 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreenServ: Energy-Efficient Context-Aware Dynamic Routing for Multi-Model LLM Inference
Jan 24, 2026Large language models (LLMs) demonstrate remarkable capabilities, but their broad deployment is limited by significant computational resource demands, particularly energy consumption during inference. Static, one-model-fits-all inference strategies are often inefficient, as they do not exploit the diverse range of available models or adapt to varying query requirements. This paper presents GreenServ, a dynamic, context-aware routing framework that optimizes the trade-off between inference accuracy and energy efficiency. GreenServ extracts lightweight contextual features from each query, including task type, semantic cluster, and text complexity, and routes queries to the most suitable model from a heterogeneous pool, based on observed accuracy and energy usage. We employ a multi-armed bandit approach to learn adaptive routing policies online. This approach operates under partial feedback, eliminates the need for extensive offline calibration, and streamlines the integration of new models into the inference pipeline. We evaluated GreenServ across five benchmark tasks and a pool of 16 contemporary open-access LLMs. Experimental results show that GreenServ consistently outperforms static (single-model) and random baselines. In particular, compared to random routing, GreenServ achieved a 22% increase in accuracy while reducing cumulative energy consumption by 31%. Finally, we evaluated GreenServ with RouterBench, achieving an average accuracy of 71.7% with a peak accuracy of 75.7%. All artifacts are open-source and available as an anonymous repository for review purposes here: https://anonymous.4open.science/r/llm-inference-router-EBEA/README.md
DynaSplit: A Hardware-Software Co-Design Framework for Energy-Aware Inference on Edge
Oct 31, 2024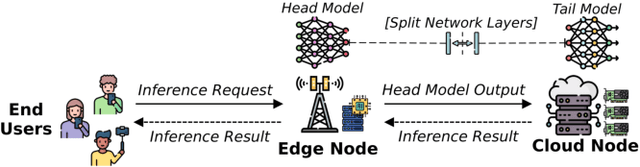
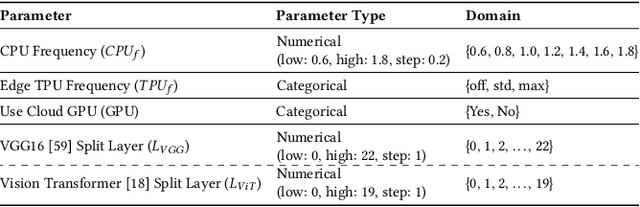

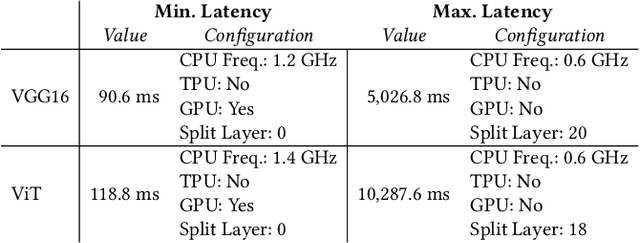
The deployment of ML models on edge devices is challenged by limited computational resources and energy availability. While split computing enables the decomposition of large neural networks (NNs) and allows partial computation on both edge and cloud devices, identifying the most suitable split layer and hardware configurations is a non-trivial task. This process is in fact hindered by the large configuration space, the non-linear dependencies between software and hardware parameters, the heterogeneous hardware and energy characteristics, and the dynamic workload conditions. To overcome this challenge, we propose DynaSplit, a two-phase framework that dynamically configures parameters across both software (i.e., split layer) and hardware (e.g., accelerator usage, CPU frequency). During the Offline Phase, we solve a multi-objective optimization problem with a meta-heuristic approach to discover optimal settings. During the Online Phase, a scheduling algorithm identifies the most suitable settings for an incoming inference request and configures the system accordingly. We evaluate DynaSplit using popular pre-trained NNs on a real-world testbed. Experimental results show a reduction in energy consumption up to 72% compared to cloud-only computation, while meeting ~90% of user request's latency threshold compared to baselines.
A Decentralized and Self-Adaptive Approach for Monitoring Volatile Edge Environments
May 13, 2024Edge computing provides resources for IoT workloads at the network edge. Monitoring systems are vital for efficiently managing resources and application workloads by collecting, storing, and providing relevant information about the state of the resources. However, traditional monitoring systems have a centralized architecture for both data plane and control plane, which increases latency, creates a failure bottleneck, and faces challenges in providing quick and trustworthy data in volatile edge environments, especially where infrastructures are often built upon failure-prone, unsophisticated computing and network resources. Thus, we propose DEMon, a decentralized, self-adaptive monitoring system for edge. DEMon leverages the stochastic gossip communication protocol at its core. It develops efficient protocols for information dissemination, communication, and retrieval, avoiding a single point of failure and ensuring fast and trustworthy data access. Its decentralized control enables self-adaptive management of monitoring parameters, addressing the trade-offs between the quality of service of monitoring and resource consumption. We implement the proposed system as a lightweight and portable container-based system and evaluate it through experiments. We also present a use case demonstrating its feasibility. The results show that DEMon efficiently disseminates and retrieves the monitoring information, addressing the challenges of edge monitoring.
An Energy-Aware Approach to Design Self-Adaptive AI-based Applications on the Edge
Aug 31, 2023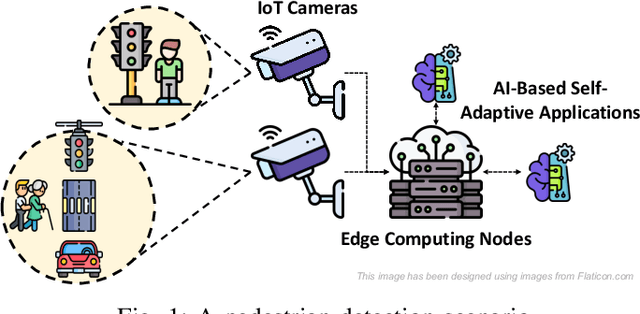
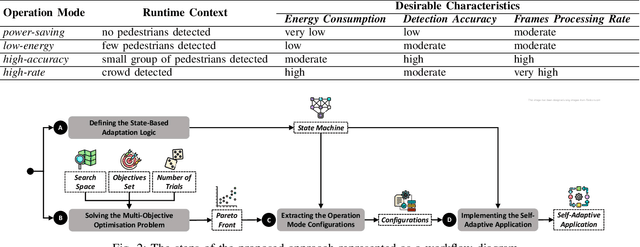
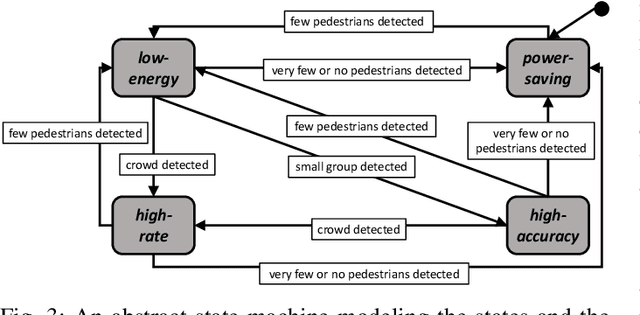
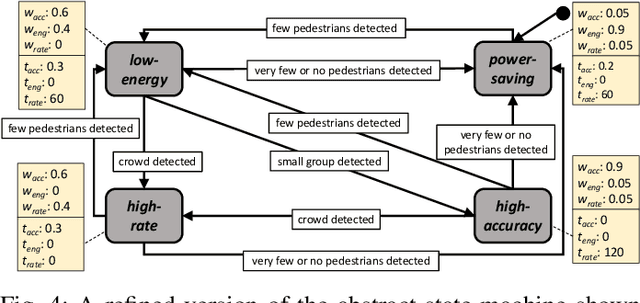
The advent of edge devices dedicated to machine learning tasks enabled the execution of AI-based applications that efficiently process and classify the data acquired by the resource-constrained devices populating the Internet of Things. The proliferation of such applications (e.g., critical monitoring in smart cities) demands new strategies to make these systems also sustainable from an energetic point of view. In this paper, we present an energy-aware approach for the design and deployment of self-adaptive AI-based applications that can balance application objectives (e.g., accuracy in object detection and frames processing rate) with energy consumption. We address the problem of determining the set of configurations that can be used to self-adapt the system with a meta-heuristic search procedure that only needs a small number of empirical samples. The final set of configurations are selected using weighted gray relational analysis, and mapped to the operation modes of the self-adaptive application. We validate our approach on an AI-based application for pedestrian detection. Results show that our self-adaptive application can outperform non-adaptive baseline configurations by saving up to 81\% of energy while loosing only between 2% and 6% in accuracy.
Cloud Failure Prediction with Hierarchical Temporary Memory: An Empirical Assessment
Oct 06, 2021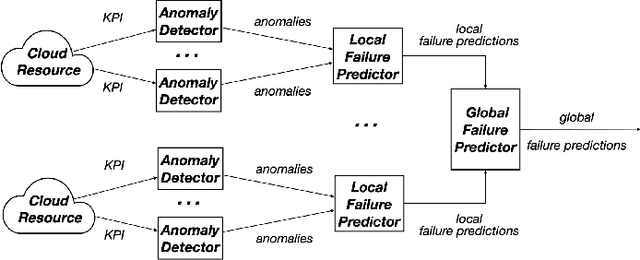
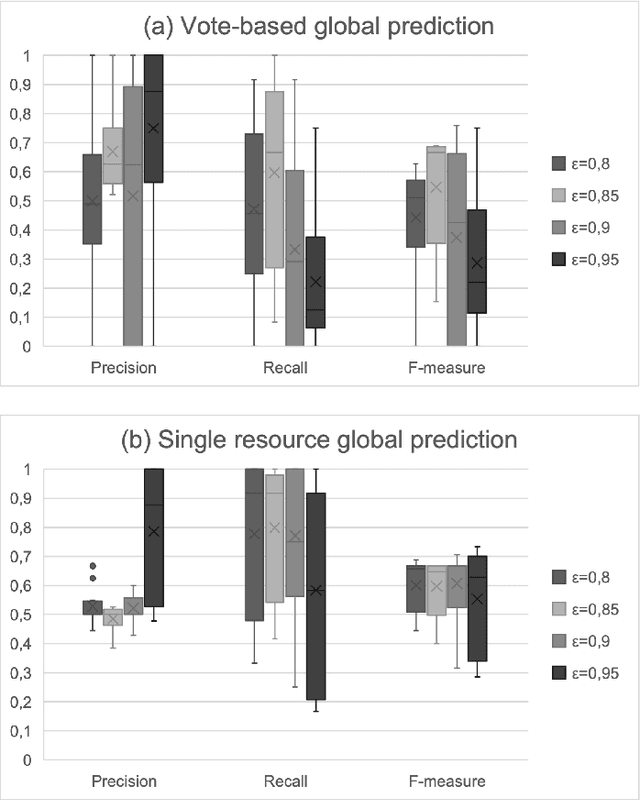
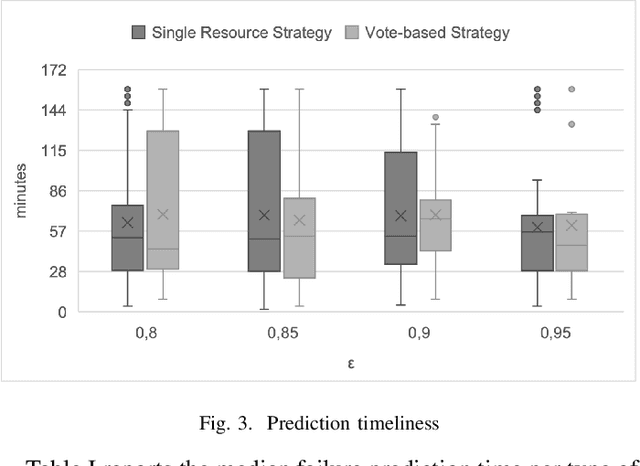
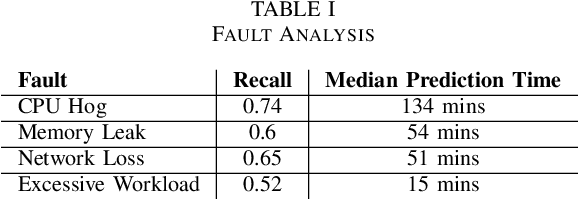
Hierarchical Temporary Memory (HTM) is an unsupervised learning algorithm inspired by the features of the neocortex that can be used to continuously process stream data and detect anomalies, without requiring a large amount of data for training nor requiring labeled data. HTM is also able to continuously learn from samples, providing a model that is always up-to-date with respect to observations. These characteristics make HTM particularly suitable for supporting online failure prediction in cloud systems, which are systems with a dynamically changing behavior that must be monitored to anticipate problems. This paper presents the first systematic study that assesses HTM in the context of failure prediction. The results that we obtained considering 72 configurations of HTM applied to 12 different types of faults introduced in the Clearwater cloud system show that HTM can help to predict failures with sufficient effectiveness (F-measure = 0.76), representing an interesting practical alternative to (semi-)supervised algorithms.