 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTipSegNet: Fingertip Segmentation in Contactless Fingerprint Imaging
Jan 09, 2025
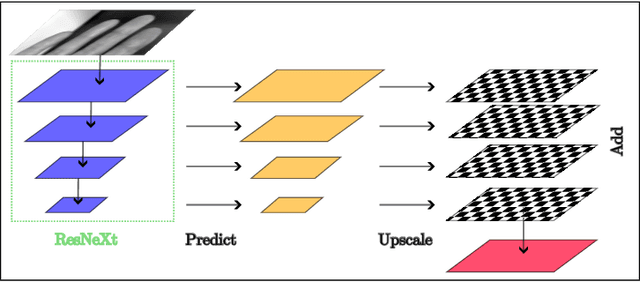

Contactless fingerprint recognition systems offer a hygienic, user-friendly, and efficient alternative to traditional contact-based methods. However, their accuracy heavily relies on precise fingertip detection and segmentation, particularly under challenging background conditions. This paper introduces TipSegNet, a novel deep learning model that achieves state-of-the-art performance in segmenting fingertips directly from grayscale hand images. TipSegNet leverages a ResNeXt-101 backbone for robust feature extraction, combined with a Feature Pyramid Network (FPN) for multi-scale representation, enabling accurate segmentation across varying finger poses and image qualities. Furthermore, we employ an extensive data augmentation strategy to enhance the model's generalizability and robustness. TipSegNet outperforms existing methods, achieving a mean Intersection over Union (mIoU) of 0.987 and an accuracy of 0.999, representing a significant advancement in contactless fingerprint segmentation. This enhanced accuracy has the potential to substantially improve the reliability and effectiveness of contactless biometric systems in real-world applications.
Towards Fingerprint Mosaicking Artifact Detection: A Self-Supervised Deep Learning Approach
Jan 09, 2025Fingerprint mosaicking, which is the process of combining multiple fingerprint images into a single master fingerprint, is an essential process in modern biometric systems. However, it is prone to errors that can significantly degrade fingerprint image quality. This paper proposes a novel deep learning-based approach to detect and score mosaicking artifacts in fingerprint images. Our method leverages a self-supervised learning framework to train a model on large-scale unlabeled fingerprint data, eliminating the need for manual artifact annotation. The proposed model effectively identifies mosaicking errors, achieving high accuracy on various fingerprint modalities, including contactless, rolled, and pressed fingerprints and furthermore proves to be robust to different data sources. Additionally, we introduce a novel mosaicking artifact score to quantify the severity of errors, enabling automated evaluation of fingerprint images. By addressing the challenges of mosaicking artifact detection, our work contributes to improving the accuracy and reliability of fingerprint-based biometric systems.
Centrality of the Fingerprint Core Location
Oct 11, 2023Fingerprints have long been recognized as a unique and reliable means of personal identification. Central to the analysis and enhancement of fingerprints is the concept of the fingerprint core. Although the location of the core is used in many applications, to the best of our knowledge, this study is the first to investigate the empirical distribution of the core over a large, combined dataset of rolled, as well as plain fingerprint recordings. We identify and investigate the extent of incomplete rolling during the rolled fingerprint acquisition and investigate the centrality of the core. After correcting for the incomplete rolling, we find that the core deviates from the fingerprint center by 5.7% $\pm$ 5.2% to 7.6% $\pm$ 6.9%, depending on the finger. Additionally, we find that the assumption of normal distribution of the core position of plain fingerprint recordings cannot be rejected, but for rolled ones it can. Therefore, we use a multi-step process to find the distribution of the rolled fingerprint recordings. The process consists of an Anderson-Darling normality test, the Bayesian Information Criterion to reduce the number of possible candidate distributions and finally a Generalized Monte Carlo goodness-of-fit procedure to find the best fitting distribution. We find the non-central Fischer distribution best describes the cores' horizontal positions. Finally, we investigate the correlation between mean core position offset and the NFIQ 2 score and find that the NFIQ 2 prefers rolled fingerprint recordings where the core sits slightly below the fingerprint center.
Autoencoder based Anomaly Detection and Explained Fault Localization in Industrial Cooling Systems
Oct 14, 2022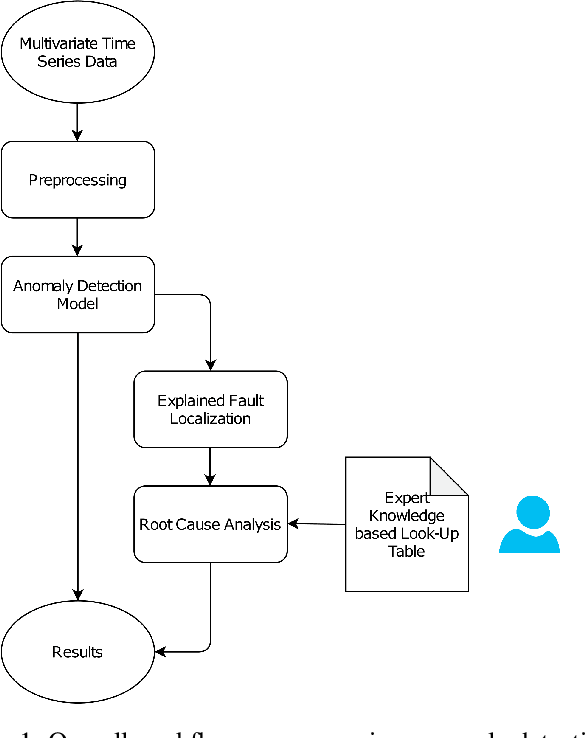
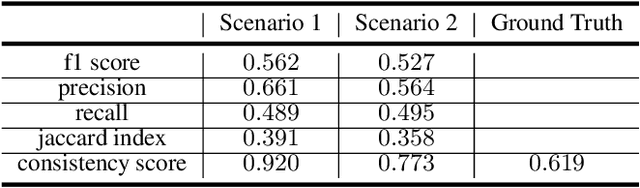
Anomaly detection in large industrial cooling systems is very challenging due to the high data dimensionality, inconsistent sensor recordings, and lack of labels. The state of the art for automated anomaly detection in these systems typically relies on expert knowledge and thresholds. However, data is viewed isolated and complex, multivariate relationships are neglected. In this work, we present an autoencoder based end-to-end workflow for anomaly detection suitable for multivariate time series data in large industrial cooling systems, including explained fault localization and root cause analysis based on expert knowledge. We identify system failures using a threshold on the total reconstruction error (autoencoder reconstruction error including all sensor signals). For fault localization, we compute the individual reconstruction error (autoencoder reconstruction error for each sensor signal) allowing us to identify the signals that contribute most to the total reconstruction error. Expert knowledge is provided via look-up table enabling root-cause analysis and assignment to the affected subsystem. We demonstrated our findings in a cooling system unit including 34 sensors over a 8-months time period using 4-fold cross validation approaches and automatically created labels based on thresholds provided by domain experts. Using 4-fold cross validation, we reached a F1-score of 0.56, whereas the autoencoder results showed a higher consistency score (CS of 0.92) compared to the automatically created labels (CS of 0.62) -- indicating that the anomaly is recognized in a very stable manner. The main anomaly was found by the autoencoder and automatically created labels and was also recorded in the log files. Further, the explained fault localization highlighted the most affected component for the main anomaly in a very consistent manner.
Evaluation of Hyperparameter-Optimization Approaches in an Industrial Federated Learning System
Oct 20, 2021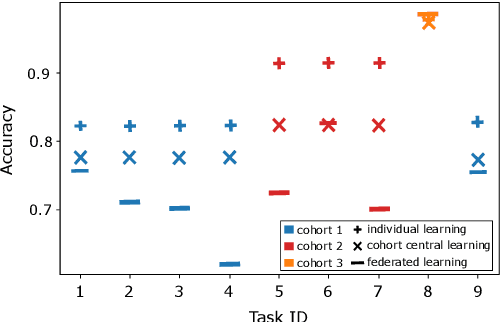
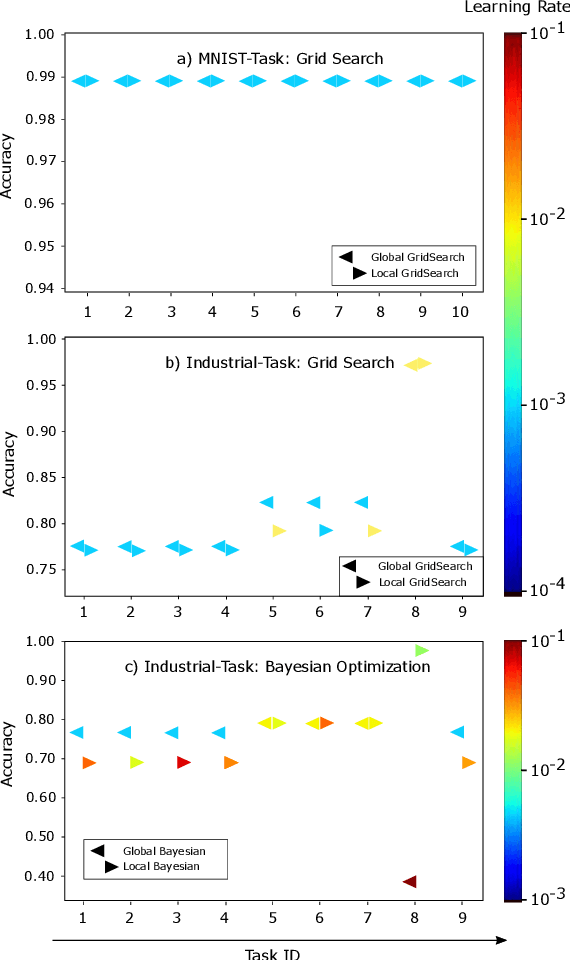
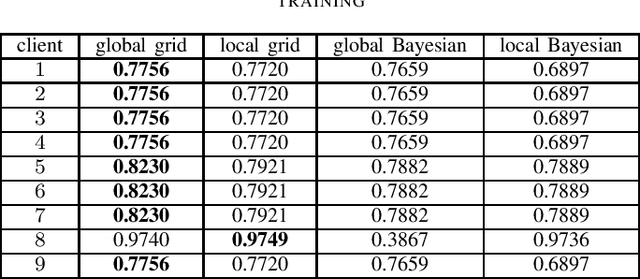
Federated Learning (FL) decouples model training from the need for direct access to the data and allows organizations to collaborate with industry partners to reach a satisfying level of performance without sharing vulnerable business information. The performance of a machine learning algorithm is highly sensitive to the choice of its hyperparameters. In an FL setting, hyperparameter optimization poses new challenges. In this work, we investigated the impact of different hyperparameter optimization approaches in an FL system. In an effort to reduce communication costs, a critical bottleneck in FL, we investigated a local hyperparameter optimization approach that -- in contrast to a global hyperparameter optimization approach -- allows every client to have its own hyperparameter configuration. We implemented these approaches based on grid search and Bayesian optimization and evaluated the algorithms on the MNIST data set using an i.i.d. partition and on an Internet of Things (IoT) sensor based industrial data set using a non-i.i.d. partition.
Bayesian inversion for nanowire field-effect sensors
Apr 12, 2019


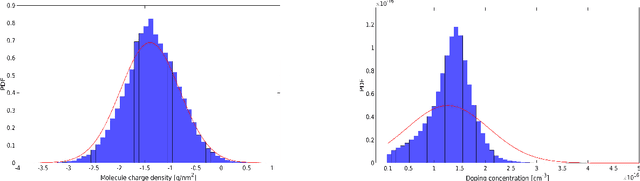
Nanowire field-effect sensors have recently been developed for label-free detection of biomolecules. In this work, we introduce a computational technique based on Bayesian estimation to determine the physical parameters of the sensor and, more importantly, the properties of the analyte molecules. To that end, we first propose a PDE based model to simulate the device charge transport and electrochemical behavior. Then, the adaptive Metropolis algorithm with delayed rejection (DRAM) is applied to estimate the posterior distribution of unknown parameters, namely molecule charge density, molecule density, doping concentration, and electron and hole mobilities. We determine the device and molecules properties simultaneously, and we also calculate the molecule density as the only parameter after having determined the device parameters. This approach makes it possible not only to determine unknown parameters, but it also shows how well each parameter can be determined by yielding the probability density function (pdf).