 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Offline-Frontier Shift: Diagnosing Distributional Limits in Generative Multi-Objective Optimization
Feb 11, 2026Offline multi-objective optimization (MOO) aims to recover Pareto-optimal designs given a finite, static dataset. Recent generative approaches, including diffusion models, show strong performance under hypervolume, yet their behavior under other established MOO metrics is less understood. We show that generative methods systematically underperform evolutionary alternatives with respect to other metrics, such as generational distance. We relate this failure mode to the offline-frontier shift, i.e., the displacement of the offline dataset from the Pareto front, which acts as a fundamental limitation in offline MOO. We argue that overcoming this limitation requires out-of-distribution sampling in objective space (via an integral probability metric) and empirically observe that generative methods remain conservatively close to the offline objective distribution. Our results position offline MOO as a distribution-shift--limited problem and provide a diagnostic lens for understanding when and why generative optimization methods fail.
Autoencoder based Anomaly Detection and Explained Fault Localization in Industrial Cooling Systems
Oct 14, 2022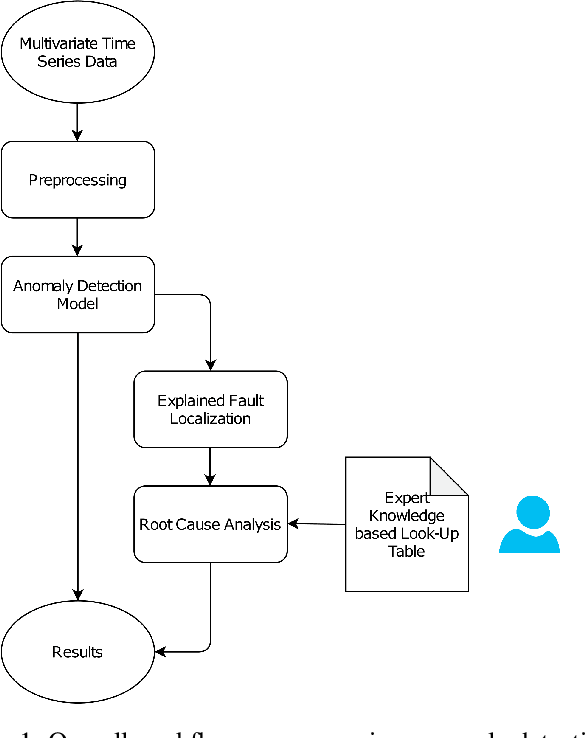
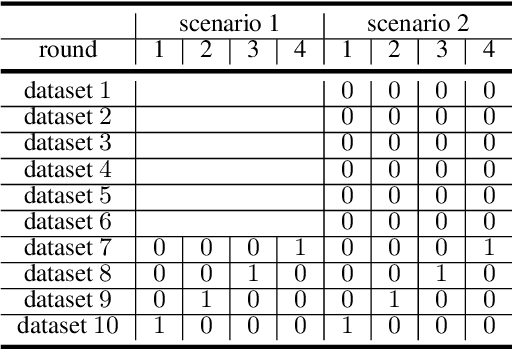
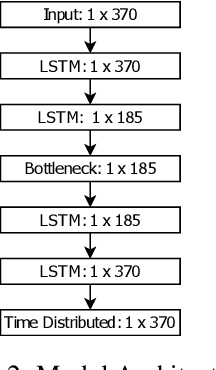
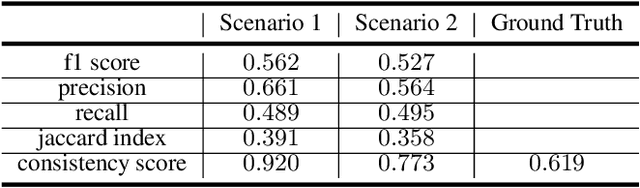
Anomaly detection in large industrial cooling systems is very challenging due to the high data dimensionality, inconsistent sensor recordings, and lack of labels. The state of the art for automated anomaly detection in these systems typically relies on expert knowledge and thresholds. However, data is viewed isolated and complex, multivariate relationships are neglected. In this work, we present an autoencoder based end-to-end workflow for anomaly detection suitable for multivariate time series data in large industrial cooling systems, including explained fault localization and root cause analysis based on expert knowledge. We identify system failures using a threshold on the total reconstruction error (autoencoder reconstruction error including all sensor signals). For fault localization, we compute the individual reconstruction error (autoencoder reconstruction error for each sensor signal) allowing us to identify the signals that contribute most to the total reconstruction error. Expert knowledge is provided via look-up table enabling root-cause analysis and assignment to the affected subsystem. We demonstrated our findings in a cooling system unit including 34 sensors over a 8-months time period using 4-fold cross validation approaches and automatically created labels based on thresholds provided by domain experts. Using 4-fold cross validation, we reached a F1-score of 0.56, whereas the autoencoder results showed a higher consistency score (CS of 0.92) compared to the automatically created labels (CS of 0.62) -- indicating that the anomaly is recognized in a very stable manner. The main anomaly was found by the autoencoder and automatically created labels and was also recorded in the log files. Further, the explained fault localization highlighted the most affected component for the main anomaly in a very consistent manner.
Evaluation of Hyperparameter-Optimization Approaches in an Industrial Federated Learning System
Oct 20, 2021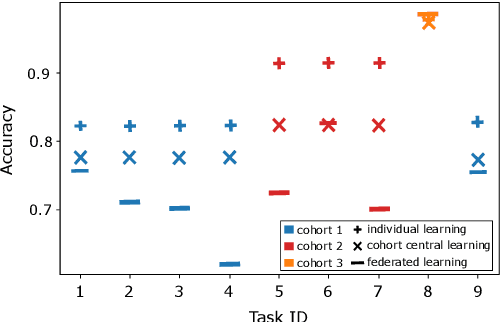
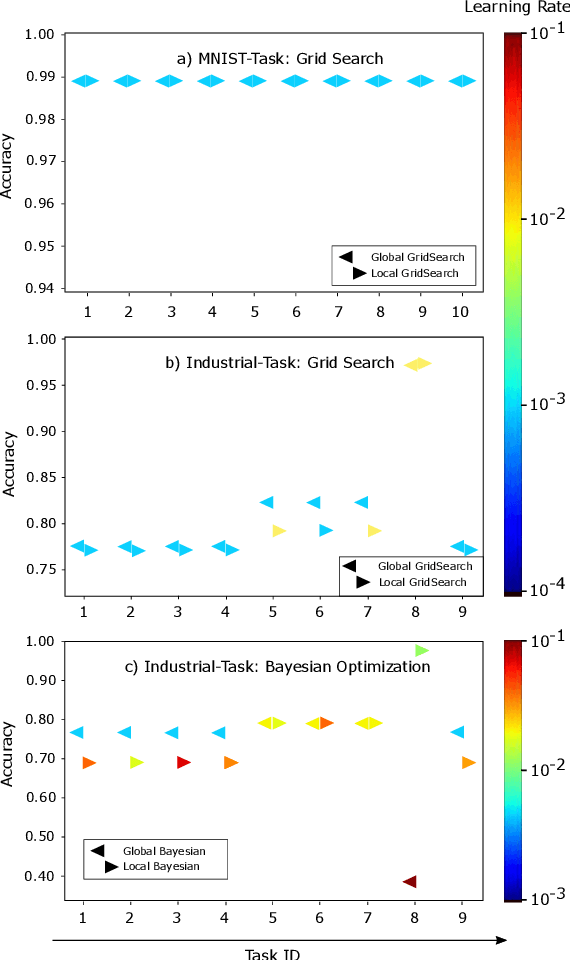
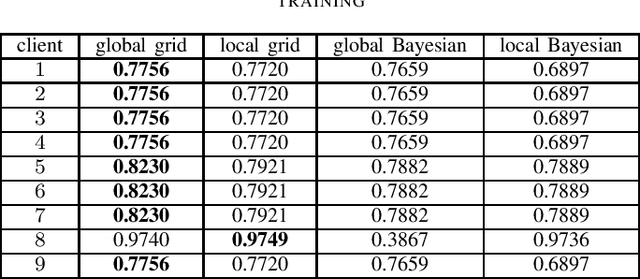
Federated Learning (FL) decouples model training from the need for direct access to the data and allows organizations to collaborate with industry partners to reach a satisfying level of performance without sharing vulnerable business information. The performance of a machine learning algorithm is highly sensitive to the choice of its hyperparameters. In an FL setting, hyperparameter optimization poses new challenges. In this work, we investigated the impact of different hyperparameter optimization approaches in an FL system. In an effort to reduce communication costs, a critical bottleneck in FL, we investigated a local hyperparameter optimization approach that -- in contrast to a global hyperparameter optimization approach -- allows every client to have its own hyperparameter configuration. We implemented these approaches based on grid search and Bayesian optimization and evaluated the algorithms on the MNIST data set using an i.i.d. partition and on an Internet of Things (IoT) sensor based industrial data set using a non-i.i.d. partition.