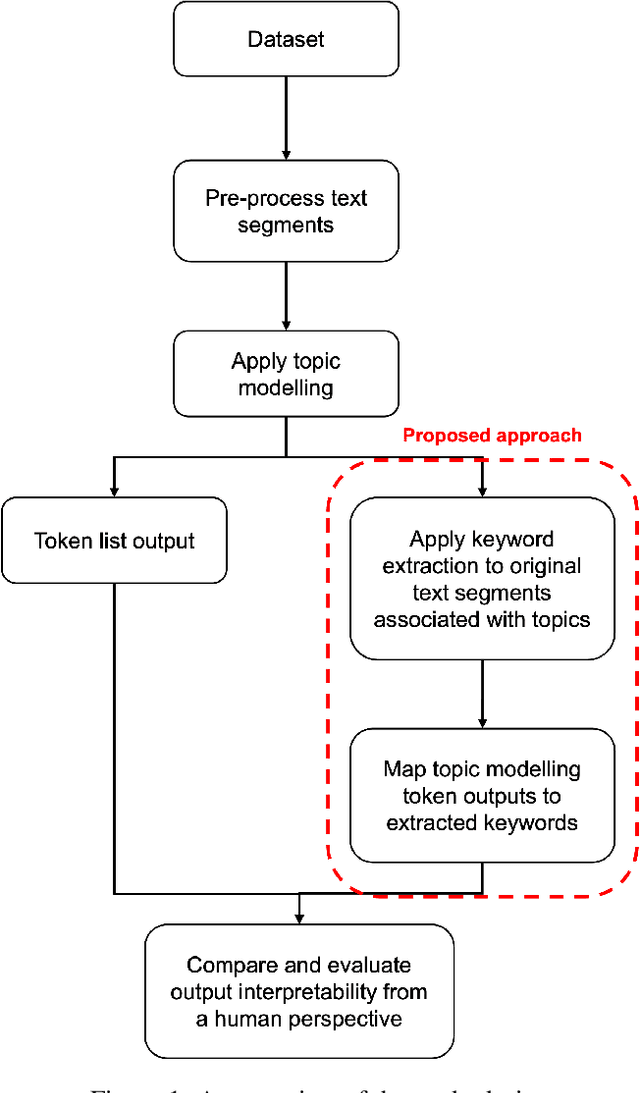
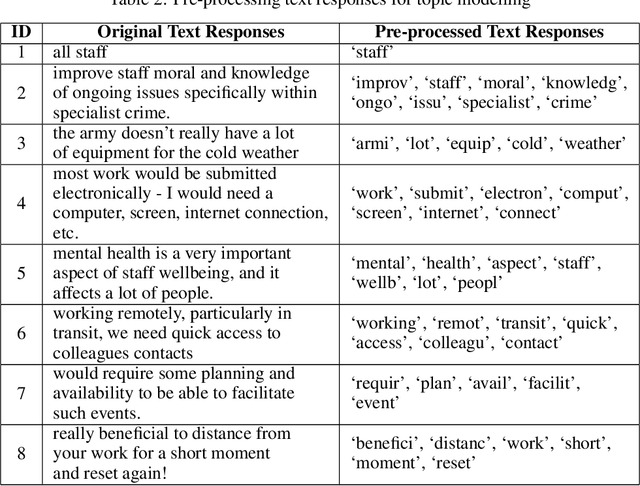

Topic modelling is a text mining technique for identifying salient themes from a number of documents. The output is commonly a set of topics consisting of isolated tokens that often co-occur in such documents. Manual effort is often associated with interpreting a topic's description from such tokens. However, from a human's perspective, such outputs may not adequately provide enough information to infer the meaning of the topics; thus, their interpretability is often inaccurately understood. Although several studies have attempted to automatically extend topic descriptions as a means of enhancing the interpretation of topic models, they rely on external language sources that may become unavailable, must be kept up-to-date to generate relevant results, and present privacy issues when training on or processing data. This paper presents a novel approach towards extending the output of traditional topic modelling methods beyond a list of isolated tokens. This approach removes the dependence on external sources by using the textual data itself by extracting high-scoring keywords and mapping them to the topic model's token outputs. To measure the interpretability of the proposed outputs against those of the traditional topic modelling approach, independent annotators manually scored each output based on their quality and usefulness, as well as the efficiency of the annotation task. The proposed approach demonstrated higher quality and usefulness, as well as higher efficiency in the annotation task, in comparison to the outputs of a traditional topic modelling method, demonstrating an increase in their interpretability.
Enhancing Enterprise Network Security: Comparing Machine-Level and Process-Level Analysis for Dynamic Malware Detection
Oct 27, 2023
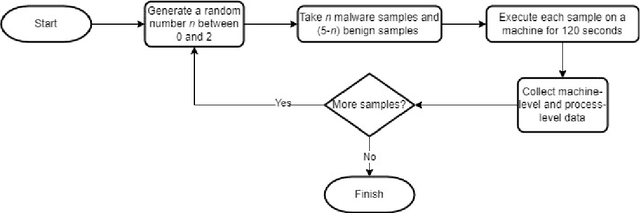
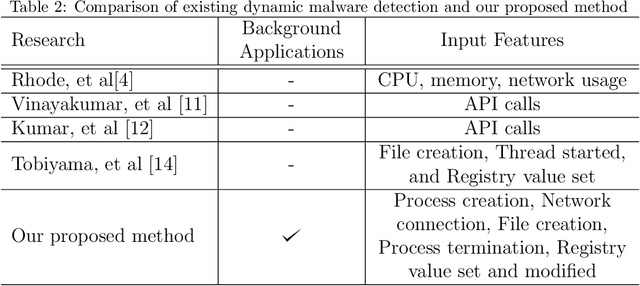
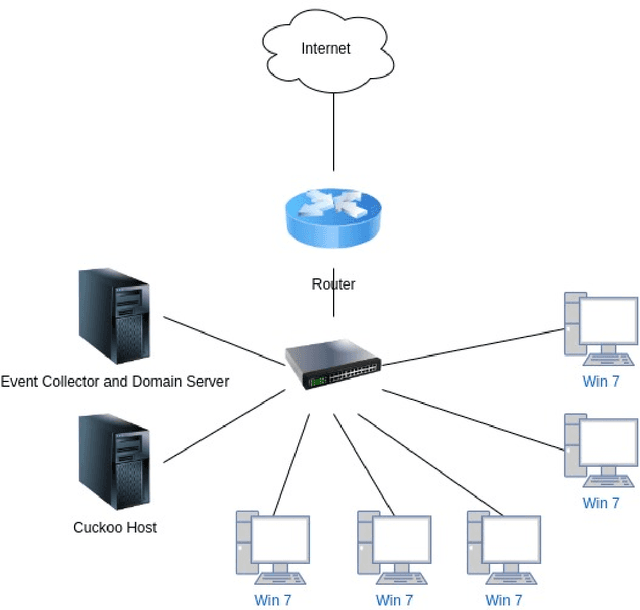
Analysing malware is important to understand how malicious software works and to develop appropriate detection and prevention methods. Dynamic analysis can overcome evasion techniques commonly used to bypass static analysis and provide insights into malware runtime activities. Much research on dynamic analysis focused on investigating machine-level information (e.g., CPU, memory, network usage) to identify whether a machine is running malicious activities. A malicious machine does not necessarily mean all running processes on the machine are also malicious. If we can isolate the malicious process instead of isolating the whole machine, we could kill the malicious process, and the machine can keep doing its job. Another challenge dynamic malware detection research faces is that the samples are executed in one machine without any background applications running. It is unrealistic as a computer typically runs many benign (background) applications when a malware incident happens. Our experiment with machine-level data shows that the existence of background applications decreases previous state-of-the-art accuracy by about 20.12% on average. We also proposed a process-level Recurrent Neural Network (RNN)-based detection model. Our proposed model performs better than the machine-level detection model; 0.049 increase in detection rate and a false-positive rate below 0.1.
Federated Deep Learning for Intrusion Detection in IoT Networks
Jun 07, 2023



The vast increase of IoT technologies and the ever-evolving attack vectors and threat actors have increased cyber-security risks dramatically. Novel attacks can compromise IoT devices to gain access to sensitive data or control them to deploy further malicious activities. The detection of novel attacks often relies upon AI solutions. A common approach to implementing AI-based IDS in distributed IoT systems is in a centralised manner. However, this approach may violate data privacy and secrecy. In addition, centralised data collection prohibits the scale-up of IDSs. Therefore, intrusion detection solutions in IoT ecosystems need to move towards a decentralised direction. FL has attracted significant interest in recent years due to its ability to perform collaborative learning while preserving data confidentiality and locality. Nevertheless, most FL-based IDS for IoT systems are designed under unrealistic data distribution conditions. To that end, we design an experiment representative of the real world and evaluate the performance of two FL IDS implementations, one based on DNNs and another on our previous work on DBNs. For our experiments, we rely on TON-IoT, a realistic IoT network traffic dataset, associating each IP address with a single FL client. Additionally, we explore pre-training and investigate various aggregation methods to mitigate the impact of data heterogeneity. Lastly, we benchmark our approach against a centralised solution. The comparison shows that the heterogeneous nature of the data has a considerable negative impact on the model performance when trained in a distributed manner. However, in the case of a pre-trained initial global FL model, we demonstrate a performance improvement of over 20% (F1-score) when compared against a randomly initiated global model.
Design of a dynamic and self-adapting system, supported with artificial intelligence, machine learning and real-time intelligence for predictive cyber risk analytics
May 19, 2020
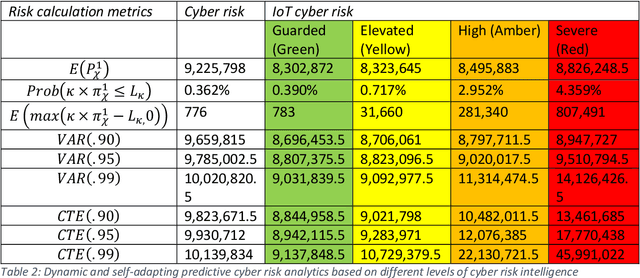
This paper surveys deep learning algorithms, IoT cyber security and risk models, and established mathematical formulas to identify the best approach for developing a dynamic and self-adapting system for predictive cyber risk analytics supported with Artificial Intelligence and Machine Learning and real-time intelligence in edge computing. The paper presents a new mathematical approach for integrating concepts for cognition engine design, edge computing and Artificial Intelligence and Machine Learning to automate anomaly detection. This engine instigates a step change by applying Artificial Intelligence and Machine Learning embedded at the edge of IoT networks, to deliver safe and functional real-time intelligence for predictive cyber risk analytics. This will enhance capacities for risk analytics and assists in the creation of a comprehensive and systematic understanding of the opportunities and threats that arise when edge computing nodes are deployed, and when Artificial Intelligence and Machine Learning technologies are migrated to the periphery of the internet and into local IoT networks.
Adversarial Attacks on Machine Learning Cybersecurity Defences in Industrial Control Systems
Apr 10, 2020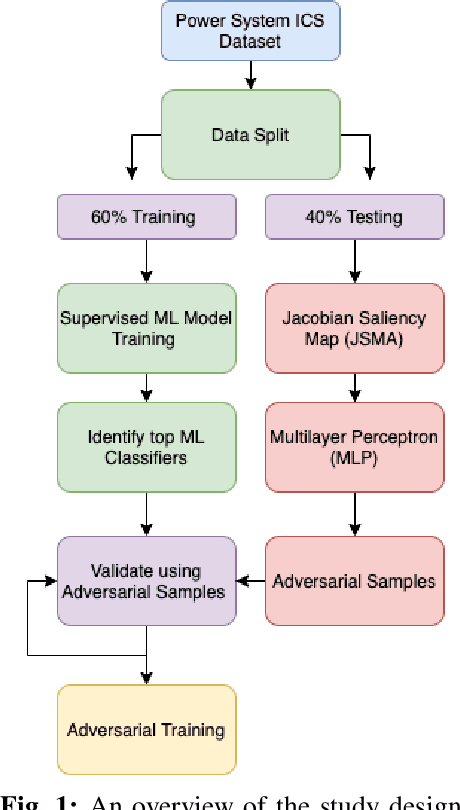
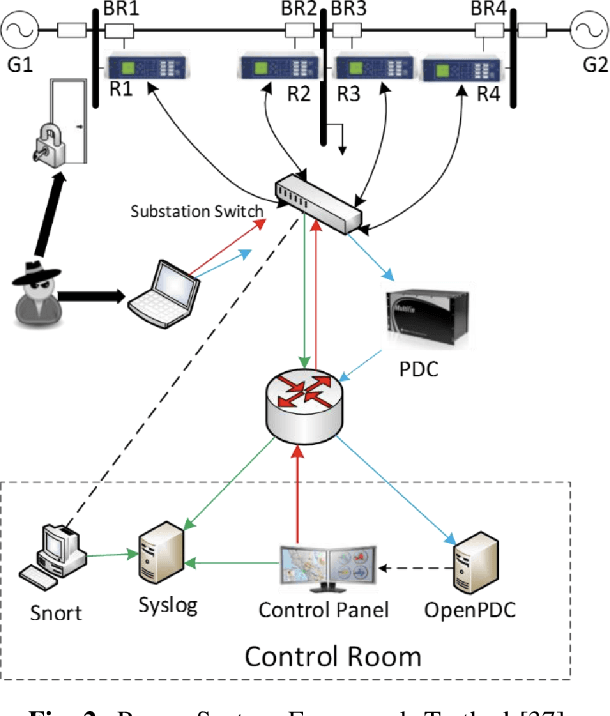
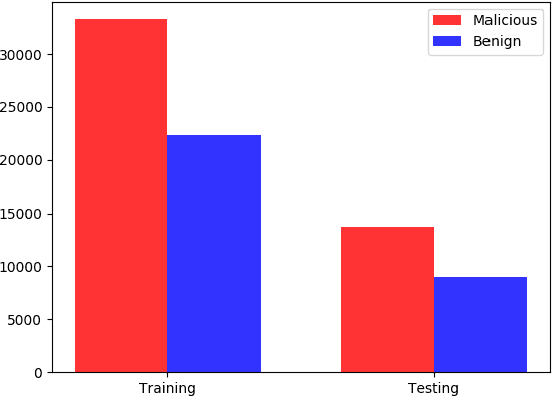
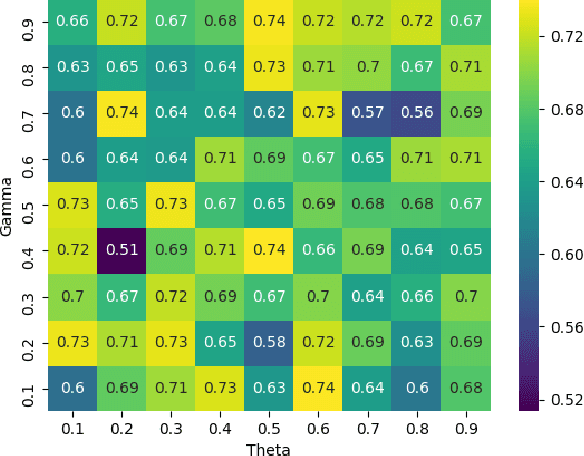
The proliferation and application of machine learning based Intrusion Detection Systems (IDS) have allowed for more flexibility and efficiency in the automated detection of cyber attacks in Industrial Control Systems (ICS). However, the introduction of such IDSs has also created an additional attack vector; the learning models may also be subject to cyber attacks, otherwise referred to as Adversarial Machine Learning (AML). Such attacks may have severe consequences in ICS systems, as adversaries could potentially bypass the IDS. This could lead to delayed attack detection which may result in infrastructure damages, financial loss, and even loss of life. This paper explores how adversarial learning can be used to target supervised models by generating adversarial samples using the Jacobian-based Saliency Map attack and exploring classification behaviours. The analysis also includes the exploration of how such samples can support the robustness of supervised models using adversarial training. An authentic power system dataset was used to support the experiments presented herein. Overall, the classification performance of two widely used classifiers, Random Forest and J48, decreased by 16 and 20 percentage points when adversarial samples were present. Their performances improved following adversarial training, demonstrating their robustness towards such attacks.