 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modelling: Going Beyond Token Outputs
Jan 16, 2024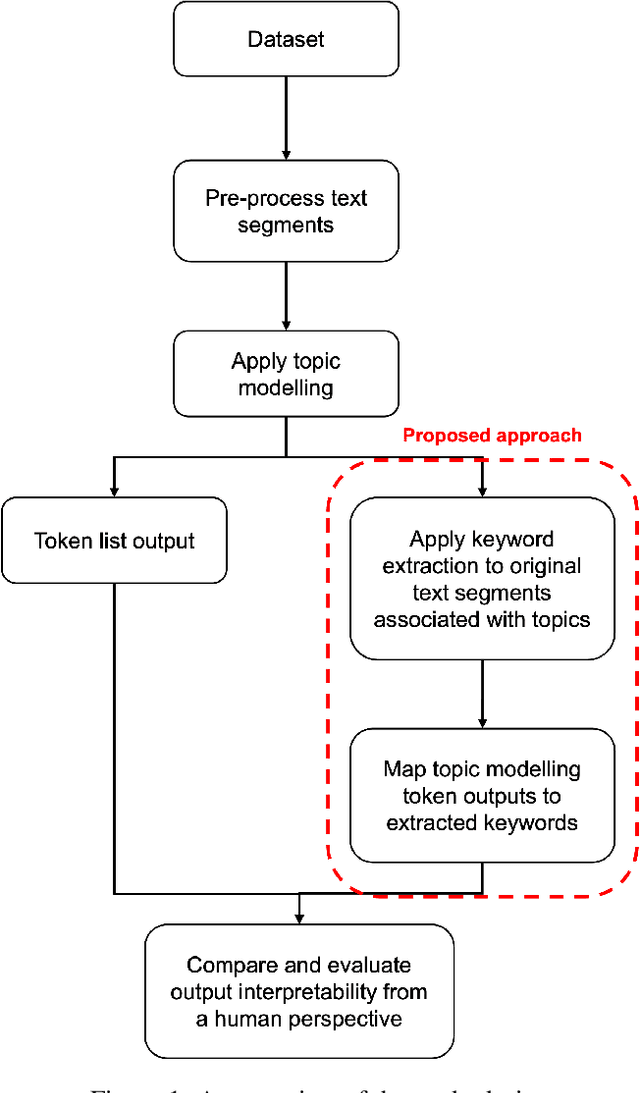
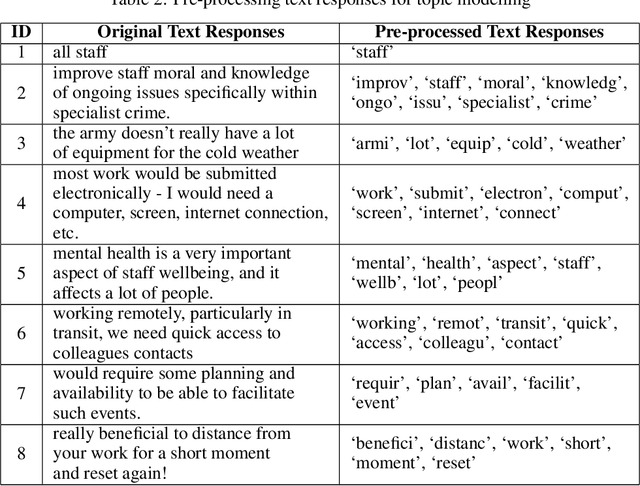

Topic modelling is a text mining technique for identifying salient themes from a number of documents. The output is commonly a set of topics consisting of isolated tokens that often co-occur in such documents. Manual effort is often associated with interpreting a topic's description from such tokens. However, from a human's perspective, such outputs may not adequately provide enough information to infer the meaning of the topics; thus, their interpretability is often inaccurately understood. Although several studies have attempted to automatically extend topic descriptions as a means of enhancing the interpretation of topic models, they rely on external language sources that may become unavailable, must be kept up-to-date to generate relevant results, and present privacy issues when training on or processing data. This paper presents a novel approach towards extending the output of traditional topic modelling methods beyond a list of isolated tokens. This approach removes the dependence on external sources by using the textual data itself by extracting high-scoring keywords and mapping them to the topic model's token outputs. To measure the interpretability of the proposed outputs against those of the traditional topic modelling approach, independent annotators manually scored each output based on their quality and usefulness, as well as the efficiency of the annotation task. The proposed approach demonstrated higher quality and usefulness, as well as higher efficiency in the annotation task, in comparison to the outputs of a traditional topic modelling method, demonstrating an increase in their interpretability.