 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Clustering Algorithms for Statistical Features of Vibration Data Sets
May 11, 2023



Vibration-based condition monitoring systems are receiving increasing attention due to their ability to accurately identify different conditions by capturing dynamic features over a broad frequency range. However, there is little research on clustering approaches in vibration data and the resulting solutions are often optimized for a single data set. In this work, we present an extensive comparison of the clustering algorithms K-means clustering, OPTICS, and Gaussian mixture model clustering (GMM) applied to statistical features extracted from the time and frequency domains of vibration data sets. Furthermore, we investigate the influence of feature combinations, feature selection using principal component analysis (PCA), and the specified number of clusters on the performance of the clustering algorithms. We conducted this comparison in terms of a grid search using three different benchmark data sets. Our work showed that averaging (Mean, Median) and variance-based features (Standard Deviation, Interquartile Range) performed significantly better than shape-based features (Skewness, Kurtosis). In addition, K-means outperformed GMM slightly for these data sets, whereas OPTICS performed significantly worse. We were also able to show that feature combinations as well as PCA feature selection did not result in any significant performance improvements. With an increase in the specified number of clusters, clustering algorithms performed better, although there were some specific algorithmic restrictions.
Evaluation of Hyperparameter-Optimization Approaches in an Industrial Federated Learning System
Oct 20, 2021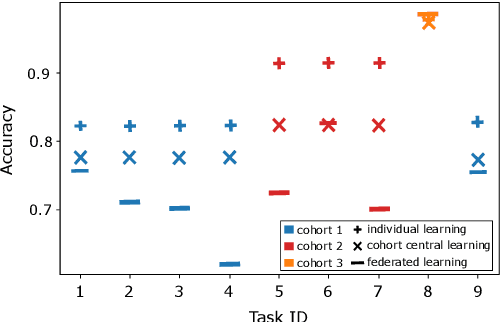
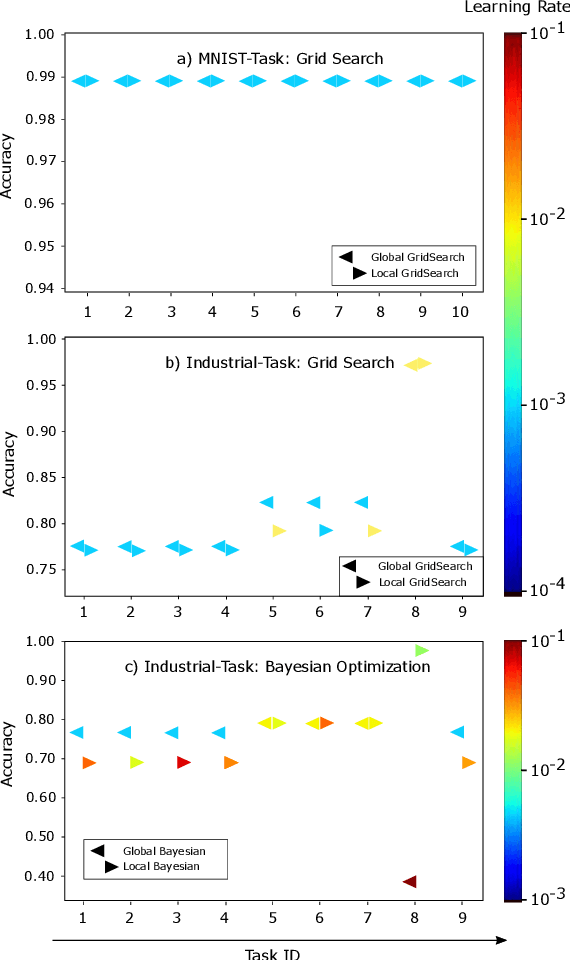
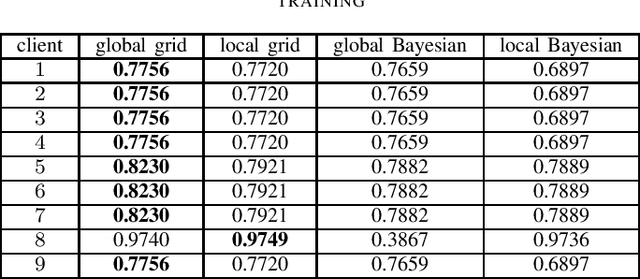
Federated Learning (FL) decouples model training from the need for direct access to the data and allows organizations to collaborate with industry partners to reach a satisfying level of performance without sharing vulnerable business information. The performance of a machine learning algorithm is highly sensitive to the choice of its hyperparameters. In an FL setting, hyperparameter optimization poses new challenges. In this work, we investigated the impact of different hyperparameter optimization approaches in an FL system. In an effort to reduce communication costs, a critical bottleneck in FL, we investigated a local hyperparameter optimization approach that -- in contrast to a global hyperparameter optimization approach -- allows every client to have its own hyperparameter configuration. We implemented these approaches based on grid search and Bayesian optimization and evaluated the algorithms on the MNIST data set using an i.i.d. partition and on an Internet of Things (IoT) sensor based industrial data set using a non-i.i.d. partition.