 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modelling: Going Beyond Token Outputs
Jan 16, 2024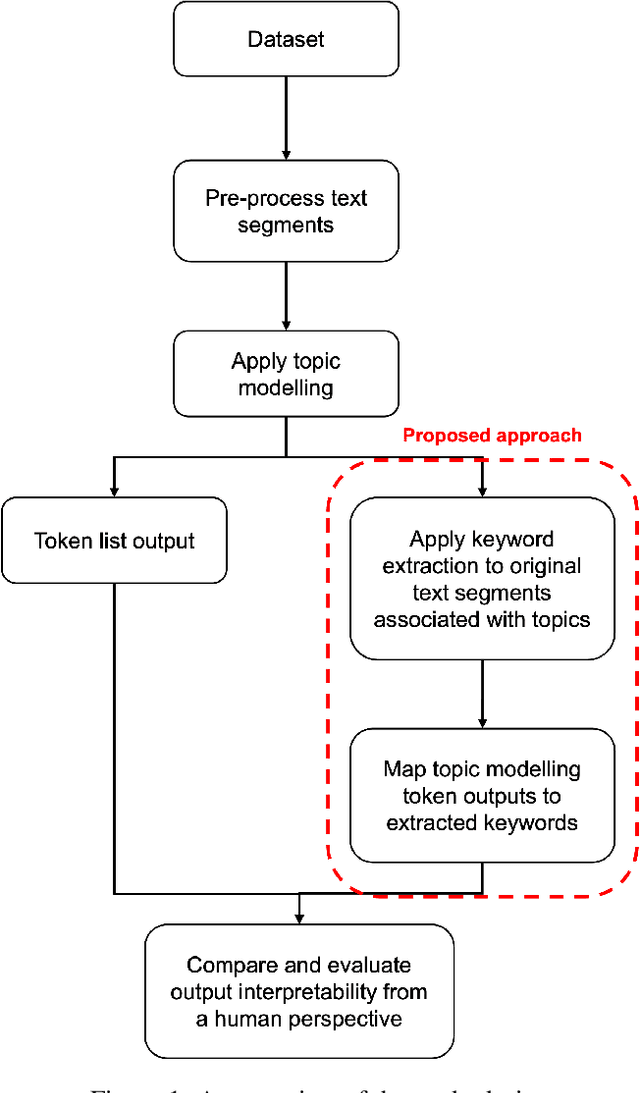
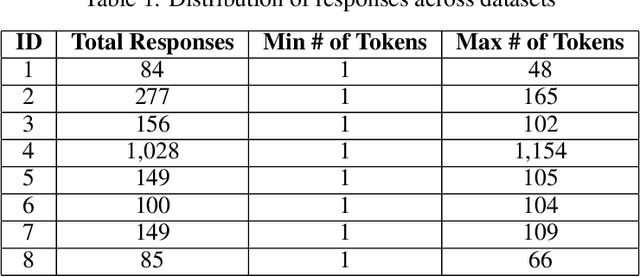
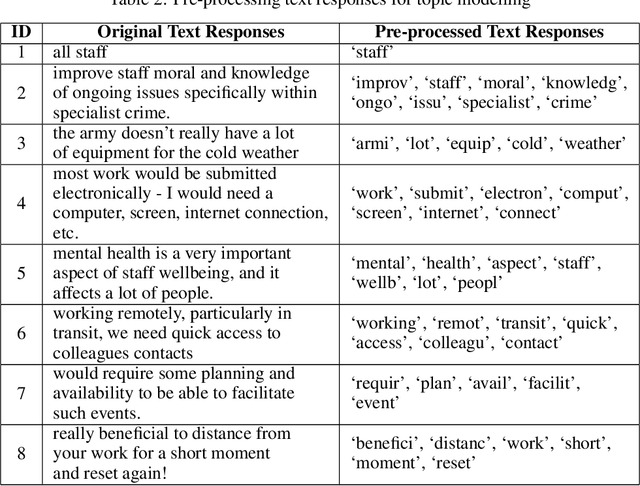

Topic modelling is a text mining technique for identifying salient themes from a number of documents. The output is commonly a set of topics consisting of isolated tokens that often co-occur in such documents. Manual effort is often associated with interpreting a topic's description from such tokens. However, from a human's perspective, such outputs may not adequately provide enough information to infer the meaning of the topics; thus, their interpretability is often inaccurately understood. Although several studies have attempted to automatically extend topic descriptions as a means of enhancing the interpretation of topic models, they rely on external language sources that may become unavailable, must be kept up-to-date to generate relevant results, and present privacy issues when training on or processing data. This paper presents a novel approach towards extending the output of traditional topic modelling methods beyond a list of isolated tokens. This approach removes the dependence on external sources by using the textual data itself by extracting high-scoring keywords and mapping them to the topic model's token outputs. To measure the interpretability of the proposed outputs against those of the traditional topic modelling approach, independent annotators manually scored each output based on their quality and usefulness, as well as the efficiency of the annotation task. The proposed approach demonstrated higher quality and usefulness, as well as higher efficiency in the annotation task, in comparison to the outputs of a traditional topic modelling method, demonstrating an increase in their interpretability.
Adversarial Attacks on Machine Learning Cybersecurity Defences in Industrial Control Systems
Apr 10, 2020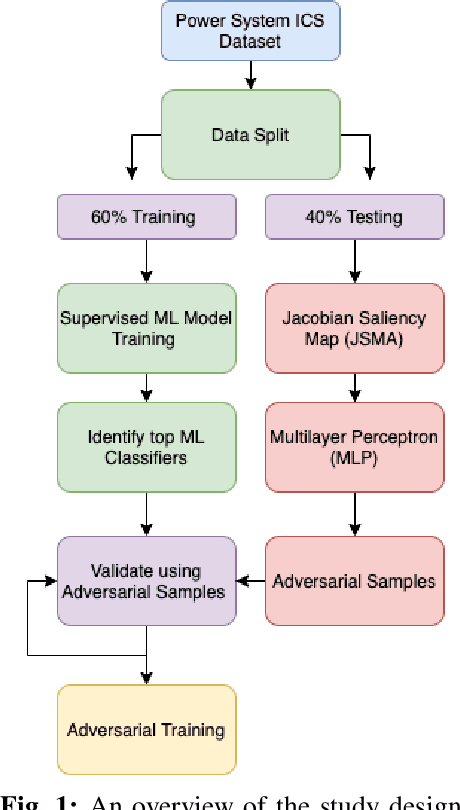
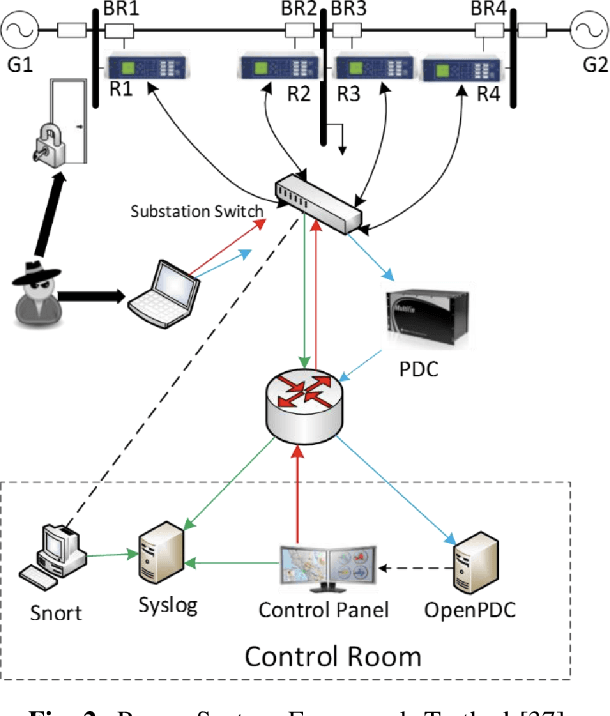
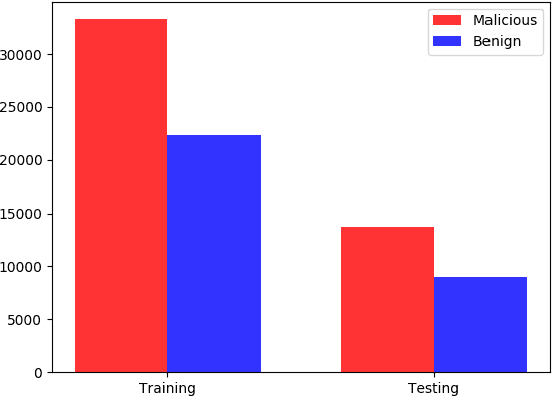
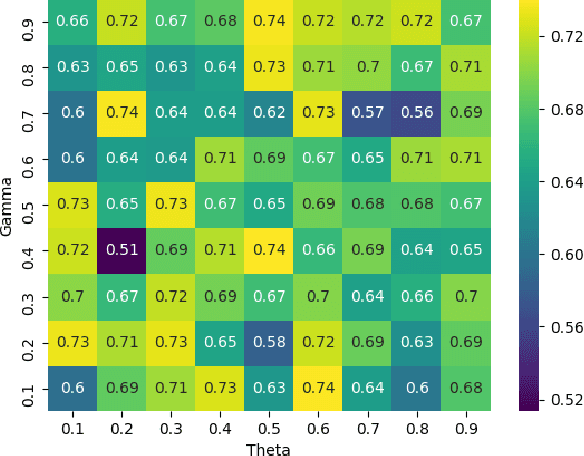
The proliferation and application of machine learning based Intrusion Detection Systems (IDS) have allowed for more flexibility and efficiency in the automated detection of cyber attacks in Industrial Control Systems (ICS). However, the introduction of such IDSs has also created an additional attack vector; the learning models may also be subject to cyber attacks, otherwise referred to as Adversarial Machine Learning (AML). Such attacks may have severe consequences in ICS systems, as adversaries could potentially bypass the IDS. This could lead to delayed attack detection which may result in infrastructure damages, financial loss, and even loss of life. This paper explores how adversarial learning can be used to target supervised models by generating adversarial samples using the Jacobian-based Saliency Map attack and exploring classification behaviours. The analysis also includes the exploration of how such samples can support the robustness of supervised models using adversarial training. An authentic power system dataset was used to support the experiments presented herein. Overall, the classification performance of two widely used classifiers, Random Forest and J48, decreased by 16 and 20 percentage points when adversarial samples were present. Their performances improved following adversarial training, demonstrating their robustness towards such attacks.