 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Energy-Aware Approach to Design Self-Adaptive AI-based Applications on the Edge
Aug 31, 2023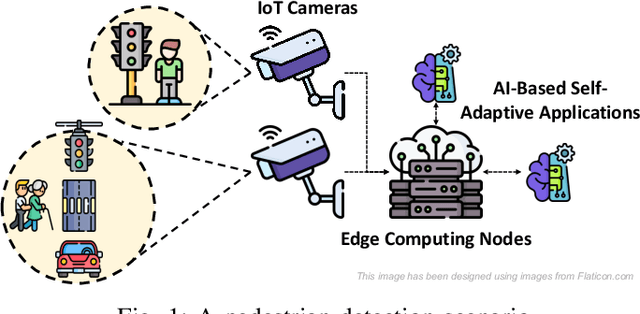
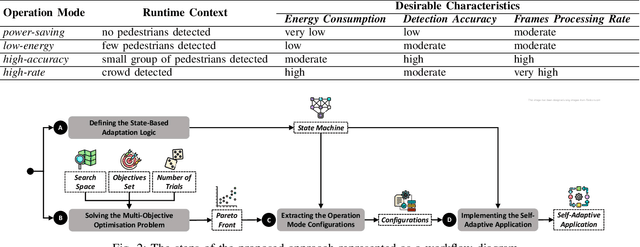
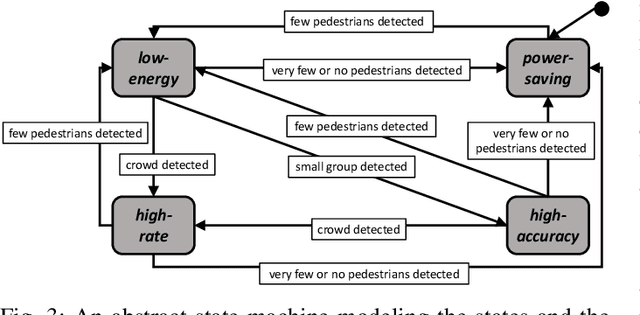
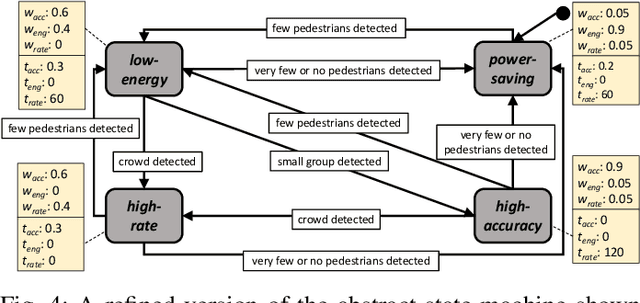
The advent of edge devices dedicated to machine learning tasks enabled the execution of AI-based applications that efficiently process and classify the data acquired by the resource-constrained devices populating the Internet of Things. The proliferation of such applications (e.g., critical monitoring in smart cities) demands new strategies to make these systems also sustainable from an energetic point of view. In this paper, we present an energy-aware approach for the design and deployment of self-adaptive AI-based applications that can balance application objectives (e.g., accuracy in object detection and frames processing rate) with energy consumption. We address the problem of determining the set of configurations that can be used to self-adapt the system with a meta-heuristic search procedure that only needs a small number of empirical samples. The final set of configurations are selected using weighted gray relational analysis, and mapped to the operation modes of the self-adaptive application. We validate our approach on an AI-based application for pedestrian detection. Results show that our self-adaptive application can outperform non-adaptive baseline configurations by saving up to 81\% of energy while loosing only between 2% and 6% in accuracy.
Homogenization of Existing Inertial-Based Datasets to Support Human Activity Recognition
Jan 17, 2022Several techniques have been proposed to address the problem of recognizing activities of daily living from signals. Deep learning techniques applied to inertial signals have proven to be effective, achieving significant classification accuracy. Recently, research in human activity recognition (HAR) models has been almost totally model-centric. It has been proven that the number of training samples and their quality are critical for obtaining deep learning models that both perform well independently of their architecture, and that are more robust to intraclass variability and interclass similarity. Unfortunately, publicly available datasets do not always contain hight quality data and a sufficiently large and diverse number of samples (e.g., number of subjects, type of activity performed, and duration of trials). Furthermore, datasets are heterogeneous among them and therefore cannot be trivially combined to obtain a larger set. The final aim of our work is the definition and implementation of a platform that integrates datasets of inertial signals in order to make available to the scientific community large datasets of homogeneous signals, enriched, when possible, with context information (e.g., characteristics of the subjects and device position). The main focus of our platform is to emphasise data quality, which is essential for training efficient models.
Cloud Failure Prediction with Hierarchical Temporary Memory: An Empirical Assessment
Oct 06, 2021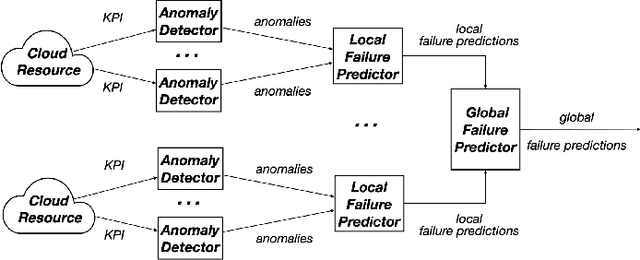
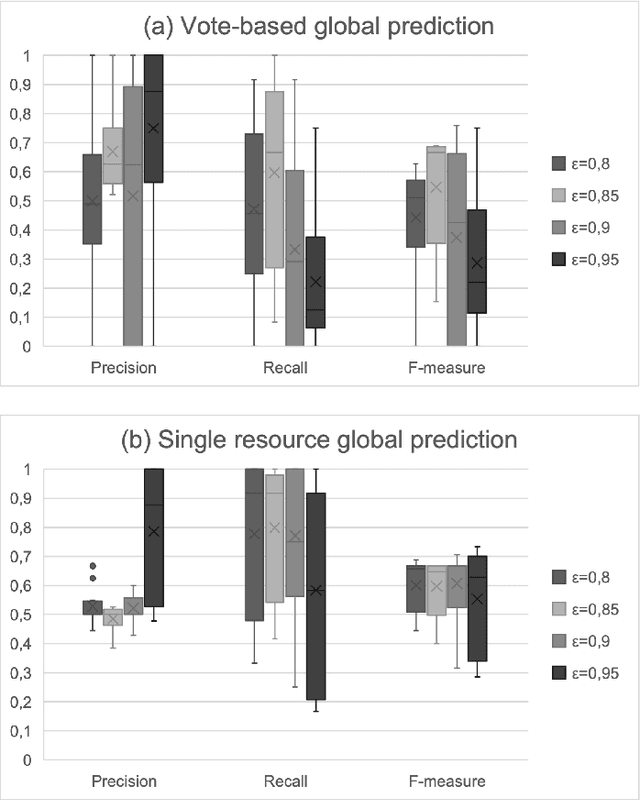
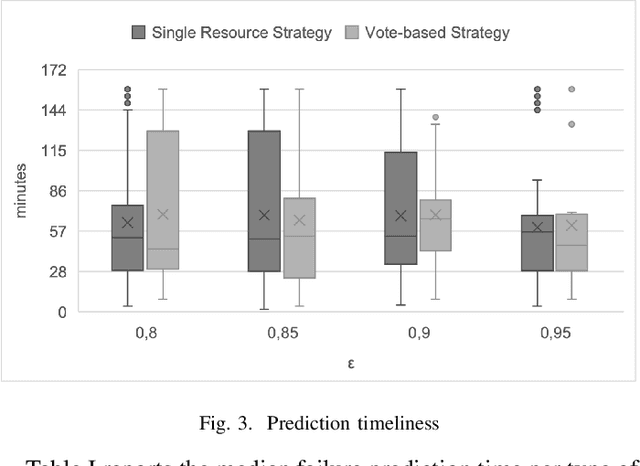
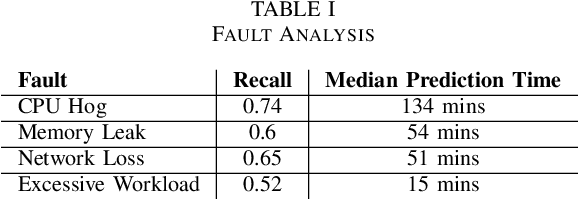
Hierarchical Temporary Memory (HTM) is an unsupervised learning algorithm inspired by the features of the neocortex that can be used to continuously process stream data and detect anomalies, without requiring a large amount of data for training nor requiring labeled data. HTM is also able to continuously learn from samples, providing a model that is always up-to-date with respect to observations. These characteristics make HTM particularly suitable for supporting online failure prediction in cloud systems, which are systems with a dynamically changing behavior that must be monitored to anticipate problems. This paper presents the first systematic study that assesses HTM in the context of failure prediction. The results that we obtained considering 72 configurations of HTM applied to 12 different types of faults introduced in the Clearwater cloud system show that HTM can help to predict failures with sufficient effectiveness (F-measure = 0.76), representing an interesting practical alternative to (semi-)supervised algorithms.
Personalization in Human Activity Recognition
Sep 01, 2020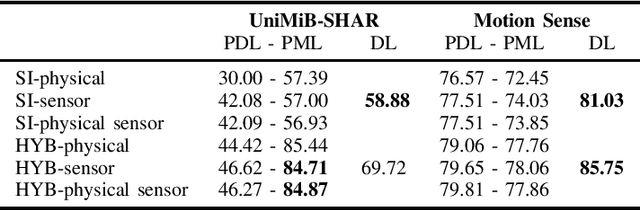
In the recent years there has been a growing interest in techniques able to automatically recognize activities performed by people. This field is known as Human Activity recognition (HAR). HAR can be crucial in monitoring the wellbeing of the people, with special regard to the elder population and those people affected by degenerative conditions. One of the main challenges concerns the diversity of the population and how the same activities can be performed in different ways due to physical characteristics and life-style. In this paper we explore the possibility of exploiting physical characteristics and signal similarity to achieve better results with respect to deep learning classifiers that do not rely on this information.
UniMiB SHAR: a new dataset for human activity recognition using acceleration data from smartphones
Aug 08, 2017
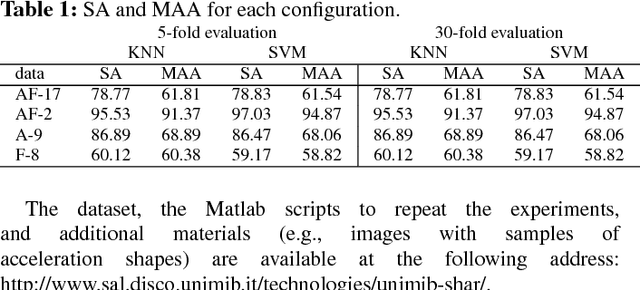
Smartphones, smartwatches, fitness trackers, and ad-hoc wearable devices are being increasingly used to monitor human activities. Data acquired by the hosted sensors are usually processed by machine-learning-based algorithms to classify human activities. The success of those algorithms mostly depends on the availability of training (labeled) data that, if made publicly available, would allow researchers to make objective comparisons between techniques. Nowadays, publicly available data sets are few, often contain samples from subjects with too similar characteristics, and very often lack of specific information so that is not possible to select subsets of samples according to specific criteria. In this article, we present a new dataset of acceleration samples acquired with an Android smartphone designed for human activity recognition and fall detection. The dataset includes 11,771 samples of both human activities and falls performed by 30 subjects of ages ranging from 18 to 60 years. Samples are divided in 17 fine grained classes grouped in two coarse grained classes: one containing samples of 9 types of activities of daily living (ADL) and the other containing samples of 8 types of falls. The dataset has been stored to include all the information useful to select samples according to different criteria, such as the type of ADL, the age, the gender, and so on. Finally, the dataset has been benchmarked with four different classifiers and with two different feature vectors. We evaluated four different classification tasks: fall vs no fall, 9 activities, 8 falls, 17 activities and falls. For each classification task we performed a subject-dependent and independent evaluation. The major findings of the evaluation are the following: i) it is more difficult to distinguish between types of falls than types of activities; ii) subject-dependent evaluation outperforms the subject-independent one