 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoadmap for Edge AI: A Dagstuhl Perspective
Nov 27, 2021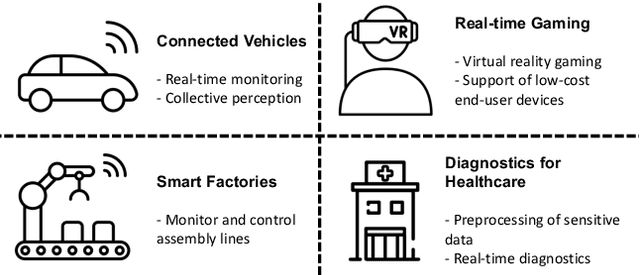
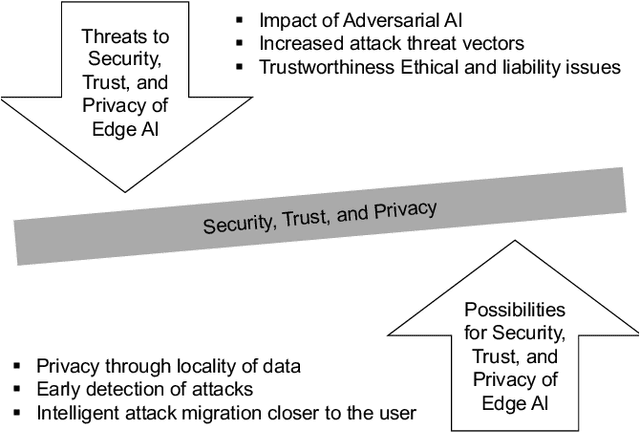
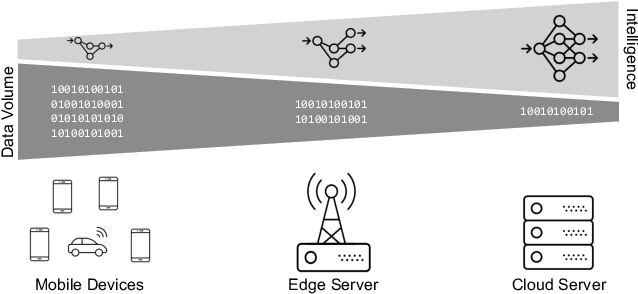

Based on the collective input of Dagstuhl Seminar (21342), this paper presents a comprehensive discussion on AI methods and capabilities in the context of edge computing, referred as Edge AI. In a nutshell, we envision Edge AI to provide adaptation for data-driven applications, enhance network and radio access, and allow the creation, optimization, and deployment of distributed AI/ML pipelines with given quality of experience, trust, security and privacy targets. The Edge AI community investigates novel ML methods for the edge computing environment, spanning multiple sub-fields of computer science, engineering and ICT. The goal is to share an envisioned roadmap that can bring together key actors and enablers to further advance the domain of Edge AI.
Evaluation of Hyperparameter-Optimization Approaches in an Industrial Federated Learning System
Oct 20, 2021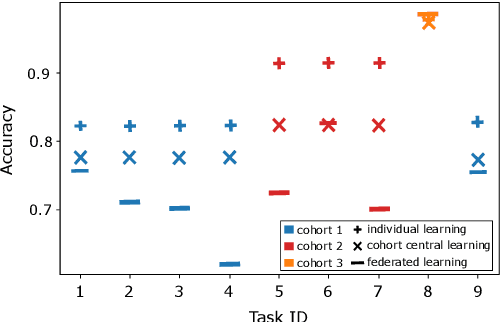
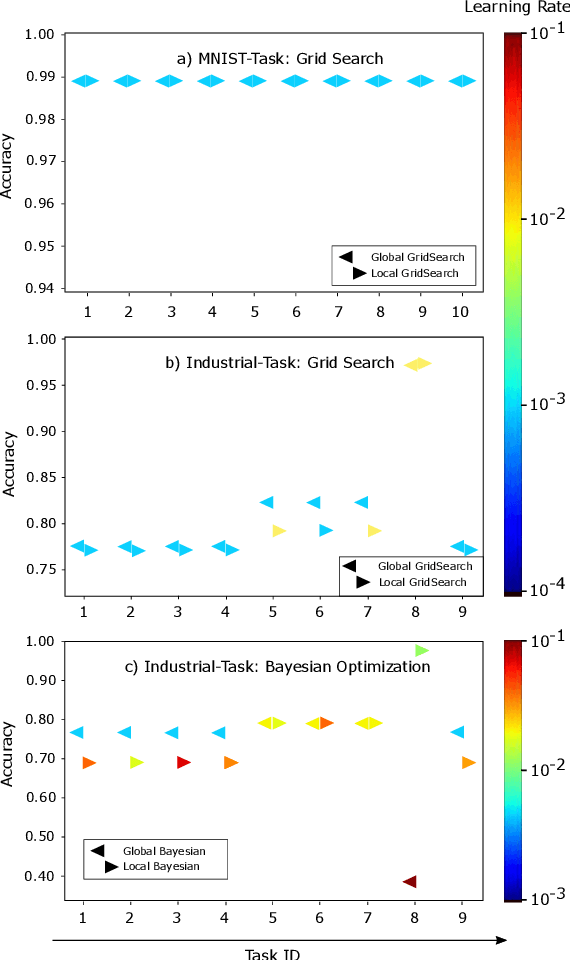
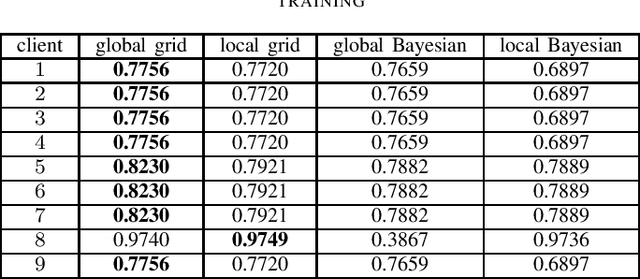
Federated Learning (FL) decouples model training from the need for direct access to the data and allows organizations to collaborate with industry partners to reach a satisfying level of performance without sharing vulnerable business information. The performance of a machine learning algorithm is highly sensitive to the choice of its hyperparameters. In an FL setting, hyperparameter optimization poses new challenges. In this work, we investigated the impact of different hyperparameter optimization approaches in an FL system. In an effort to reduce communication costs, a critical bottleneck in FL, we investigated a local hyperparameter optimization approach that -- in contrast to a global hyperparameter optimization approach -- allows every client to have its own hyperparameter configuration. We implemented these approaches based on grid search and Bayesian optimization and evaluated the algorithms on the MNIST data set using an i.i.d. partition and on an Internet of Things (IoT) sensor based industrial data set using a non-i.i.d. partition.
Industrial Federated Learning -- Requirements and System Design
May 14, 2020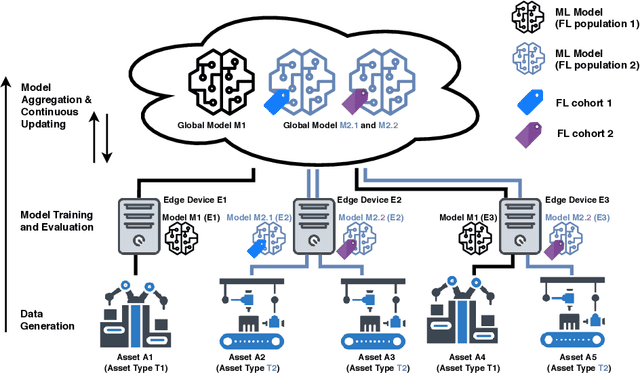
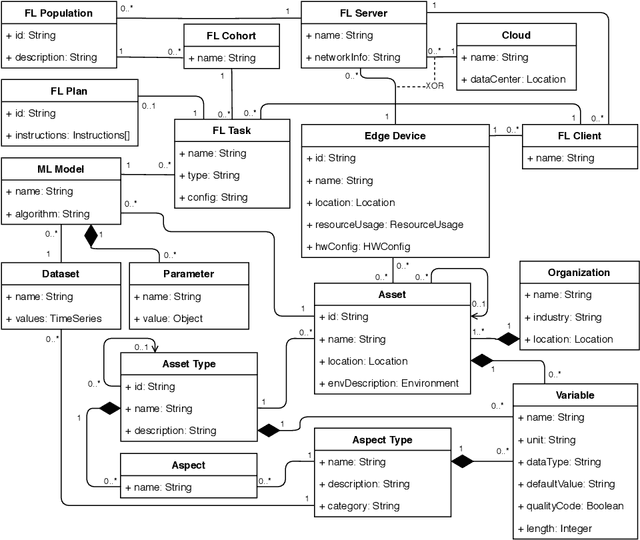
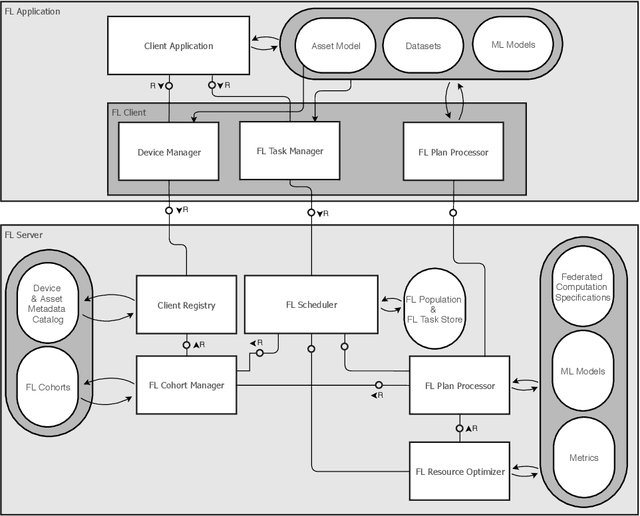
Federated Learning (FL) is a very promising approach for improving decentralized Machine Learning (ML) models by exchanging knowledge between participating clients without revealing private data. Nevertheless, FL is still not tailored to the industrial context as strong data similarity is assumed for all FL tasks. This is rarely the case in industrial machine data with variations in machine type, operational- and environmental conditions. Therefore, we introduce an Industrial Federated Learning (IFL) system supporting knowledge exchange in continuously evaluated and updated FL cohorts of learning tasks with sufficient data similarity. This enables optimal collaboration of business partners in common ML problems, prevents negative knowledge transfer, and ensures resource optimization of involved edge devices.