 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Financial Bots on the Ethereum Blockchain
Mar 28, 2024The integration of bots in Distributed Ledger Technologies (DLTs) fosters efficiency and automation. However, their use is also associated with predatory trading and market manipulation, and can pose threats to system integrity. It is therefore essential to understand the extent of bot deployment in DLTs; despite this, current detection systems are predominantly rule-based and lack flexibility. In this study, we present a novel approach that utilizes machine learning for the detection of financial bots on the Ethereum platform. First, we systematize existing scientific literature and collect anecdotal evidence to establish a taxonomy for financial bots, comprising 7 categories and 24 subcategories. Next, we create a ground-truth dataset consisting of 133 human and 137 bot addresses. Third, we employ both unsupervised and supervised machine learning algorithms to detect bots deployed on Ethereum. The highest-performing clustering algorithm is a Gaussian Mixture Model with an average cluster purity of 82.6%, while the highest-performing model for binary classification is a Random Forest with an accuracy of 83%. Our machine learning-based detection mechanism contributes to understanding the Ethereum ecosystem dynamics by providing additional insights into the current bot landscape.
Predictability and Comprehensibility in Post-Hoc XAI Methods: A User-Centered Analysis
Sep 21, 2023



Post-hoc explainability methods aim to clarify predictions of black-box machine learning models. However, it is still largely unclear how well users comprehend the provided explanations and whether these increase the users ability to predict the model behavior. We approach this question by conducting a user study to evaluate comprehensibility and predictability in two widely used tools: LIME and SHAP. Moreover, we investigate the effect of counterfactual explanations and misclassifications on users ability to understand and predict the model behavior. We find that the comprehensibility of SHAP is significantly reduced when explanations are provided for samples near a model's decision boundary. Furthermore, we find that counterfactual explanations and misclassifications can significantly increase the users understanding of how a machine learning model is making decisions. Based on our findings, we also derive design recommendations for future post-hoc explainability methods with increased comprehensibility and predictability.
Autoencoder based Anomaly Detection and Explained Fault Localization in Industrial Cooling Systems
Oct 14, 2022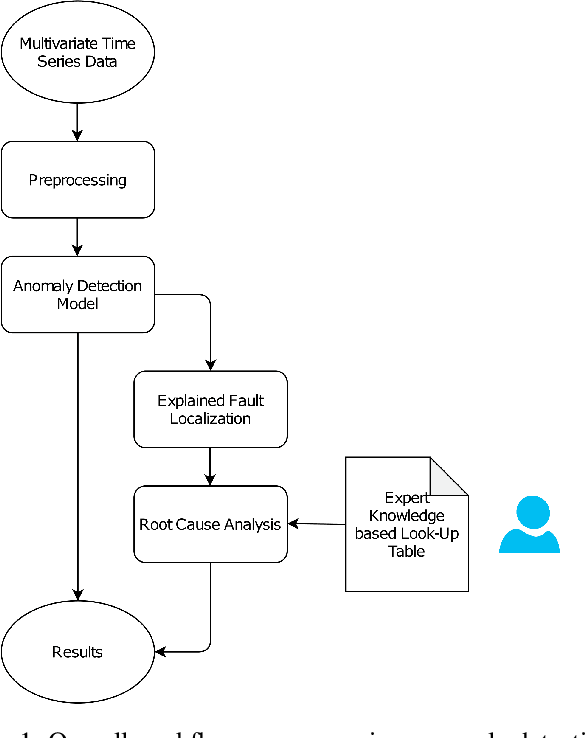
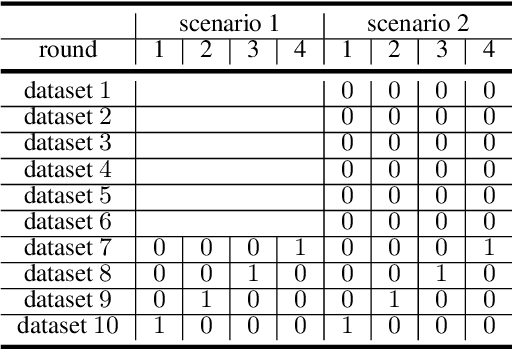
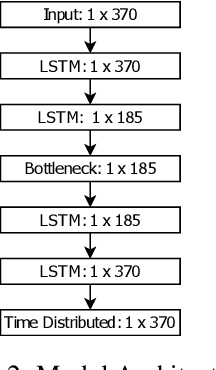
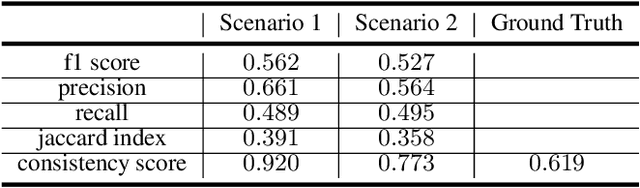
Anomaly detection in large industrial cooling systems is very challenging due to the high data dimensionality, inconsistent sensor recordings, and lack of labels. The state of the art for automated anomaly detection in these systems typically relies on expert knowledge and thresholds. However, data is viewed isolated and complex, multivariate relationships are neglected. In this work, we present an autoencoder based end-to-end workflow for anomaly detection suitable for multivariate time series data in large industrial cooling systems, including explained fault localization and root cause analysis based on expert knowledge. We identify system failures using a threshold on the total reconstruction error (autoencoder reconstruction error including all sensor signals). For fault localization, we compute the individual reconstruction error (autoencoder reconstruction error for each sensor signal) allowing us to identify the signals that contribute most to the total reconstruction error. Expert knowledge is provided via look-up table enabling root-cause analysis and assignment to the affected subsystem. We demonstrated our findings in a cooling system unit including 34 sensors over a 8-months time period using 4-fold cross validation approaches and automatically created labels based on thresholds provided by domain experts. Using 4-fold cross validation, we reached a F1-score of 0.56, whereas the autoencoder results showed a higher consistency score (CS of 0.92) compared to the automatically created labels (CS of 0.62) -- indicating that the anomaly is recognized in a very stable manner. The main anomaly was found by the autoencoder and automatically created labels and was also recorded in the log files. Further, the explained fault localization highlighted the most affected component for the main anomaly in a very consistent manner.
Machine Learning Methods for Health-Index Prediction in Coating Chambers
May 30, 2022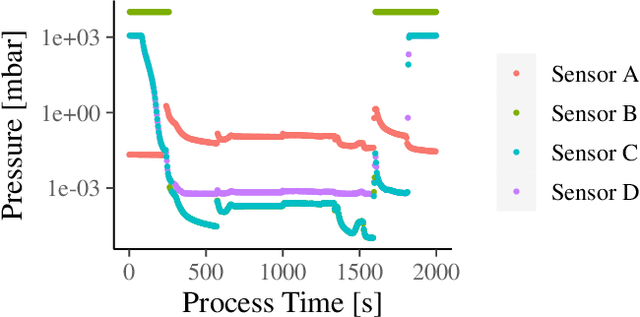
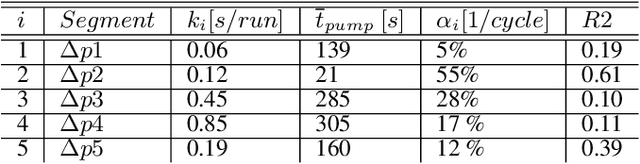
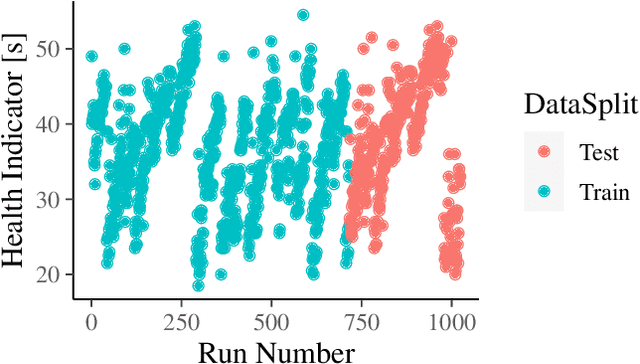
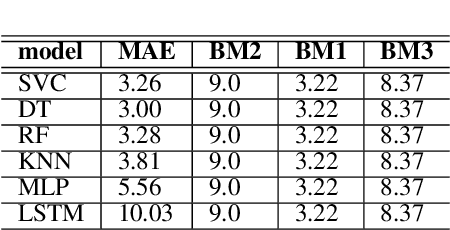
Coating chambers create thin layers that improve the mechanical and optical surface properties in jewelry production using physical vapor deposition. In such a process, evaporated material condensates on the walls of such chambers and, over time, causes mechanical defects and unstable processes. As a result, manufacturers perform extensive maintenance procedures to reduce production loss. Current rule-based maintenance strategies neglect the impact of specific recipes and the actual condition of the vacuum chamber. Our overall goal is to predict the future condition of the coating chamber to allow cost and quality optimized maintenance of the equipment. This paper describes the derivation of a novel health indicator that serves as a step toward condition-based maintenance for coating chambers. We indirectly use gas emissions of the chamber's contamination to evaluate the machine's condition. Our approach relies on process data and does not require additional hardware installation. Further, we evaluated multiple machine learning algorithms for a condition-based forecast of the health indicator that also reflects production planning. Our results show that models based on decision trees are the most effective and outperform all three benchmarks, improving at least $0.22$ in the mean average error. Our work paves the way for cost and quality optimized maintenance of coating applications.
Minimal-Configuration Anomaly Detection for IIoT Sensors
Oct 08, 2021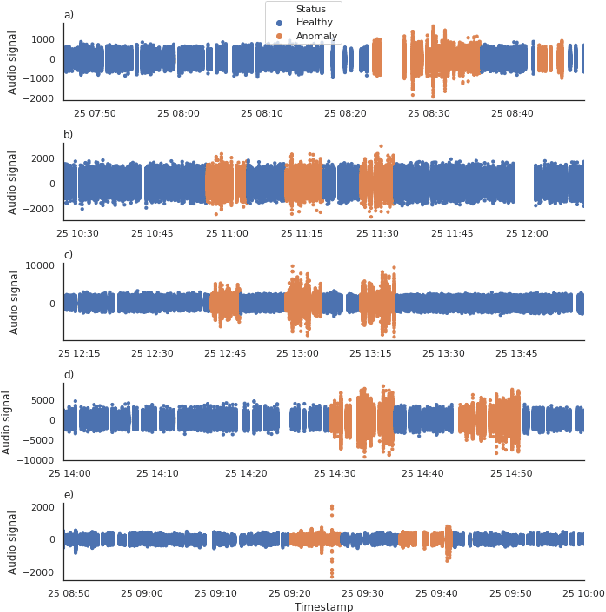
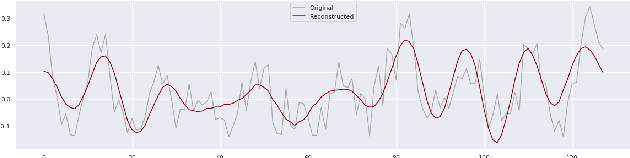
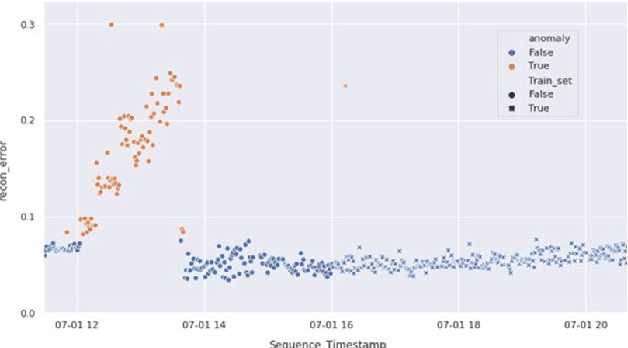
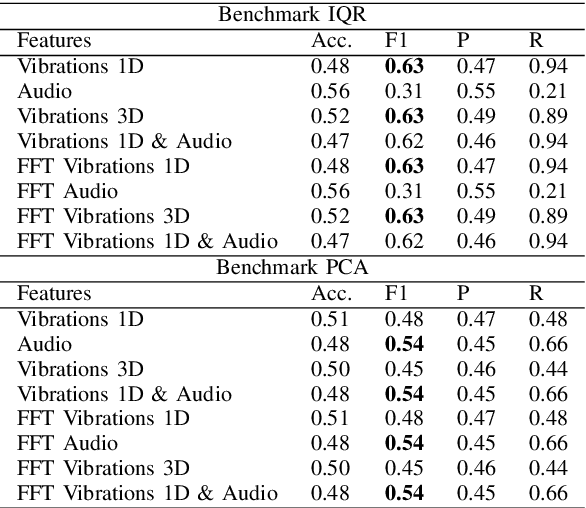
The increasing deployment of low-cost IoT sensor platforms in industry boosts the demand for anomaly detection solutions that fulfill two key requirements: minimal configuration effort and easy transferability across equipment. Recent advances in deep learning, especially long-short-term memory (LSTM) and autoencoders, offer promising methods for detecting anomalies in sensor data recordings. We compared autoencoders with various architectures such as deep neural networks (DNN), LSTMs and convolutional neural networks (CNN) using a simple benchmark dataset, which we generated by operating a peristaltic pump under various operating conditions and inducing anomalies manually. Our preliminary results indicate that a single model can detect anomalies under various operating conditions on a four-dimensional data set without any specific feature engineering for each operating condition. We consider this work as being the first step towards a generic anomaly detection method, which is applicable for a wide range of industrial equipment.
Predicting Time-to-Failure of Plasma Etching Equipment using Machine Learning
Apr 16, 2019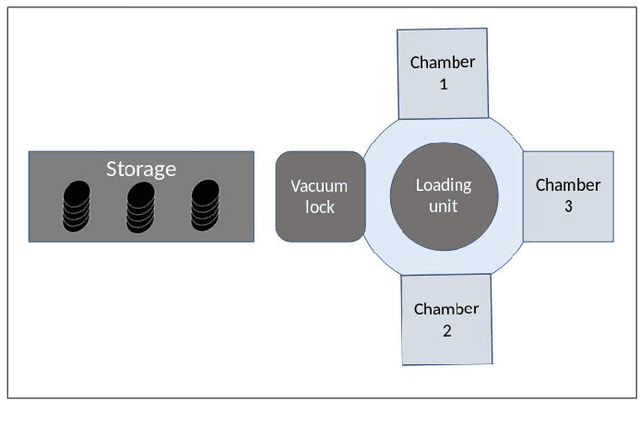
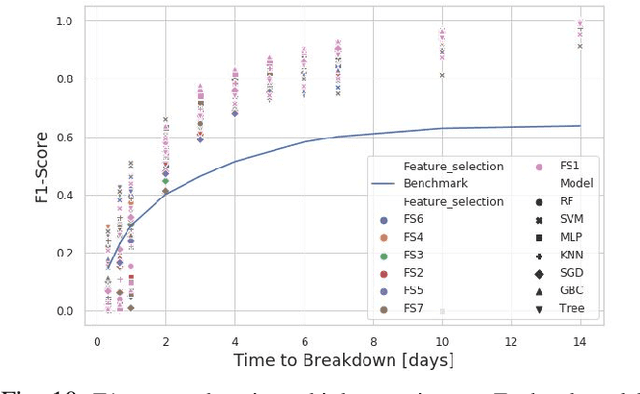
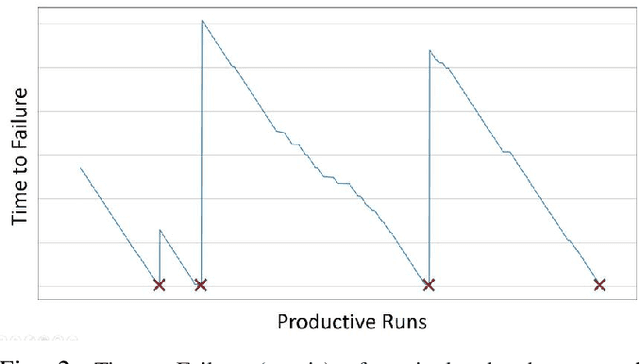
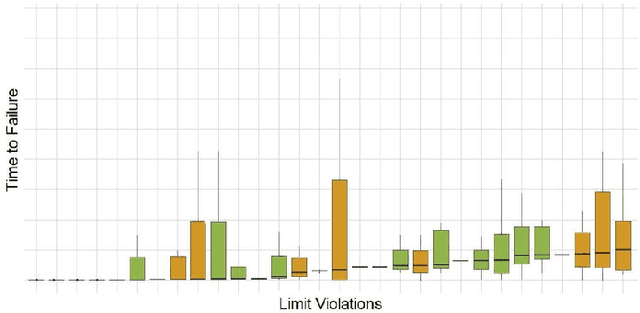
Predicting unscheduled breakdowns of plasma etching equipment can reduce maintenance costs and production losses in the semiconductor industry. However, plasma etching is a complex procedure and it is hard to capture all relevant equipment properties and behaviors in a single physical model. Machine learning offers an alternative for predicting upcoming machine failures based on relevant data points. In this paper, we describe three different machine learning tasks that can be used for that purpose: (i) predicting Time-To-Failure (TTF), (ii) predicting health state, and (iii) predicting TTF intervals of an equipment. Our results show that trained machine learning models can outperform benchmarks resembling human judgments in all three tasks. This suggests that machine learning offers a viable alternative to currently deployed plasma etching equipment maintenance strategies and decision making processes.