 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreenServ: Energy-Efficient Context-Aware Dynamic Routing for Multi-Model LLM Inference
Jan 24, 2026Large language models (LLMs) demonstrate remarkable capabilities, but their broad deployment is limited by significant computational resource demands, particularly energy consumption during inference. Static, one-model-fits-all inference strategies are often inefficient, as they do not exploit the diverse range of available models or adapt to varying query requirements. This paper presents GreenServ, a dynamic, context-aware routing framework that optimizes the trade-off between inference accuracy and energy efficiency. GreenServ extracts lightweight contextual features from each query, including task type, semantic cluster, and text complexity, and routes queries to the most suitable model from a heterogeneous pool, based on observed accuracy and energy usage. We employ a multi-armed bandit approach to learn adaptive routing policies online. This approach operates under partial feedback, eliminates the need for extensive offline calibration, and streamlines the integration of new models into the inference pipeline. We evaluated GreenServ across five benchmark tasks and a pool of 16 contemporary open-access LLMs. Experimental results show that GreenServ consistently outperforms static (single-model) and random baselines. In particular, compared to random routing, GreenServ achieved a 22% increase in accuracy while reducing cumulative energy consumption by 31%. Finally, we evaluated GreenServ with RouterBench, achieving an average accuracy of 71.7% with a peak accuracy of 75.7%. All artifacts are open-source and available as an anonymous repository for review purposes here: https://anonymous.4open.science/r/llm-inference-router-EBEA/README.md
Clustered Federated Learning with Hierarchical Knowledge Distillation
Dec 11, 2025Clustered Federated Learning (CFL) has emerged as a powerful approach for addressing data heterogeneity and ensuring privacy in large distributed IoT environments. By clustering clients and training cluster-specific models, CFL enables personalized models tailored to groups of heterogeneous clients. However, conventional CFL approaches suffer from fragmented learning for training independent global models for each cluster and fail to take advantage of collective cluster insights. This paper advocates a shift to hierarchical CFL, allowing bi-level aggregation to train cluster-specific models at the edge and a unified global model at the cloud. This shift improves training efficiency yet might introduce communication challenges. To this end, we propose CFLHKD, a novel personalization scheme for integrating hierarchical cluster knowledge into CFL. Built upon multi-teacher knowledge distillation, CFLHKD enables inter-cluster knowledge sharing while preserving cluster-specific personalization. CFLHKD adopts a bi-level aggregation to bridge the gap between local and global learning. Extensive evaluations of standard benchmark datasets demonstrate that CFLHKD outperforms representative baselines in cluster-specific and global model accuracy and achieves a performance improvement of 3.32-7.57\%.
GREEN-CODE: Optimizing Energy Efficiency in Large Language Models for Code Generation
Jan 19, 2025



Large Language Models (LLMs) are becoming integral to daily life, showcasing their vast potential across various Natural Language Processing (NLP) tasks. Beyond NLP, LLMs are increasingly used in software development tasks, such as code completion, modification, bug fixing, and code translation. Software engineers widely use tools like GitHub Copilot and Amazon Q, streamlining workflows and automating tasks with high accuracy. While the resource and energy intensity of LLM training is often highlighted, inference can be even more resource-intensive over time, as it's a continuous process with a high number of invocations. Therefore, developing resource-efficient alternatives for LLM inference is crucial for sustainability. This work proposes GREEN-CODE, a framework for energy-aware code generation in LLMs. GREEN-CODE performs dynamic early exit during LLM inference. We train a Reinforcement Learning (RL) agent that learns to balance the trade-offs between accuracy, latency, and energy consumption. Our approach is evaluated on two open-source LLMs, Llama 3.2 3B and OPT 2.7B, using the JavaCorpus and PY150 datasets. Results show that our method reduces the energy consumption between 23-50 % on average for code generation tasks without significantly affecting accuracy.
Investigating Energy Efficiency and Performance Trade-offs in LLM Inference Across Tasks and DVFS Settings
Jan 14, 2025



Large language models (LLMs) have shown significant improvements in many natural language processing (NLP) tasks, accelerating their rapid adoption across many industries. These models are resource-intensive, requiring extensive computational resources both during training and inference, leading to increased energy consumption and negative environmental impact. As their adoption accelerates, the sustainability of LLMs has become a critical issue, necessitating strategies to optimize their runtime efficiency without compromising performance. Hence, it is imperative to identify the parameters that significantly influence the performance and energy efficiency of LLMs. To that end, in this work, we investigate the effect of important parameters on the performance and energy efficiency of LLMs during inference and examine their trade-offs. First, we analyze how different types of models with varying numbers of parameters and architectures perform on tasks like text generation, question answering, and summarization by benchmarking LLMs such as Falcon-7B, Mistral-7B-v0.1, T5-3B, GPT-2, GPT-J-6B, and GPT-Neo-2.7B. Second, we study input and output sequence characteristics such as sequence length concerning energy consumption, performance, and throughput. Finally, we explore the impact of hardware-based power-saving techniques, i.e., Dynamic Voltage Frequency Scaling (DVFS), on the models' latency and energy efficiency. Our extensive benchmarking and statistical analysis reveal many interesting findings, uncovering how specific optimizations can reduce energy consumption while maintaining throughput and accuracy. This study provides actionable insights for researchers and practitioners to design energy-efficient LLM inference systems.
DynaSplit: A Hardware-Software Co-Design Framework for Energy-Aware Inference on Edge
Oct 31, 2024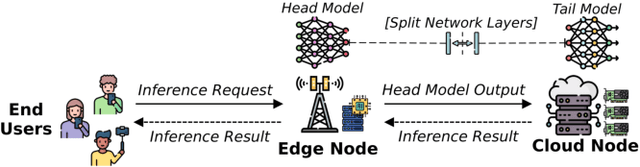
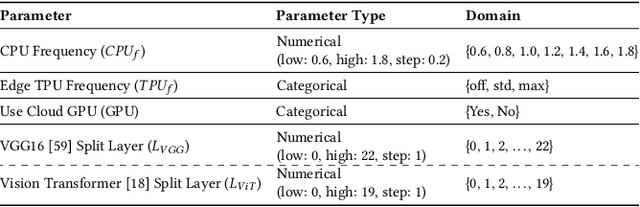

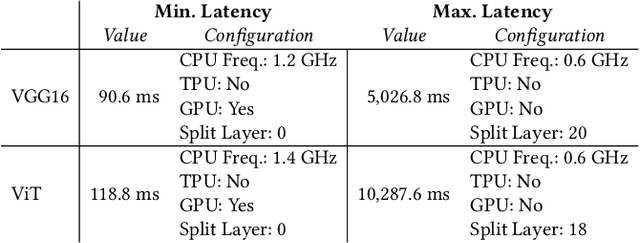
The deployment of ML models on edge devices is challenged by limited computational resources and energy availability. While split computing enables the decomposition of large neural networks (NNs) and allows partial computation on both edge and cloud devices, identifying the most suitable split layer and hardware configurations is a non-trivial task. This process is in fact hindered by the large configuration space, the non-linear dependencies between software and hardware parameters, the heterogeneous hardware and energy characteristics, and the dynamic workload conditions. To overcome this challenge, we propose DynaSplit, a two-phase framework that dynamically configures parameters across both software (i.e., split layer) and hardware (e.g., accelerator usage, CPU frequency). During the Offline Phase, we solve a multi-objective optimization problem with a meta-heuristic approach to discover optimal settings. During the Online Phase, a scheduling algorithm identifies the most suitable settings for an incoming inference request and configures the system accordingly. We evaluate DynaSplit using popular pre-trained NNs on a real-world testbed. Experimental results show a reduction in energy consumption up to 72% compared to cloud-only computation, while meeting ~90% of user request's latency threshold compared to baselines.
ABBA-VSM: Time Series Classification using Symbolic Representation on the Edge
Oct 14, 2024In recent years, Edge AI has become more prevalent with applications across various industries, from environmental monitoring to smart city management. Edge AI facilitates the processing of Internet of Things (IoT) data and provides privacy-enabled and latency-sensitive services to application users using Machine Learning (ML) algorithms, e.g., Time Series Classification (TSC). However, existing TSC algorithms require access to full raw data and demand substantial computing resources to train and use them effectively in runtime. This makes them impractical for deployment in resource-constrained Edge environments. To address this, in this paper, we propose an Adaptive Brownian Bridge-based Symbolic Aggregation Vector Space Model (ABBA-VSM). It is a new TSC model designed for classification services on Edge. Here, we first adaptively compress the raw time series into symbolic representations, thus capturing the changing trends of data. Subsequently, we train the classification model directly on these symbols. ABBA-VSM reduces communication data between IoT and Edge devices, as well as computation cycles, in the development of resource-efficient TSC services on Edge. We evaluate our solution with extensive experiments using datasets from the UCR time series classification archive. The results demonstrate that the ABBA-VSM achieves up to 80% compression ratio and 90-100% accuracy for binary classification. Whereas, for non-binary classification, it achieves an average compression ratio of 60% and accuracy ranging from 60-80%.
Exploring Channel Distinguishability in Local Neighborhoods of the Model Space in Quantum Neural Networks
Oct 12, 2024With the increasing interest in Quantum Machine Learning, Quantum Neural Networks (QNNs) have emerged and gained significant attention. These models have, however, been shown to be notoriously difficult to train, which we hypothesize is partially due to the architectures, called ansatzes, that are hardly studied at this point. Therefore, in this paper, we take a step back and analyze ansatzes. We initially consider their expressivity, i.e., the space of operations they are able to express, and show that the closeness to being a 2-design, the primarily used measure, fails at capturing this property. Hence, we look for alternative ways to characterize ansatzes by considering the local neighborhood of the model space, in particular, analyzing model distinguishability upon small perturbation of parameters. We derive an upper bound on their distinguishability, showcasing that QNNs with few parameters are hardly discriminable upon update. Our numerical experiments support our bounds and further indicate that there is a significant degree of variability, which stresses the need for warm-starting or clever initialization. Altogether, our work provides an ansatz-centric perspective on training dynamics and difficulties in QNNs, ultimately suggesting that iterative training of small quantum models may not be effective, which contrasts their initial motivation.
FLIGAN: Enhancing Federated Learning with Incomplete Data using GAN
Apr 02, 2024



Federated Learning (FL) provides a privacy-preserving mechanism for distributed training of machine learning models on networked devices (e.g., mobile devices, IoT edge nodes). It enables Artificial Intelligence (AI) at the edge by creating models without sharing actual data across the network. Existing research typically focuses on generic aspects of non-IID data and heterogeneity in client's system characteristics, but they often neglect the issue of insufficient data for model development, which can arise from uneven class label distribution and highly variable data volumes across edge nodes. In this work, we propose FLIGAN, a novel approach to address the issue of data incompleteness in FL. First, we leverage Generative Adversarial Networks (GANs) to adeptly capture complex data distributions and generate synthetic data that closely resemble real-world data. Then, we use synthetic data to enhance the robustness and completeness of datasets across nodes. Our methodology adheres to FL's privacy requirements by generating synthetic data in a federated manner without sharing the actual data in the process. We incorporate techniques such as classwise sampling and node grouping, designed to improve the federated GAN's performance, enabling the creation of high-quality synthetic datasets and facilitating efficient FL training. Empirical results from our experiments demonstrate that FLIGAN significantly improves model accuracy, especially in scenarios with high class imbalances, achieving up to a 20% increase in model accuracy over traditional FL baselines.
On Optimizing Hyperparameters for Quantum Neural Networks
Mar 27, 2024The increasing capabilities of Machine Learning (ML) models go hand in hand with an immense amount of data and computational power required for training. Therefore, training is usually outsourced into HPC facilities, where we have started to experience limits in scaling conventional HPC hardware, as theorized by Moore's law. Despite heavy parallelization and optimization efforts, current state-of-the-art ML models require weeks for training, which is associated with an enormous $CO_2$ footprint. Quantum Computing, and specifically Quantum Machine Learning (QML), can offer significant theoretical speed-ups and enhanced expressive power. However, training QML models requires tuning various hyperparameters, which is a nontrivial task and suboptimal choices can highly affect the trainability and performance of the models. In this study, we identify the most impactful hyperparameters and collect data about the performance of QML models. We compare different configurations and provide researchers with performance data and concrete suggestions for hyperparameter selection.
Streaming IoT Data and the Quantum Edge: A Classic/Quantum Machine Learning Use Case
Feb 23, 2024With the advent of the Post-Moore era, the scientific community is faced with the challenge of addressing the demands of current data-intensive machine learning applications, which are the cornerstone of urgent analytics in distributed computing. Quantum machine learning could be a solution for the increasing demand of urgent analytics, providing potential theoretical speedups and increased space efficiency. However, challenges such as (1) the encoding of data from the classical to the quantum domain, (2) hyperparameter tuning, and (3) the integration of quantum hardware into a distributed computing continuum limit the adoption of quantum machine learning for urgent analytics. In this work, we investigate the use of Edge computing for the integration of quantum machine learning into a distributed computing continuum, identifying the main challenges and possible solutions. Furthermore, exploring the data encoding and hyperparameter tuning challenges, we present preliminary results for quantum machine learning analytics on an IoT scenario.