 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Clustering Algorithms for Statistical Features of Vibration Data Sets
May 11, 2023



Vibration-based condition monitoring systems are receiving increasing attention due to their ability to accurately identify different conditions by capturing dynamic features over a broad frequency range. However, there is little research on clustering approaches in vibration data and the resulting solutions are often optimized for a single data set. In this work, we present an extensive comparison of the clustering algorithms K-means clustering, OPTICS, and Gaussian mixture model clustering (GMM) applied to statistical features extracted from the time and frequency domains of vibration data sets. Furthermore, we investigate the influence of feature combinations, feature selection using principal component analysis (PCA), and the specified number of clusters on the performance of the clustering algorithms. We conducted this comparison in terms of a grid search using three different benchmark data sets. Our work showed that averaging (Mean, Median) and variance-based features (Standard Deviation, Interquartile Range) performed significantly better than shape-based features (Skewness, Kurtosis). In addition, K-means outperformed GMM slightly for these data sets, whereas OPTICS performed significantly worse. We were also able to show that feature combinations as well as PCA feature selection did not result in any significant performance improvements. With an increase in the specified number of clusters, clustering algorithms performed better, although there were some specific algorithmic restrictions.
Federated Learning for Predictive Maintenance and Quality Inspection in Industrial Applications
Apr 21, 2023Data-driven machine learning is playing a crucial role in the advancements of Industry 4.0, specifically in enhancing predictive maintenance and quality inspection. Federated learning (FL) enables multiple participants to develop a machine learning model without compromising the privacy and confidentiality of their data. In this paper, we evaluate the performance of different FL aggregation methods and compare them to central and local training approaches. Our study is based on four datasets with varying data distributions. The results indicate that the performance of FL is highly dependent on the data and its distribution among clients. In some scenarios, FL can be an effective alternative to traditional central or local training methods. Additionally, we introduce a new federated learning dataset from a real-world quality inspection setting.
Autoencoder based Anomaly Detection and Explained Fault Localization in Industrial Cooling Systems
Oct 14, 2022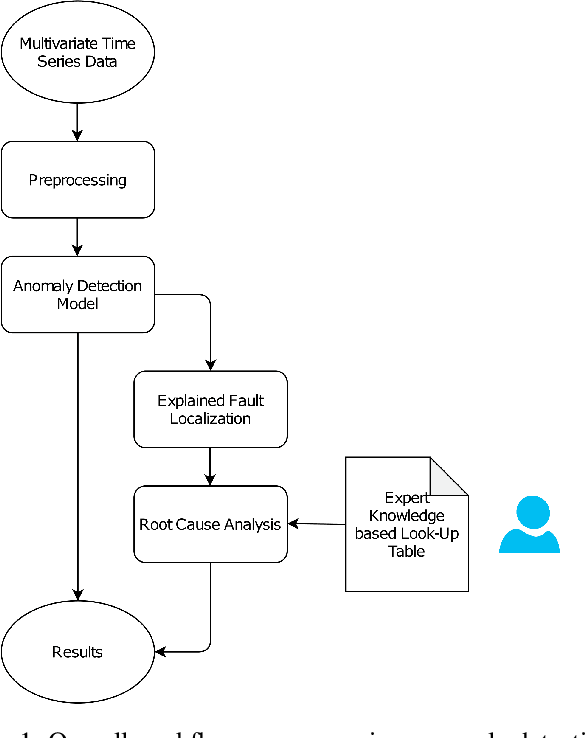
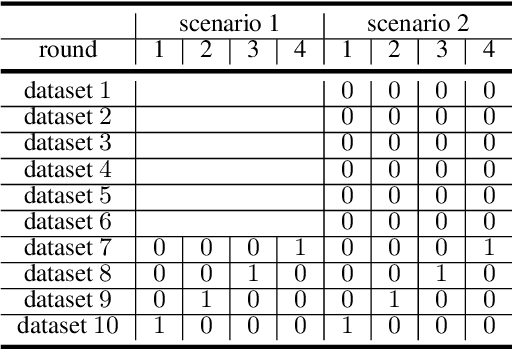
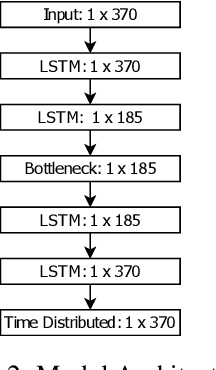
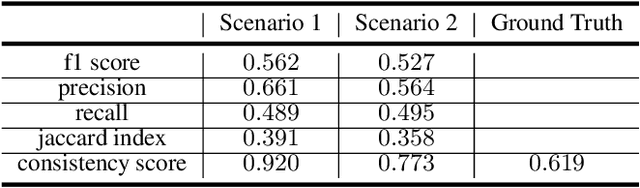
Anomaly detection in large industrial cooling systems is very challenging due to the high data dimensionality, inconsistent sensor recordings, and lack of labels. The state of the art for automated anomaly detection in these systems typically relies on expert knowledge and thresholds. However, data is viewed isolated and complex, multivariate relationships are neglected. In this work, we present an autoencoder based end-to-end workflow for anomaly detection suitable for multivariate time series data in large industrial cooling systems, including explained fault localization and root cause analysis based on expert knowledge. We identify system failures using a threshold on the total reconstruction error (autoencoder reconstruction error including all sensor signals). For fault localization, we compute the individual reconstruction error (autoencoder reconstruction error for each sensor signal) allowing us to identify the signals that contribute most to the total reconstruction error. Expert knowledge is provided via look-up table enabling root-cause analysis and assignment to the affected subsystem. We demonstrated our findings in a cooling system unit including 34 sensors over a 8-months time period using 4-fold cross validation approaches and automatically created labels based on thresholds provided by domain experts. Using 4-fold cross validation, we reached a F1-score of 0.56, whereas the autoencoder results showed a higher consistency score (CS of 0.92) compared to the automatically created labels (CS of 0.62) -- indicating that the anomaly is recognized in a very stable manner. The main anomaly was found by the autoencoder and automatically created labels and was also recorded in the log files. Further, the explained fault localization highlighted the most affected component for the main anomaly in a very consistent manner.
Smart Active Sampling to enhance Quality Assurance Efficiency
Sep 23, 2022
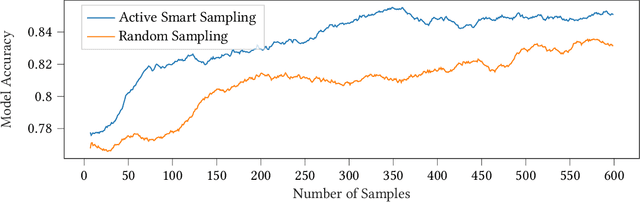

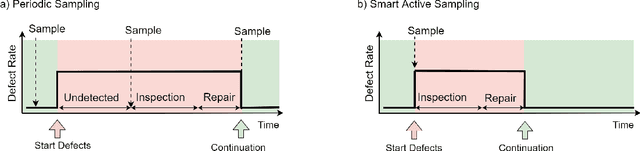
We propose a new sampling strategy, called smart active sapling, for quality inspections outside the production line. Based on the principles of active learning a machine learning model decides which samples are sent to quality inspection. On the one hand, this minimizes the production of scrap parts due to earlier detection of quality violations. On the other hand, quality inspection costs are reduced for smooth operation.
Evaluation of Hyperparameter-Optimization Approaches in an Industrial Federated Learning System
Oct 20, 2021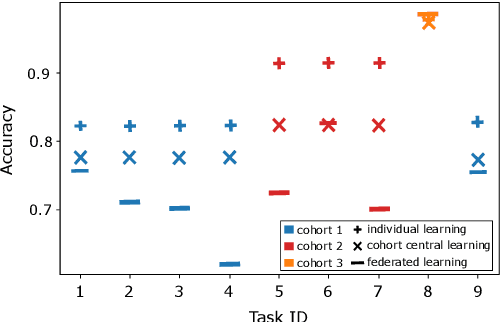
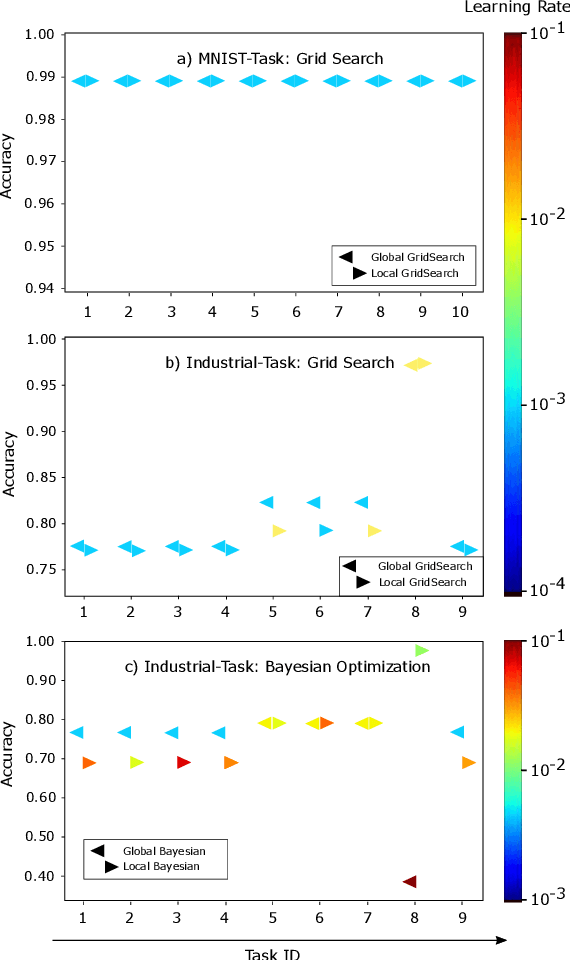
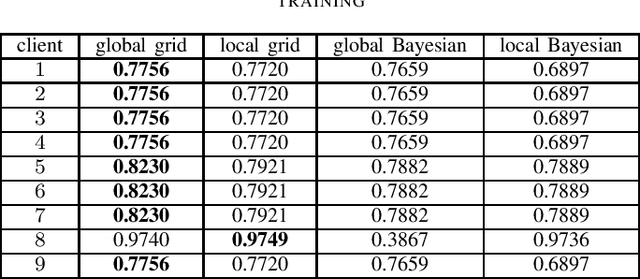
Federated Learning (FL) decouples model training from the need for direct access to the data and allows organizations to collaborate with industry partners to reach a satisfying level of performance without sharing vulnerable business information. The performance of a machine learning algorithm is highly sensitive to the choice of its hyperparameters. In an FL setting, hyperparameter optimization poses new challenges. In this work, we investigated the impact of different hyperparameter optimization approaches in an FL system. In an effort to reduce communication costs, a critical bottleneck in FL, we investigated a local hyperparameter optimization approach that -- in contrast to a global hyperparameter optimization approach -- allows every client to have its own hyperparameter configuration. We implemented these approaches based on grid search and Bayesian optimization and evaluated the algorithms on the MNIST data set using an i.i.d. partition and on an Internet of Things (IoT) sensor based industrial data set using a non-i.i.d. partition.
Minimal-Configuration Anomaly Detection for IIoT Sensors
Oct 08, 2021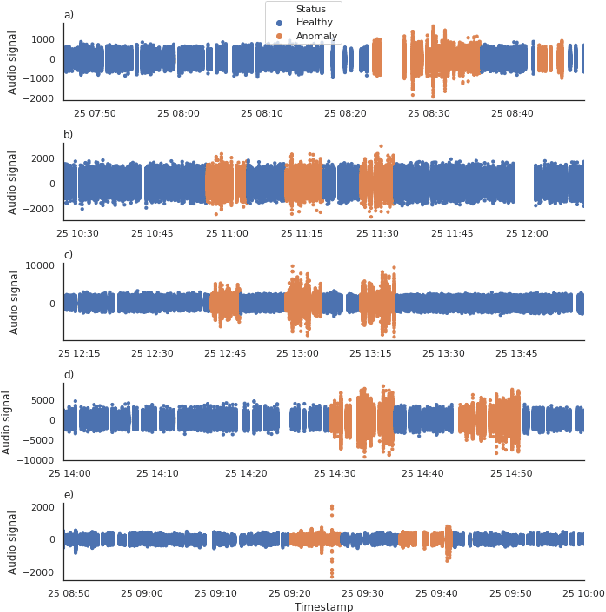
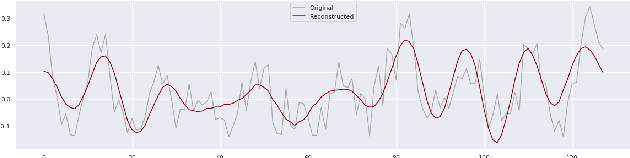
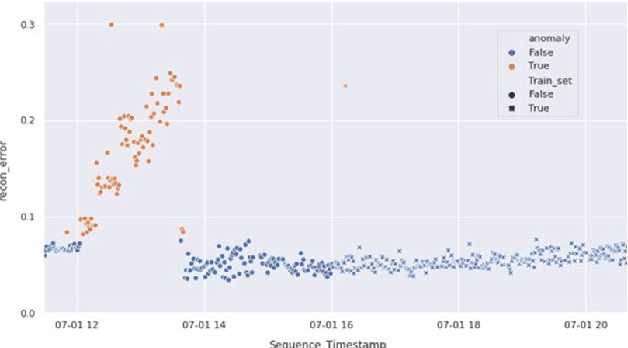
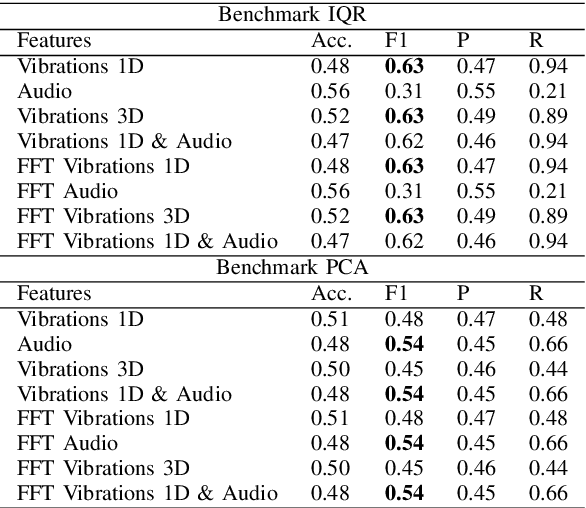
The increasing deployment of low-cost IoT sensor platforms in industry boosts the demand for anomaly detection solutions that fulfill two key requirements: minimal configuration effort and easy transferability across equipment. Recent advances in deep learning, especially long-short-term memory (LSTM) and autoencoders, offer promising methods for detecting anomalies in sensor data recordings. We compared autoencoders with various architectures such as deep neural networks (DNN), LSTMs and convolutional neural networks (CNN) using a simple benchmark dataset, which we generated by operating a peristaltic pump under various operating conditions and inducing anomalies manually. Our preliminary results indicate that a single model can detect anomalies under various operating conditions on a four-dimensional data set without any specific feature engineering for each operating condition. We consider this work as being the first step towards a generic anomaly detection method, which is applicable for a wide range of industrial equipment.
Towards Robust and Transferable IIoT Sensor based Anomaly Classification using Artificial Intelligence
Oct 07, 2021
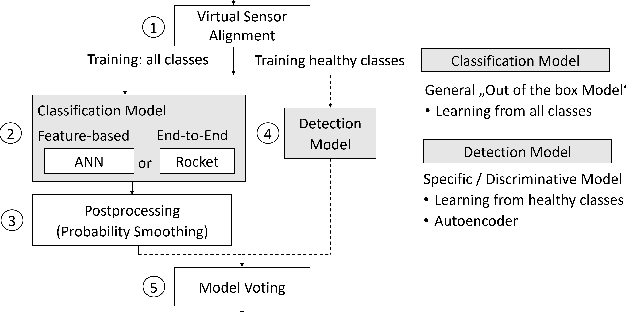
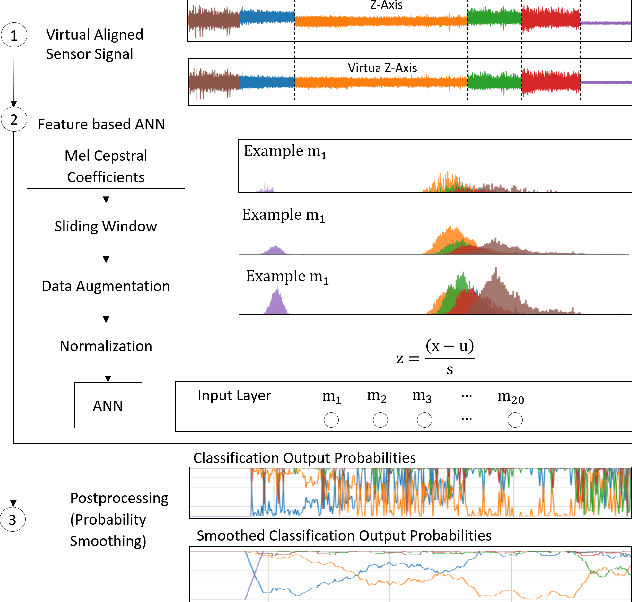
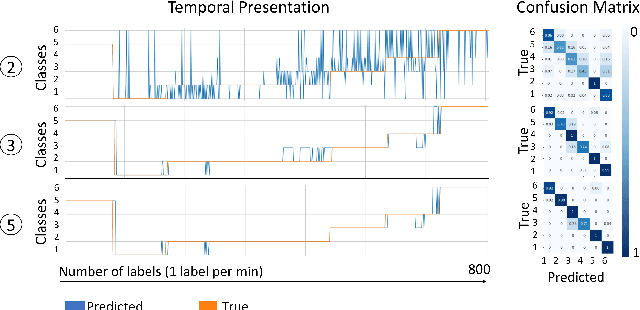
The increasing deployment of low-cost industrial IoT (IIoT) sensor platforms on industrial assets enables great opportunities for anomaly classification in industrial plants. The performance of such a classification model depends highly on the available training data. Models perform well when the training data comes from the same machine. However, as soon as the machine is changed, repaired, or put into operation in a different environment, the prediction often fails. For this reason, we investigate whether it is feasible to have a robust and transferable method for AI based anomaly classification using different models and pre-processing steps on centrifugal pumps which are dismantled and put back into operation in the same as well as in different environments. Further, we investigate the model performance on different pumps from the same type compared to those from the training data.
Industrial Federated Learning -- Requirements and System Design
May 14, 2020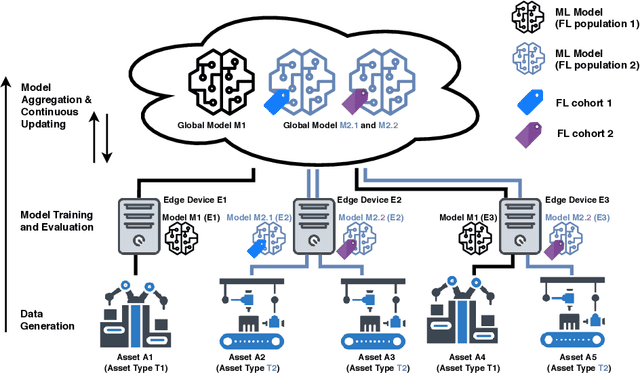
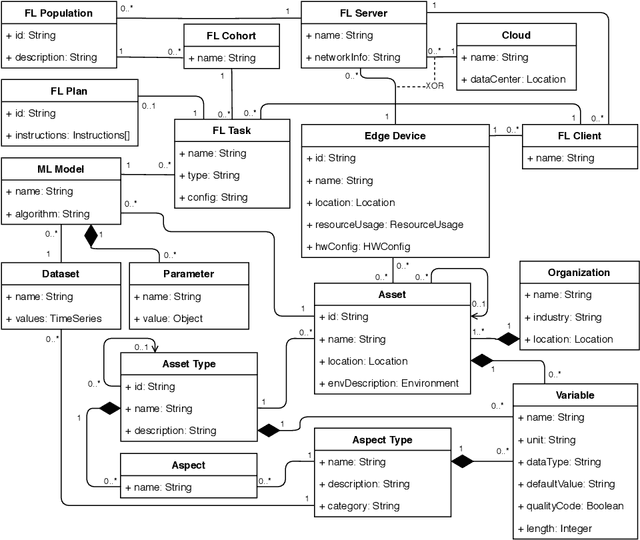
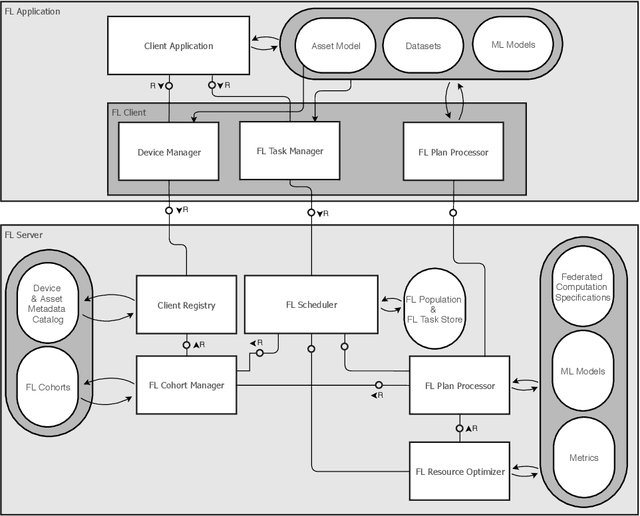
Federated Learning (FL) is a very promising approach for improving decentralized Machine Learning (ML) models by exchanging knowledge between participating clients without revealing private data. Nevertheless, FL is still not tailored to the industrial context as strong data similarity is assumed for all FL tasks. This is rarely the case in industrial machine data with variations in machine type, operational- and environmental conditions. Therefore, we introduce an Industrial Federated Learning (IFL) system supporting knowledge exchange in continuously evaluated and updated FL cohorts of learning tasks with sufficient data similarity. This enables optimal collaboration of business partners in common ML problems, prevents negative knowledge transfer, and ensures resource optimization of involved edge devices.
Combining Heterogeneously Labeled Datasets For Training Segmentation Networks
Jul 24, 2018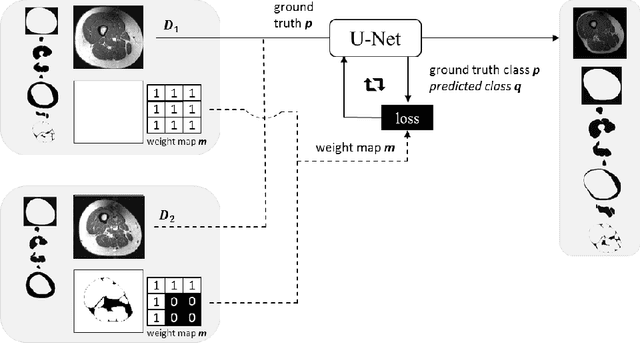

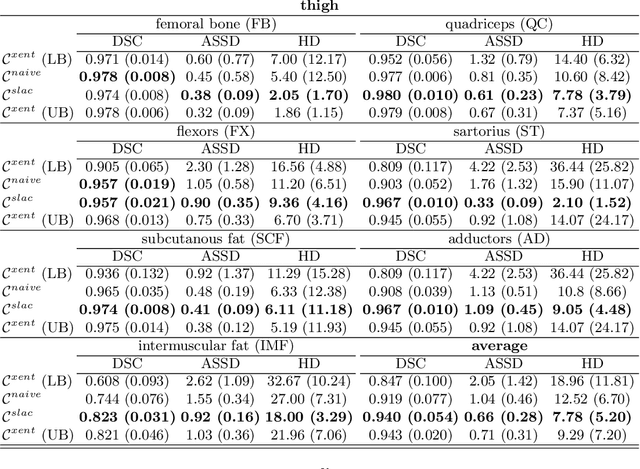
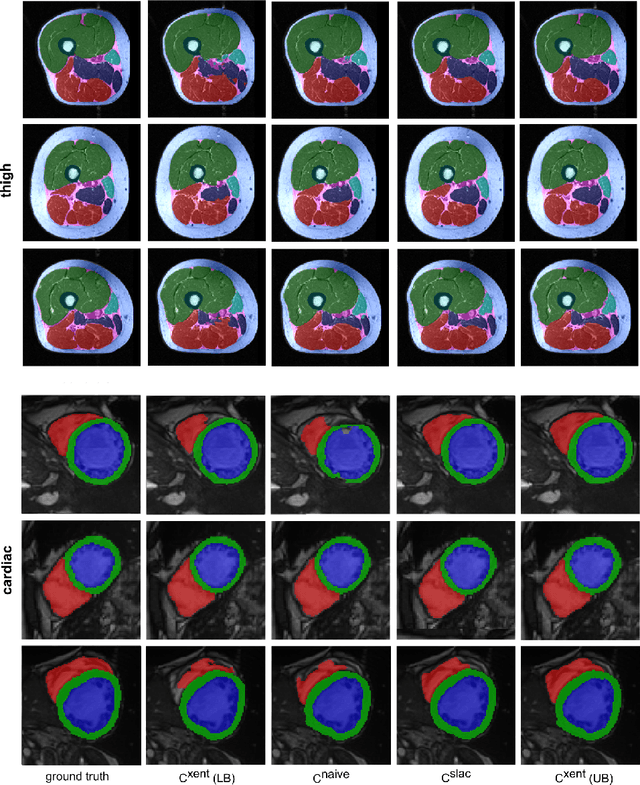
Accurate segmentation of medical images is an important step towards analyzing and tracking disease related morphological alterations in the anatomy. Convolutional neural networks (CNNs) have recently emerged as a powerful tool for many segmentation tasks in medical imaging. The performance of CNNs strongly depends on the size of the training data and combining data from different sources is an effective strategy for obtaining larger training datasets. However, this is often challenged by heterogeneous labeling of the datasets. For instance, one of the dataset may be missing labels or a number of labels may have been combined into a super label. In this work we propose a cost function which allows integration of multiple datasets with heterogeneous label subsets into a joint training. We evaluated the performance of this strategy on thigh MR and a cardiac MR datasets in which we artificially merged labels for half of the data. We found the proposed cost function substantially outperforms a naive masking approach, obtaining results very close to using the full annotations.