 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreenServ: Energy-Efficient Context-Aware Dynamic Routing for Multi-Model LLM Inference
Jan 24, 2026Large language models (LLMs) demonstrate remarkable capabilities, but their broad deployment is limited by significant computational resource demands, particularly energy consumption during inference. Static, one-model-fits-all inference strategies are often inefficient, as they do not exploit the diverse range of available models or adapt to varying query requirements. This paper presents GreenServ, a dynamic, context-aware routing framework that optimizes the trade-off between inference accuracy and energy efficiency. GreenServ extracts lightweight contextual features from each query, including task type, semantic cluster, and text complexity, and routes queries to the most suitable model from a heterogeneous pool, based on observed accuracy and energy usage. We employ a multi-armed bandit approach to learn adaptive routing policies online. This approach operates under partial feedback, eliminates the need for extensive offline calibration, and streamlines the integration of new models into the inference pipeline. We evaluated GreenServ across five benchmark tasks and a pool of 16 contemporary open-access LLMs. Experimental results show that GreenServ consistently outperforms static (single-model) and random baselines. In particular, compared to random routing, GreenServ achieved a 22% increase in accuracy while reducing cumulative energy consumption by 31%. Finally, we evaluated GreenServ with RouterBench, achieving an average accuracy of 71.7% with a peak accuracy of 75.7%. All artifacts are open-source and available as an anonymous repository for review purposes here: https://anonymous.4open.science/r/llm-inference-router-EBEA/README.md
Benchmarking of CPU-intensive Stream Data Processing in The Edge Computing Systems
May 12, 2025Edge computing has emerged as a pivotal technology, offering significant advantages such as low latency, enhanced data security, and reduced reliance on centralized cloud infrastructure. These benefits are crucial for applications requiring real-time data processing or strict security measures. Despite these advantages, edge devices operating within edge clusters are often underutilized. This inefficiency is mainly due to the absence of a holistic performance profiling mechanism which can help dynamically adjust the desired system configuration for a given workload. Since edge computing environments involve a complex interplay between CPU frequency, power consumption, and application performance, a deeper understanding of these correlations is essential. By uncovering these relationships, it becomes possible to make informed decisions that enhance both computational efficiency and energy savings. To address this gap, this paper evaluates the power consumption and performance characteristics of a single processing node within an edge cluster using a synthetic microbenchmark by varying the workload size and CPU frequency. The results show how an optimal measure can lead to optimized usage of edge resources, given both performance and power consumption.
GREEN-CODE: Optimizing Energy Efficiency in Large Language Models for Code Generation
Jan 19, 2025



Large Language Models (LLMs) are becoming integral to daily life, showcasing their vast potential across various Natural Language Processing (NLP) tasks. Beyond NLP, LLMs are increasingly used in software development tasks, such as code completion, modification, bug fixing, and code translation. Software engineers widely use tools like GitHub Copilot and Amazon Q, streamlining workflows and automating tasks with high accuracy. While the resource and energy intensity of LLM training is often highlighted, inference can be even more resource-intensive over time, as it's a continuous process with a high number of invocations. Therefore, developing resource-efficient alternatives for LLM inference is crucial for sustainability. This work proposes GREEN-CODE, a framework for energy-aware code generation in LLMs. GREEN-CODE performs dynamic early exit during LLM inference. We train a Reinforcement Learning (RL) agent that learns to balance the trade-offs between accuracy, latency, and energy consumption. Our approach is evaluated on two open-source LLMs, Llama 3.2 3B and OPT 2.7B, using the JavaCorpus and PY150 datasets. Results show that our method reduces the energy consumption between 23-50 % on average for code generation tasks without significantly affecting accuracy.
Investigating Energy Efficiency and Performance Trade-offs in LLM Inference Across Tasks and DVFS Settings
Jan 14, 2025



Large language models (LLMs) have shown significant improvements in many natural language processing (NLP) tasks, accelerating their rapid adoption across many industries. These models are resource-intensive, requiring extensive computational resources both during training and inference, leading to increased energy consumption and negative environmental impact. As their adoption accelerates, the sustainability of LLMs has become a critical issue, necessitating strategies to optimize their runtime efficiency without compromising performance. Hence, it is imperative to identify the parameters that significantly influence the performance and energy efficiency of LLMs. To that end, in this work, we investigate the effect of important parameters on the performance and energy efficiency of LLMs during inference and examine their trade-offs. First, we analyze how different types of models with varying numbers of parameters and architectures perform on tasks like text generation, question answering, and summarization by benchmarking LLMs such as Falcon-7B, Mistral-7B-v0.1, T5-3B, GPT-2, GPT-J-6B, and GPT-Neo-2.7B. Second, we study input and output sequence characteristics such as sequence length concerning energy consumption, performance, and throughput. Finally, we explore the impact of hardware-based power-saving techniques, i.e., Dynamic Voltage Frequency Scaling (DVFS), on the models' latency and energy efficiency. Our extensive benchmarking and statistical analysis reveal many interesting findings, uncovering how specific optimizations can reduce energy consumption while maintaining throughput and accuracy. This study provides actionable insights for researchers and practitioners to design energy-efficient LLM inference systems.
DynaSplit: A Hardware-Software Co-Design Framework for Energy-Aware Inference on Edge
Oct 31, 2024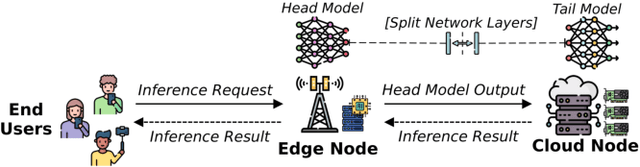
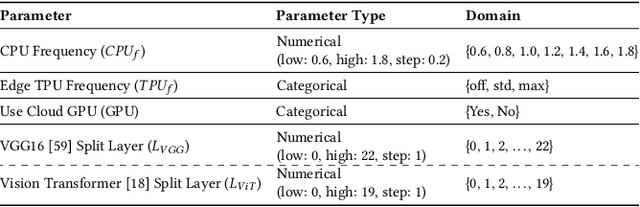

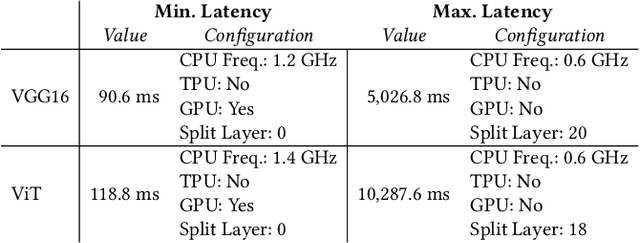
The deployment of ML models on edge devices is challenged by limited computational resources and energy availability. While split computing enables the decomposition of large neural networks (NNs) and allows partial computation on both edge and cloud devices, identifying the most suitable split layer and hardware configurations is a non-trivial task. This process is in fact hindered by the large configuration space, the non-linear dependencies between software and hardware parameters, the heterogeneous hardware and energy characteristics, and the dynamic workload conditions. To overcome this challenge, we propose DynaSplit, a two-phase framework that dynamically configures parameters across both software (i.e., split layer) and hardware (e.g., accelerator usage, CPU frequency). During the Offline Phase, we solve a multi-objective optimization problem with a meta-heuristic approach to discover optimal settings. During the Online Phase, a scheduling algorithm identifies the most suitable settings for an incoming inference request and configures the system accordingly. We evaluate DynaSplit using popular pre-trained NNs on a real-world testbed. Experimental results show a reduction in energy consumption up to 72% compared to cloud-only computation, while meeting ~90% of user request's latency threshold compared to baselines.
ABBA-VSM: Time Series Classification using Symbolic Representation on the Edge
Oct 14, 2024In recent years, Edge AI has become more prevalent with applications across various industries, from environmental monitoring to smart city management. Edge AI facilitates the processing of Internet of Things (IoT) data and provides privacy-enabled and latency-sensitive services to application users using Machine Learning (ML) algorithms, e.g., Time Series Classification (TSC). However, existing TSC algorithms require access to full raw data and demand substantial computing resources to train and use them effectively in runtime. This makes them impractical for deployment in resource-constrained Edge environments. To address this, in this paper, we propose an Adaptive Brownian Bridge-based Symbolic Aggregation Vector Space Model (ABBA-VSM). It is a new TSC model designed for classification services on Edge. Here, we first adaptively compress the raw time series into symbolic representations, thus capturing the changing trends of data. Subsequently, we train the classification model directly on these symbols. ABBA-VSM reduces communication data between IoT and Edge devices, as well as computation cycles, in the development of resource-efficient TSC services on Edge. We evaluate our solution with extensive experiments using datasets from the UCR time series classification archive. The results demonstrate that the ABBA-VSM achieves up to 80% compression ratio and 90-100% accuracy for binary classification. Whereas, for non-binary classification, it achieves an average compression ratio of 60% and accuracy ranging from 60-80%.
A Decentralized and Self-Adaptive Approach for Monitoring Volatile Edge Environments
May 13, 2024Edge computing provides resources for IoT workloads at the network edge. Monitoring systems are vital for efficiently managing resources and application workloads by collecting, storing, and providing relevant information about the state of the resources. However, traditional monitoring systems have a centralized architecture for both data plane and control plane, which increases latency, creates a failure bottleneck, and faces challenges in providing quick and trustworthy data in volatile edge environments, especially where infrastructures are often built upon failure-prone, unsophisticated computing and network resources. Thus, we propose DEMon, a decentralized, self-adaptive monitoring system for edge. DEMon leverages the stochastic gossip communication protocol at its core. It develops efficient protocols for information dissemination, communication, and retrieval, avoiding a single point of failure and ensuring fast and trustworthy data access. Its decentralized control enables self-adaptive management of monitoring parameters, addressing the trade-offs between the quality of service of monitoring and resource consumption. We implement the proposed system as a lightweight and portable container-based system and evaluate it through experiments. We also present a use case demonstrating its feasibility. The results show that DEMon efficiently disseminates and retrieves the monitoring information, addressing the challenges of edge monitoring.
FLIGAN: Enhancing Federated Learning with Incomplete Data using GAN
Apr 02, 2024



Federated Learning (FL) provides a privacy-preserving mechanism for distributed training of machine learning models on networked devices (e.g., mobile devices, IoT edge nodes). It enables Artificial Intelligence (AI) at the edge by creating models without sharing actual data across the network. Existing research typically focuses on generic aspects of non-IID data and heterogeneity in client's system characteristics, but they often neglect the issue of insufficient data for model development, which can arise from uneven class label distribution and highly variable data volumes across edge nodes. In this work, we propose FLIGAN, a novel approach to address the issue of data incompleteness in FL. First, we leverage Generative Adversarial Networks (GANs) to adeptly capture complex data distributions and generate synthetic data that closely resemble real-world data. Then, we use synthetic data to enhance the robustness and completeness of datasets across nodes. Our methodology adheres to FL's privacy requirements by generating synthetic data in a federated manner without sharing the actual data in the process. We incorporate techniques such as classwise sampling and node grouping, designed to improve the federated GAN's performance, enabling the creation of high-quality synthetic datasets and facilitating efficient FL training. Empirical results from our experiments demonstrate that FLIGAN significantly improves model accuracy, especially in scenarios with high class imbalances, achieving up to a 20% increase in model accuracy over traditional FL baselines.
SymED: Adaptive and Online Symbolic Representation of Data on the Edge
Sep 06, 2023The edge computing paradigm helps handle the Internet of Things (IoT) generated data in proximity to its source. Challenges occur in transferring, storing, and processing this rapidly growing amount of data on resource-constrained edge devices. Symbolic Representation (SR) algorithms are promising solutions to reduce the data size by converting actual raw data into symbols. Also, they allow data analytics (e.g., anomaly detection and trend prediction) directly on symbols, benefiting large classes of edge applications. However, existing SR algorithms are centralized in design and work offline with batch data, which is infeasible for real-time cases. We propose SymED - Symbolic Edge Data representation method, i.e., an online, adaptive, and distributed approach for symbolic representation of data on edge. SymED is based on the Adaptive Brownian Bridge-based Aggregation (ABBA), where we assume low-powered IoT devices do initial data compression (senders) and the more robust edge devices do the symbolic conversion (receivers). We evaluate SymED by measuring compression performance, reconstruction accuracy through Dynamic Time Warping (DTW) distance, and computational latency. The results show that SymED is able to (i) reduce the raw data with an average compression rate of 9.5%; (ii) keep a low reconstruction error of 13.25 in the DTW space; (iii) simultaneously provide real-time adaptability for online streaming IoT data at typical latencies of 42ms per symbol, reducing the overall network traffic.
* 14 pages, 5 figures
An Energy-Aware Approach to Design Self-Adaptive AI-based Applications on the Edge
Aug 31, 2023
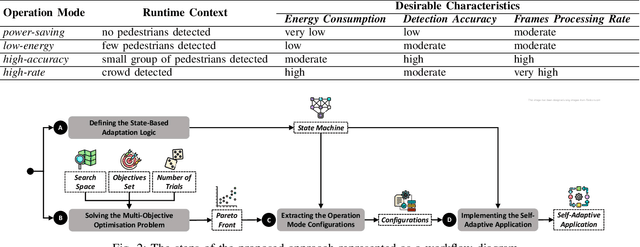
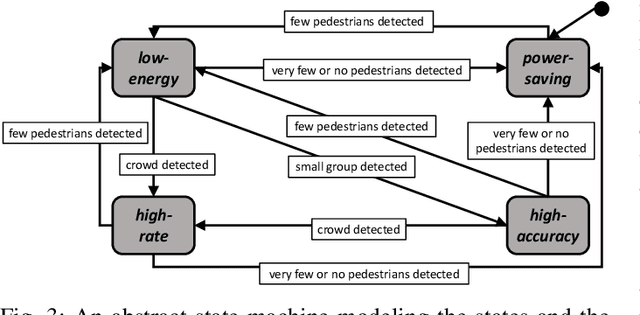
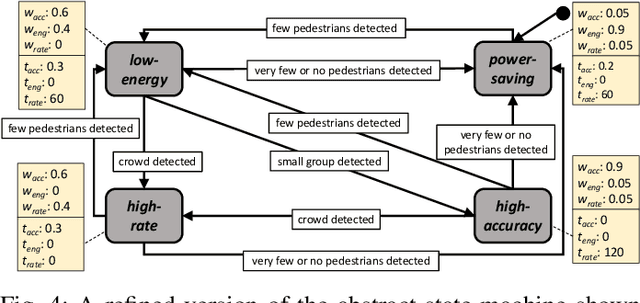
The advent of edge devices dedicated to machine learning tasks enabled the execution of AI-based applications that efficiently process and classify the data acquired by the resource-constrained devices populating the Internet of Things. The proliferation of such applications (e.g., critical monitoring in smart cities) demands new strategies to make these systems also sustainable from an energetic point of view. In this paper, we present an energy-aware approach for the design and deployment of self-adaptive AI-based applications that can balance application objectives (e.g., accuracy in object detection and frames processing rate) with energy consumption. We address the problem of determining the set of configurations that can be used to self-adapt the system with a meta-heuristic search procedure that only needs a small number of empirical samples. The final set of configurations are selected using weighted gray relational analysis, and mapped to the operation modes of the self-adaptive application. We validate our approach on an AI-based application for pedestrian detection. Results show that our self-adaptive application can outperform non-adaptive baseline configurations by saving up to 81\% of energy while loosing only between 2% and 6% in accuracy.