 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustered Federated Learning with Hierarchical Knowledge Distillation
Dec 11, 2025Clustered Federated Learning (CFL) has emerged as a powerful approach for addressing data heterogeneity and ensuring privacy in large distributed IoT environments. By clustering clients and training cluster-specific models, CFL enables personalized models tailored to groups of heterogeneous clients. However, conventional CFL approaches suffer from fragmented learning for training independent global models for each cluster and fail to take advantage of collective cluster insights. This paper advocates a shift to hierarchical CFL, allowing bi-level aggregation to train cluster-specific models at the edge and a unified global model at the cloud. This shift improves training efficiency yet might introduce communication challenges. To this end, we propose CFLHKD, a novel personalization scheme for integrating hierarchical cluster knowledge into CFL. Built upon multi-teacher knowledge distillation, CFLHKD enables inter-cluster knowledge sharing while preserving cluster-specific personalization. CFLHKD adopts a bi-level aggregation to bridge the gap between local and global learning. Extensive evaluations of standard benchmark datasets demonstrate that CFLHKD outperforms representative baselines in cluster-specific and global model accuracy and achieves a performance improvement of 3.32-7.57\%.
Roadmap for Edge AI: A Dagstuhl Perspective
Nov 27, 2021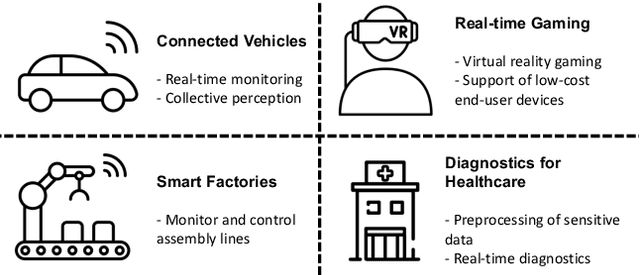
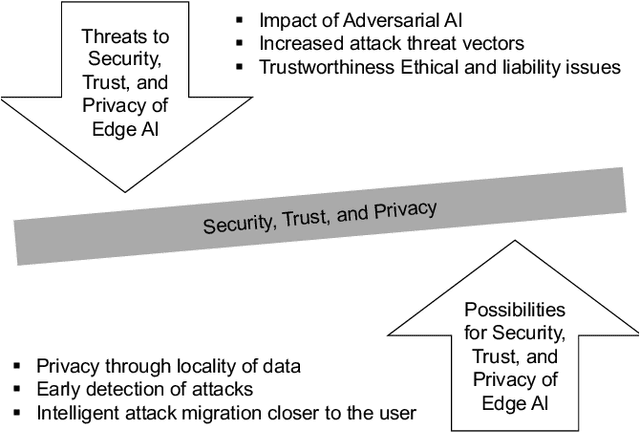
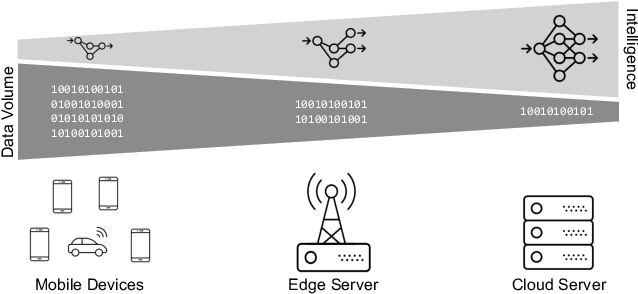

Based on the collective input of Dagstuhl Seminar (21342), this paper presents a comprehensive discussion on AI methods and capabilities in the context of edge computing, referred as Edge AI. In a nutshell, we envision Edge AI to provide adaptation for data-driven applications, enhance network and radio access, and allow the creation, optimization, and deployment of distributed AI/ML pipelines with given quality of experience, trust, security and privacy targets. The Edge AI community investigates novel ML methods for the edge computing environment, spanning multiple sub-fields of computer science, engineering and ICT. The goal is to share an envisioned roadmap that can bring together key actors and enablers to further advance the domain of Edge AI.
Multi-agent Bayesian Deep Reinforcement Learning for Microgrid Energy Management under Communication Failures
Nov 22, 2021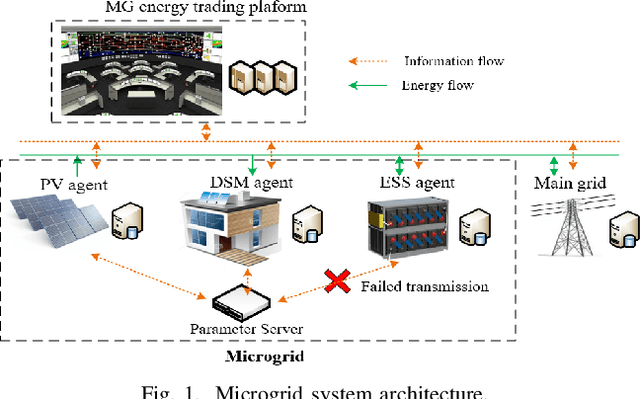
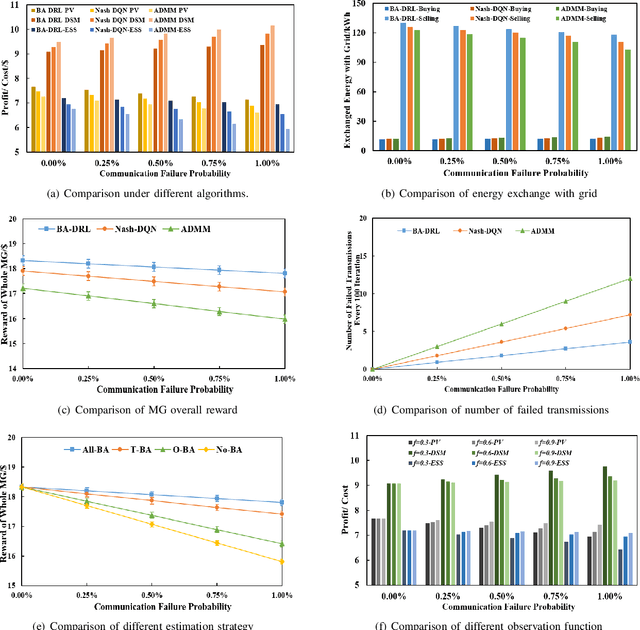
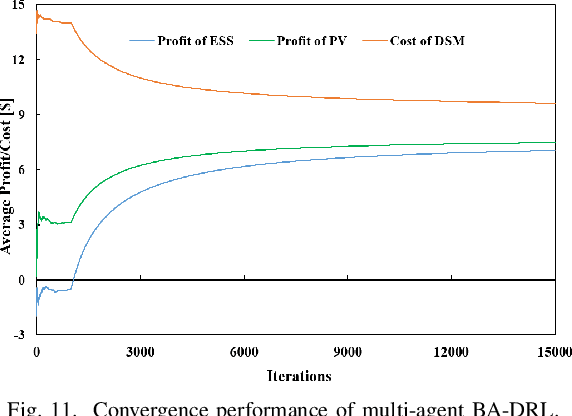
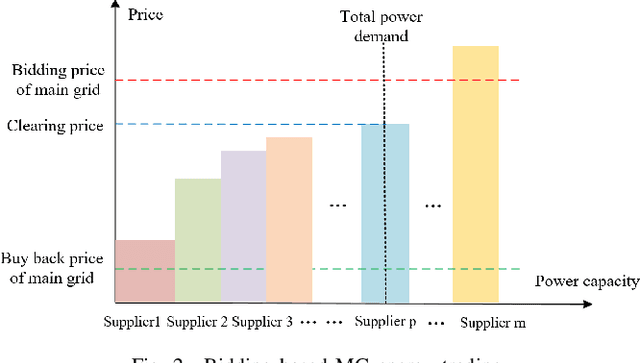
Microgrids (MGs) are important players for the future transactive energy systems where a number of intelligent Internet of Things (IoT) devices interact for energy management in the smart grid. Although there have been many works on MG energy management, most studies assume a perfect communication environment, where communication failures are not considered. In this paper, we consider the MG as a multi-agent environment with IoT devices in which AI agents exchange information with their peers for collaboration. However, the collaboration information may be lost due to communication failures or packet loss. Such events may affect the operation of the whole MG. To this end, we propose a multi-agent Bayesian deep reinforcement learning (BA-DRL) method for MG energy management under communication failures. We first define a multi-agent partially observable Markov decision process (MA-POMDP) to describe agents under communication failures, in which each agent can update its beliefs on the actions of its peers. Then, we apply a double deep Q-learning (DDQN) architecture for Q-value estimation in BA-DRL, and propose a belief-based correlated equilibrium for the joint-action selection of multi-agent BA-DRL. Finally, the simulation results show that BA-DRL is robust to both power supply uncertainty and communication failure uncertainty. BA-DRL has 4.1% and 10.3% higher reward than Nash Deep Q-learning (Nash-DQN) and alternating direction method of multipliers (ADMM) respectively under 1% communication failure probability.