 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2R: dual regularization loss with collaborative adversarial generation for model robustness
Jun 08, 2025The robustness of Deep Neural Network models is crucial for defending models against adversarial attacks. Recent defense methods have employed collaborative learning frameworks to enhance model robustness. Two key limitations of existing methods are (i) insufficient guidance of the target model via loss functions and (ii) non-collaborative adversarial generation. We, therefore, propose a dual regularization loss (D2R Loss) method and a collaborative adversarial generation (CAG) strategy for adversarial training. D2R loss includes two optimization steps. The adversarial distribution and clean distribution optimizations enhance the target model's robustness by leveraging the strengths of different loss functions obtained via a suitable function space exploration to focus more precisely on the target model's distribution. CAG generates adversarial samples using a gradient-based collaboration between guidance and target models. We conducted extensive experiments on three benchmark databases, including CIFAR-10, CIFAR-100, Tiny ImageNet, and two popular target models, WideResNet34-10 and PreActResNet18. Our results show that D2R loss with CAG produces highly robust models.
Benchmarking of CPU-intensive Stream Data Processing in The Edge Computing Systems
May 12, 2025Edge computing has emerged as a pivotal technology, offering significant advantages such as low latency, enhanced data security, and reduced reliance on centralized cloud infrastructure. These benefits are crucial for applications requiring real-time data processing or strict security measures. Despite these advantages, edge devices operating within edge clusters are often underutilized. This inefficiency is mainly due to the absence of a holistic performance profiling mechanism which can help dynamically adjust the desired system configuration for a given workload. Since edge computing environments involve a complex interplay between CPU frequency, power consumption, and application performance, a deeper understanding of these correlations is essential. By uncovering these relationships, it becomes possible to make informed decisions that enhance both computational efficiency and energy savings. To address this gap, this paper evaluates the power consumption and performance characteristics of a single processing node within an edge cluster using a synthetic microbenchmark by varying the workload size and CPU frequency. The results show how an optimal measure can lead to optimized usage of edge resources, given both performance and power consumption.
D2Fusion: Dual-domain Fusion with Feature Superposition for Deepfake Detection
Mar 21, 2025Deepfake detection is crucial for curbing the harm it causes to society. However, current Deepfake detection methods fail to thoroughly explore artifact information across different domains due to insufficient intrinsic interactions. These interactions refer to the fusion and coordination after feature extraction processes across different domains, which are crucial for recognizing complex forgery clues. Focusing on more generalized Deepfake detection, in this work, we introduce a novel bi-directional attention module to capture the local positional information of artifact clues from the spatial domain. This enables accurate artifact localization, thus addressing the coarse processing with artifact features. To further address the limitation that the proposed bi-directional attention module may not well capture global subtle forgery information in the artifact feature (e.g., textures or edges), we employ a fine-grained frequency attention module in the frequency domain. By doing so, we can obtain high-frequency information in the fine-grained features, which contains the global and subtle forgery information. Although these features from the diverse domains can be effectively and independently improved, fusing them directly does not effectively improve the detection performance. Therefore, we propose a feature superposition strategy that complements information from spatial and frequency domains. This strategy turns the feature components into the form of wave-like tokens, which are updated based on their phase, such that the distinctions between authentic and artifact features can be amplified. Our method demonstrates significant improvements over state-of-the-art (SOTA) methods on five public Deepfake datasets in capturing abnormalities across different manipulated operations and real-life.
FedSCA: Federated Tuning with Similarity-guided Collaborative Aggregation for Heterogeneous Medical Image Segmentation
Mar 19, 2025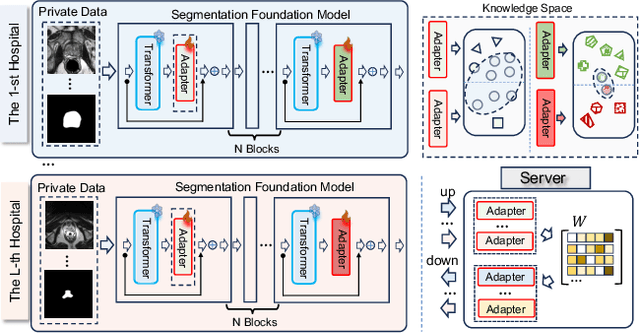
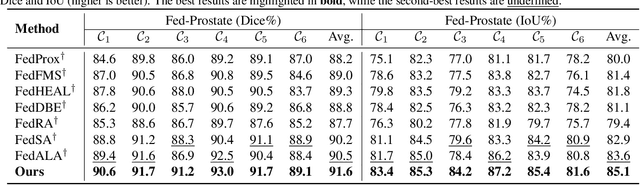
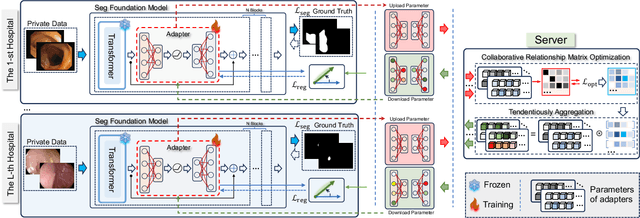
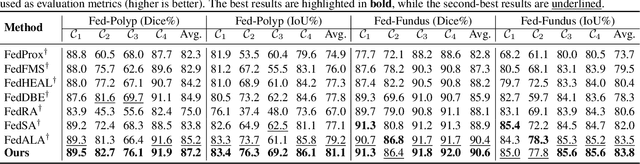
Transformer-based foundation models (FMs) have recently demonstrated remarkable performance in medical image segmentation. However, scaling these models is challenging due to the limited size of medical image datasets within isolated hospitals, where data centralization is restricted due to privacy concerns. These constraints, combined with the data-intensive nature of FMs, hinder their broader application. Integrating federated learning (FL) with foundation models (FLFM) fine-tuning offers a potential solution to these challenges by enabling collaborative model training without data sharing, thus allowing FMs to take advantage of a diverse pool of sensitive medical image data across hospitals/clients. However, non-independent and identically distributed (non-IID) data among clients, paired with computational and communication constraints in federated environments, presents an additional challenge that limits further performance improvements and remains inadequately addressed in existing studies. In this work, we propose a novel FLFM fine-tuning framework, \underline{\textbf{Fed}}erated tuning with \underline{\textbf{S}}imilarity-guided \underline{\textbf{C}}ollaborative \underline{\textbf{A}}ggregation (FedSCA), encompassing all phases of the FL process. This includes (1) specially designed parameter-efficient fine-tuning (PEFT) for local client training to enhance computational efficiency; (2) partial low-level adapter transmission for communication efficiency; and (3) similarity-guided collaborative aggregation (SGCA) on the server side to address non-IID issues. Extensive experiments on three FL benchmarks for medical image segmentation demonstrate the effectiveness of our proposed FedSCA, establishing new SOTA performance.
A Circular Construction Product Ontology for End-of-Life Decision-Making
Mar 17, 2025Efficient management of end-of-life (EoL) products is critical for advancing circularity in supply chains, particularly within the construction industry where EoL strategies are hindered by heterogenous lifecycle data and data silos. Current tools like Environmental Product Declarations (EPDs) and Digital Product Passports (DPPs) are limited by their dependency on seamless data integration and interoperability which remain significant challenges. To address these, we present the Circular Construction Product Ontology (CCPO), an applied framework designed to overcome semantic and data heterogeneity challenges in EoL decision-making for construction products. CCPO standardises vocabulary and facilitates data integration across supply chain stakeholders enabling lifecycle assessments (LCA) and robust decision-making. By aggregating disparate data into a unified product provenance, CCPO enables automated EoL recommendations through customisable SWRL rules aligned with European standards and stakeholder-specific circularity SLAs, demonstrating its scalability and integration capabilities. The adopted circular product scenario depicts CCPO's application while competency question evaluations show its superior performance in generating accurate EoL suggestions highlighting its potential to greatly improve decision-making in circular supply chains and its applicability in real-world construction environments.
Laser: Efficient Language-Guided Segmentation in Neural Radiance Fields
Jan 31, 2025



In this work, we propose a method that leverages CLIP feature distillation, achieving efficient 3D segmentation through language guidance. Unlike previous methods that rely on multi-scale CLIP features and are limited by processing speed and storage requirements, our approach aims to streamline the workflow by directly and effectively distilling dense CLIP features, thereby achieving precise segmentation of 3D scenes using text. To achieve this, we introduce an adapter module and mitigate the noise issue in the dense CLIP feature distillation process through a self-cross-training strategy. Moreover, to enhance the accuracy of segmentation edges, this work presents a low-rank transient query attention mechanism. To ensure the consistency of segmentation for similar colors under different viewpoints, we convert the segmentation task into a classification task through label volume, which significantly improves the consistency of segmentation in color-similar areas. We also propose a simplified text augmentation strategy to alleviate the issue of ambiguity in the correspondence between CLIP features and text. Extensive experimental results show that our method surpasses current state-of-the-art technologies in both training speed and performance. Our code is available on: https://github.com/xingy038/Laser.git.
Exemplar-condensed Federated Class-incremental Learning
Dec 25, 2024



We propose Exemplar-Condensed federated class-incremental learning (ECoral) to distil the training characteristics of real images from streaming data into informative rehearsal exemplars. The proposed method eliminates the limitations of exemplar selection in replay-based approaches for mitigating catastrophic forgetting in federated continual learning (FCL). The limitations particularly related to the heterogeneity of information density of each summarized data. Our approach maintains the consistency of training gradients and the relationship to past tasks for the summarized exemplars to represent the streaming data compared to the original images effectively. Additionally, our approach reduces the information-level heterogeneity of the summarized data by inter-client sharing of the disentanglement generative model. Extensive experiments show that our ECoral outperforms several state-of-the-art methods and can be seamlessly integrated with many existing approaches to enhance performance.
Evaluating Sugarcane Yield Variability with UAV-Derived Cane Height under Different Water and Nitrogen Conditions
Oct 28, 2024This study investigates the relationship between sugarcane yield and cane height derived under different water and nitrogen conditions from pre-harvest Digital Surface Model (DSM) obtained via Unmanned Aerial Vehicle (UAV) flights over a sugarcane test farm. The farm was divided into 62 blocks based on three water levels (low, medium, and high) and three nitrogen levels (low, medium, and high), with repeated treatments. In pixel distribution of DSM for each block, it provided bimodal distribution representing two peaks, ground level (gaps within canopies) and top of the canopies respectively. Using bimodal distribution, mean cane height was extracted for each block by applying a trimmed mean to the pixel distribution, focusing on the top canopy points. Similarly, the extracted mean elevation of the base was derived from the bottom points, representing ground level. The Derived Cane Height Model (DCHM) was generated by taking the difference between the mean canopy height and mean base elevation for each block. Yield measurements (tons/acre) were recorded post-harvest for each block. By aggregating the data into nine treatment zones (e.g., high water-low nitrogen, low water-high nitrogen), the DCHM and median yield were calculated for each zone. The regression analysis between the DCHM and corresponding yields for the different treatment zones yielded an R 2 of 0.95. This study demonstrates the significant impact of water and nitrogen treatments on sugarcane height and yield, utilizing one-time UAV-derived DSM data.
Dataset Distillation-based Hybrid Federated Learning on Non-IID Data
Sep 26, 2024



In federated learning, the heterogeneity of client data has a great impact on the performance of model training. Many heterogeneity issues in this process are raised by non-independently and identically distributed (Non-IID) data. This study focuses on the issue of label distribution skew. To address it, we propose a hybrid federated learning framework called HFLDD, which integrates dataset distillation to generate approximately independent and equally distributed (IID) data, thereby improving the performance of model training. Particularly, we partition the clients into heterogeneous clusters, where the data labels among different clients within a cluster are unbalanced while the data labels among different clusters are balanced. The cluster headers collect distilled data from the corresponding cluster members, and conduct model training in collaboration with the server. This training process is like traditional federated learning on IID data, and hence effectively alleviates the impact of Non-IID data on model training. Furthermore, we compare our proposed method with typical baseline methods on public datasets. Experimental results demonstrate that when the data labels are severely imbalanced, the proposed HFLDD outperforms the baseline methods in terms of both test accuracy and communication cost.
Dynamic Label Adversarial Training for Deep Learning Robustness Against Adversarial Attacks
Aug 23, 2024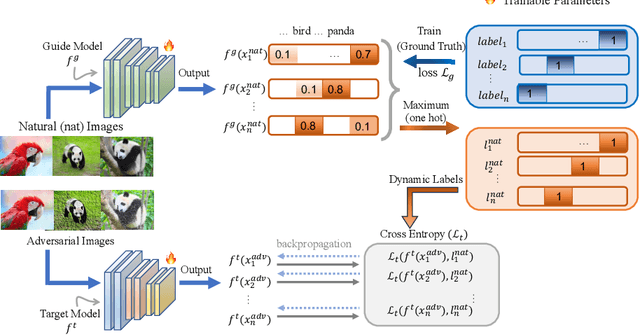
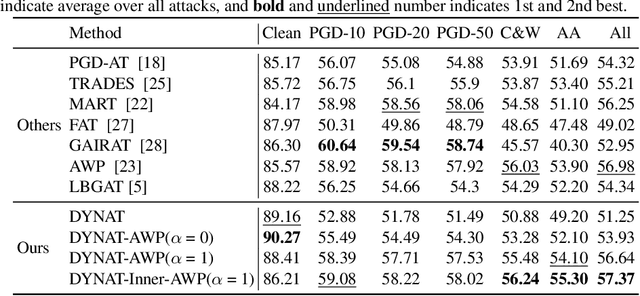
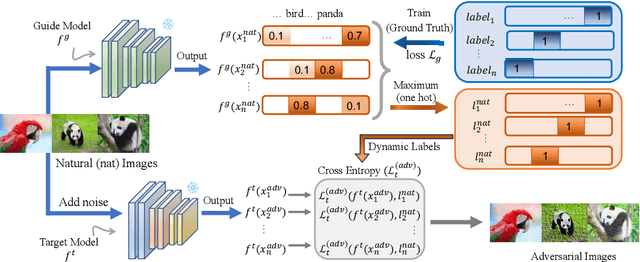

Adversarial training is one of the most effective methods for enhancing model robustness. Recent approaches incorporate adversarial distillation in adversarial training architectures. However, we notice two scenarios of defense methods that limit their performance: (1) Previous methods primarily use static ground truth for adversarial training, but this often causes robust overfitting; (2) The loss functions are either Mean Squared Error or KL-divergence leading to a sub-optimal performance on clean accuracy. To solve those problems, we propose a dynamic label adversarial training (DYNAT) algorithm that enables the target model to gradually and dynamically gain robustness from the guide model's decisions. Additionally, we found that a budgeted dimension of inner optimization for the target model may contribute to the trade-off between clean accuracy and robust accuracy. Therefore, we propose a novel inner optimization method to be incorporated into the adversarial training. This will enable the target model to adaptively search for adversarial examples based on dynamic labels from the guiding model, contributing to the robustness of the target model. Extensive experiments validate the superior performance of our approach.