 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaSplit: A Hardware-Software Co-Design Framework for Energy-Aware Inference on Edge
Oct 31, 2024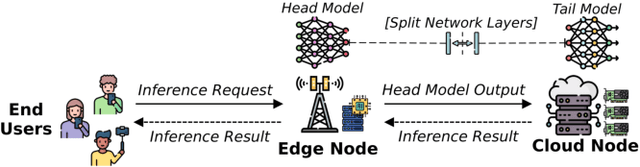
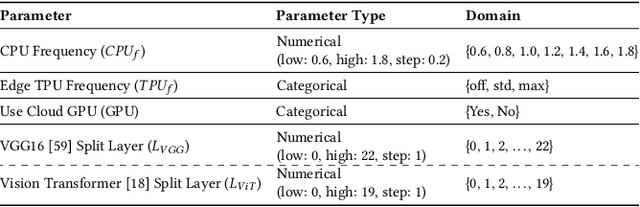

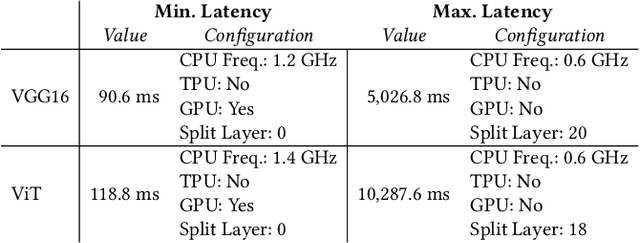
The deployment of ML models on edge devices is challenged by limited computational resources and energy availability. While split computing enables the decomposition of large neural networks (NNs) and allows partial computation on both edge and cloud devices, identifying the most suitable split layer and hardware configurations is a non-trivial task. This process is in fact hindered by the large configuration space, the non-linear dependencies between software and hardware parameters, the heterogeneous hardware and energy characteristics, and the dynamic workload conditions. To overcome this challenge, we propose DynaSplit, a two-phase framework that dynamically configures parameters across both software (i.e., split layer) and hardware (e.g., accelerator usage, CPU frequency). During the Offline Phase, we solve a multi-objective optimization problem with a meta-heuristic approach to discover optimal settings. During the Online Phase, a scheduling algorithm identifies the most suitable settings for an incoming inference request and configures the system accordingly. We evaluate DynaSplit using popular pre-trained NNs on a real-world testbed. Experimental results show a reduction in energy consumption up to 72% compared to cloud-only computation, while meeting ~90% of user request's latency threshold compared to baselines.
Decentralized Coordination of Distributed Energy Resources through Local Energy Markets and Deep Reinforcement Learning
Apr 19, 2024



As the energy landscape evolves toward sustainability, the accelerating integration of distributed energy resources poses challenges to the operability and reliability of the electricity grid. One significant aspect of this issue is the notable increase in net load variability at the grid edge. Transactive energy, implemented through local energy markets, has recently garnered attention as a promising solution to address the grid challenges in the form of decentralized, indirect demand response on a community level. Given the nature of these challenges, model-free control approaches, such as deep reinforcement learning, show promise for the decentralized automation of participation within this context. Existing studies at the intersection of transactive energy and model-free control primarily focus on socioeconomic and self-consumption metrics, overlooking the crucial goal of reducing community-level net load variability. This study addresses this gap by training a set of deep reinforcement learning agents to automate end-user participation in ALEX, an economy-driven local energy market. In this setting, agents do not share information and only prioritize individual bill optimization. The study unveils a clear correlation between bill reduction and reduced net load variability in this setup. The impact on net load variability is assessed over various time horizons using metrics such as ramping rate, daily and monthly load factor, as well as daily average and total peak export and import on an open-source dataset. Agents are then benchmarked against several baselines, with their performance levels showing promising results, approaching those of a near-optimal dynamic programming benchmark.
Forecasting Photovoltaic Power Production using a Deep Learning Sequence to Sequence Model with Attention
Aug 06, 2020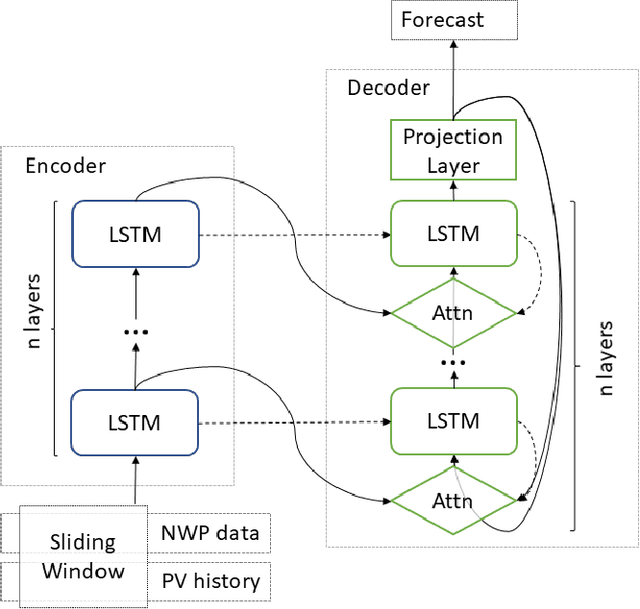


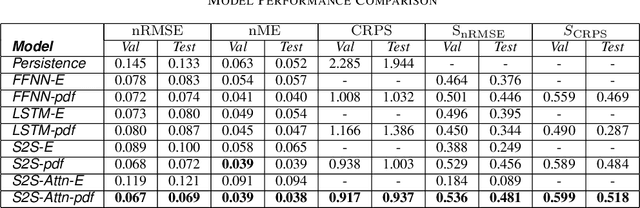
Rising penetration levels of (residential) photovoltaic (PV) power as distributed energy resource pose a number of challenges to the electricity infrastructure. High quality, general tools to provide accurate forecasts of power production are urgently needed. In this article, we propose a supervised deep learning model for end-to-end forecasting of PV power production. The proposed model is based on two seminal concepts that led to significant performance improvements of deep learning approaches in other sequence-related fields, but not yet in the area of time series prediction: the sequence to sequence architecture and attention mechanism as a context generator. The proposed model leverages numerical weather predictions and high-resolution historical measurements to forecast a binned probability distribution over the prognostic time intervals, rather than the expected values of the prognostic variable. This design offers significant performance improvements compared to common baseline approaches, such as fully connected neural networks and one-block long short-term memory architectures. Using normalized root mean square error based forecast skill score as a performance indicator, the proposed approach is compared to other models. The results show that the new design performs at or above the current state of the art of PV power forecasting.