 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Characterization of Minimal Deep Learning Architectures: A Unified Analysis of Convergence, Pruning, and Quantization
Jan 25, 2026Deep learning networks excel at classification, yet identifying minimal architectures that reliably solve a task remains challenging. We present a computational methodology for systematically exploring and analyzing the relationships among convergence, pruning, and quantization. The workflow first performs a structured design sweep across a large set of architectures, then evaluates convergence behavior, pruning sensitivity, and quantization robustness on representative models. Focusing on well-known image classification of increasing complexity, and across Deep Neural Networks, Convolutional Neural Networks, and Vision Transformers, our initial results show that, despite architectural diversity, performance is largely invariant and learning dynamics consistently exhibit three regimes: unstable, learning, and overfitting. We further characterize the minimal learnable parameters required for stable learning, uncover distinct convergence and pruning phases, and quantify the effect of reduced numeric precision on trainable parameters. Aligning with intuition, the results confirm that deeper architectures are more resilient to pruning than shallower ones, with parameter redundancy as high as 60%, and quantization impacts models with fewer learnable parameters more severely and has a larger effect on harder image datasets. These findings provide actionable guidance for selecting compact, stable models under pruning and low-precision constraints in image classification.
Deep Learning-Assisted Detection of Sarcopenia in Cross-Sectional Computed Tomography Imaging
Aug 24, 2025Sarcopenia is a progressive loss of muscle mass and function linked to poor surgical outcomes such as prolonged hospital stays, impaired mobility, and increased mortality. Although it can be assessed through cross-sectional imaging by measuring skeletal muscle area (SMA), the process is time-consuming and adds to clinical workloads, limiting timely detection and management; however, this process could become more efficient and scalable with the assistance of artificial intelligence applications. This paper presents high-quality three-dimensional cross-sectional computed tomography (CT) images of patients with sarcopenia collected at the Freeman Hospital, Newcastle upon Tyne Hospitals NHS Foundation Trust. Expert clinicians manually annotated the SMA at the third lumbar vertebra, generating precise segmentation masks. We develop deep-learning models to measure SMA in CT images and automate this task. Our methodology employed transfer learning and self-supervised learning approaches using labelled and unlabeled CT scan datasets. While we developed qualitative assessment models for detecting sarcopenia, we observed that the quantitative assessment of SMA is more precise and informative. This approach also mitigates the issue of class imbalance and limited data availability. Our model predicted the SMA, on average, with an error of +-3 percentage points against the manually measured SMA. The average dice similarity coefficient of the predicted masks was 93%. Our results, therefore, show a pathway to full automation of sarcopenia assessment and detection.
AdaGAT: Adaptive Guidance Adversarial Training for the Robustness of Deep Neural Networks
Aug 24, 2025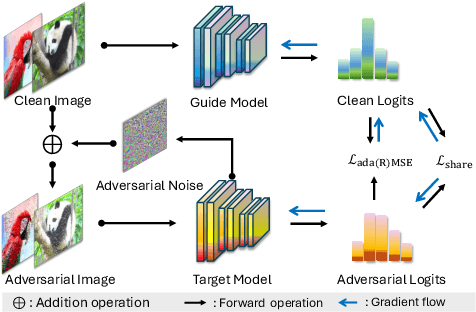
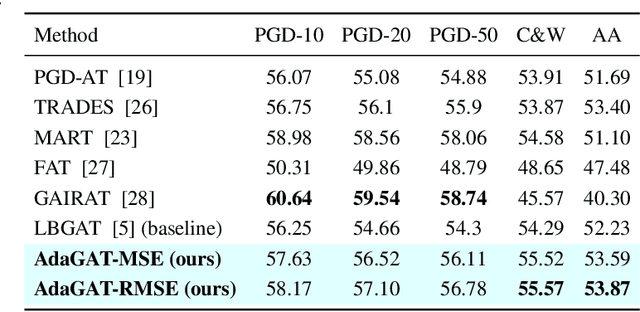
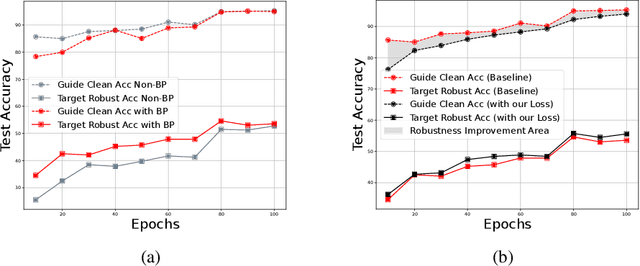
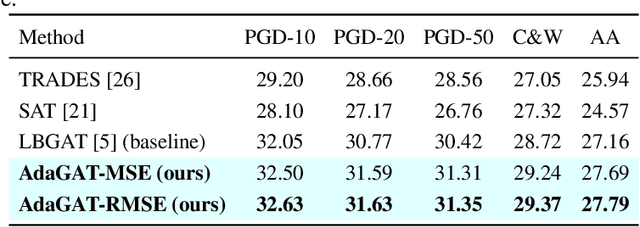
Adversarial distillation (AD) is a knowledge distillation technique that facilitates the transfer of robustness from teacher deep neural network (DNN) models to lightweight target (student) DNN models, enabling the target models to perform better than only training the student model independently. Some previous works focus on using a small, learnable teacher (guide) model to improve the robustness of a student model. Since a learnable guide model starts learning from scratch, maintaining its optimal state for effective knowledge transfer during co-training is challenging. Therefore, we propose a novel Adaptive Guidance Adversarial Training (AdaGAT) method. Our method, AdaGAT, dynamically adjusts the training state of the guide model to install robustness to the target model. Specifically, we develop two separate loss functions as part of the AdaGAT method, allowing the guide model to participate more actively in backpropagation to achieve its optimal state. We evaluated our approach via extensive experiments on three datasets: CIFAR-10, CIFAR-100, and TinyImageNet, using the WideResNet-34-10 model as the target model. Our observations reveal that appropriately adjusting the guide model within a certain accuracy range enhances the target model's robustness across various adversarial attacks compared to a variety of baseline models.
D2R: dual regularization loss with collaborative adversarial generation for model robustness
Jun 08, 2025The robustness of Deep Neural Network models is crucial for defending models against adversarial attacks. Recent defense methods have employed collaborative learning frameworks to enhance model robustness. Two key limitations of existing methods are (i) insufficient guidance of the target model via loss functions and (ii) non-collaborative adversarial generation. We, therefore, propose a dual regularization loss (D2R Loss) method and a collaborative adversarial generation (CAG) strategy for adversarial training. D2R loss includes two optimization steps. The adversarial distribution and clean distribution optimizations enhance the target model's robustness by leveraging the strengths of different loss functions obtained via a suitable function space exploration to focus more precisely on the target model's distribution. CAG generates adversarial samples using a gradient-based collaboration between guidance and target models. We conducted extensive experiments on three benchmark databases, including CIFAR-10, CIFAR-100, Tiny ImageNet, and two popular target models, WideResNet34-10 and PreActResNet18. Our results show that D2R loss with CAG produces highly robust models.
Artificial Protozoa Optimizer (APO): A novel bio-inspired metaheuristic algorithm for engineering optimization
May 06, 2025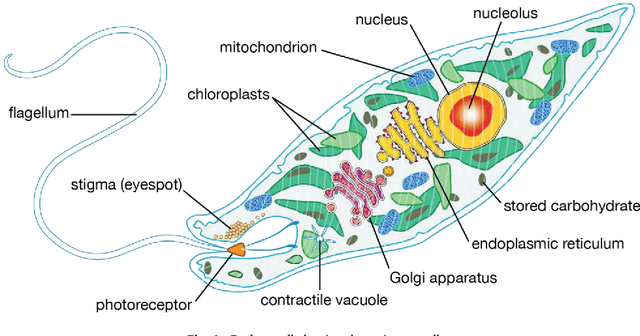

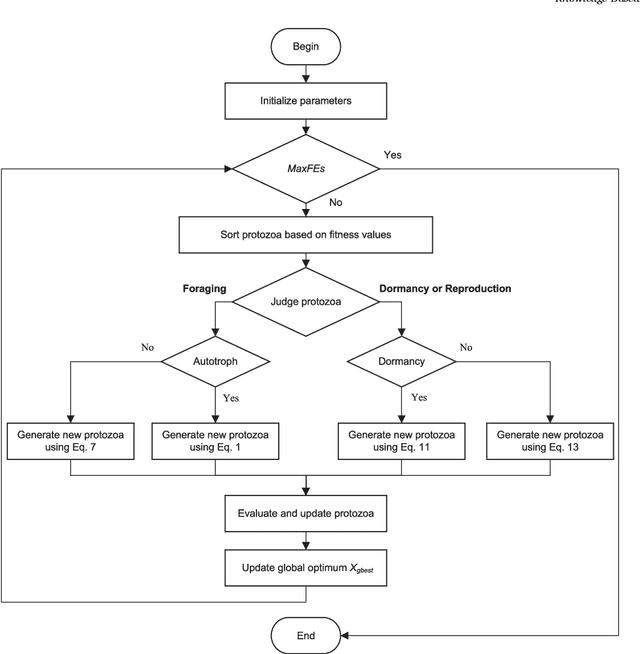
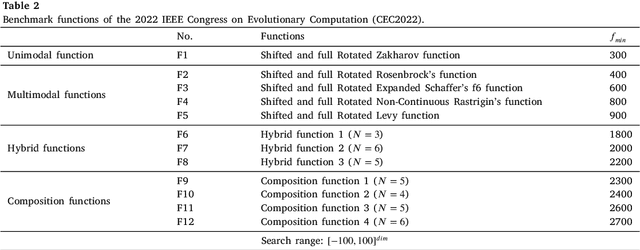
This study proposes a novel artificial protozoa optimizer (APO) that is inspired by protozoa in nature. The APO mimics the survival mechanisms of protozoa by simulating their foraging, dormancy, and reproductive behaviors. The APO was mathematically modeled and implemented to perform the optimization processes of metaheuristic algorithms. The performance of the APO was verified via experimental simulations and compared with 32 state-of-the-art algorithms. Wilcoxon signed-rank test was performed for pairwise comparisons of the proposed APO with the state-of-the-art algorithms, and Friedman test was used for multiple comparisons. First, the APO was tested using 12 functions of the 2022 IEEE Congress on Evolutionary Computation benchmark. Considering practicality, the proposed APO was used to solve five popular engineering design problems in a continuous space with constraints. Moreover, the APO was applied to solve a multilevel image segmentation task in a discrete space with constraints. The experiments confirmed that the APO could provide highly competitive results for optimization problems. The source codes of Artificial Protozoa Optimizer are publicly available at https://seyedalimirjalili.com/projects and https://ww2.mathworks.cn/matlabcentral/fileexchange/162656-artificial-protozoa-optimizer.
Dynamic Label Adversarial Training for Deep Learning Robustness Against Adversarial Attacks
Aug 23, 2024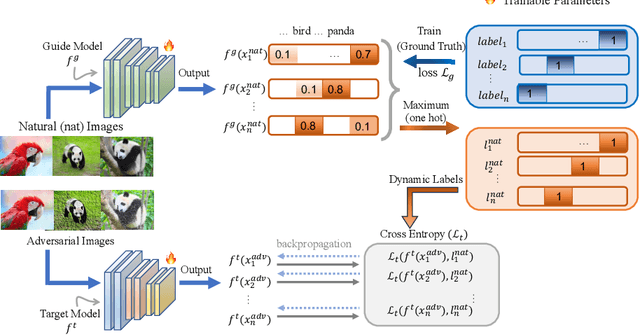
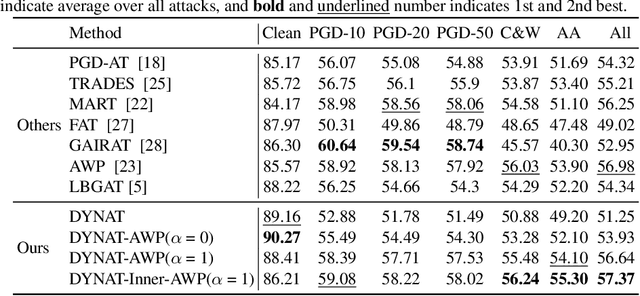

Adversarial training is one of the most effective methods for enhancing model robustness. Recent approaches incorporate adversarial distillation in adversarial training architectures. However, we notice two scenarios of defense methods that limit their performance: (1) Previous methods primarily use static ground truth for adversarial training, but this often causes robust overfitting; (2) The loss functions are either Mean Squared Error or KL-divergence leading to a sub-optimal performance on clean accuracy. To solve those problems, we propose a dynamic label adversarial training (DYNAT) algorithm that enables the target model to gradually and dynamically gain robustness from the guide model's decisions. Additionally, we found that a budgeted dimension of inner optimization for the target model may contribute to the trade-off between clean accuracy and robust accuracy. Therefore, we propose a novel inner optimization method to be incorporated into the adversarial training. This will enable the target model to adaptively search for adversarial examples based on dynamic labels from the guiding model, contributing to the robustness of the target model. Extensive experiments validate the superior performance of our approach.
On Learnable Parameters of Optimal and Suboptimal Deep Learning Models
Aug 21, 2024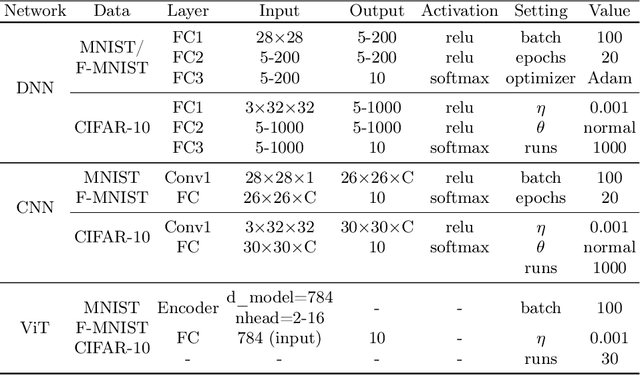
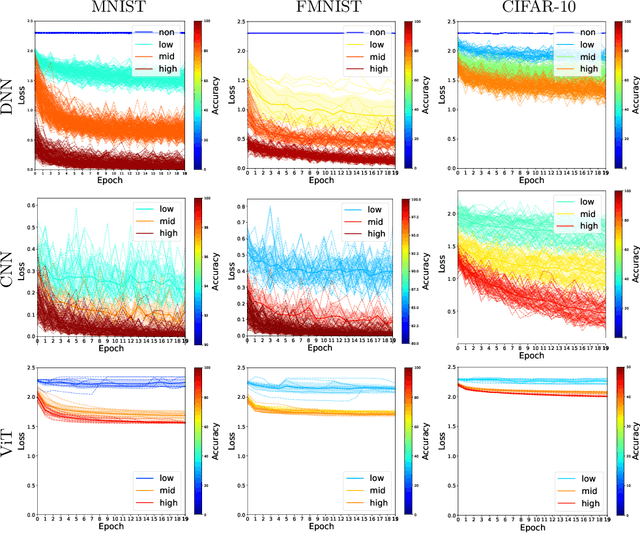
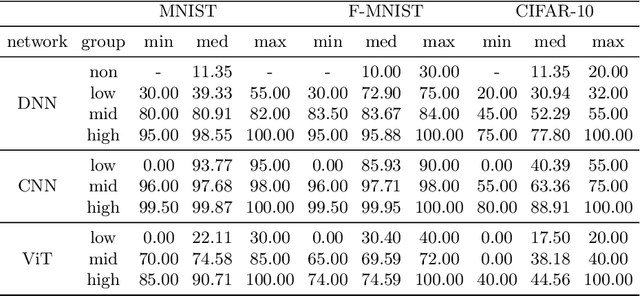
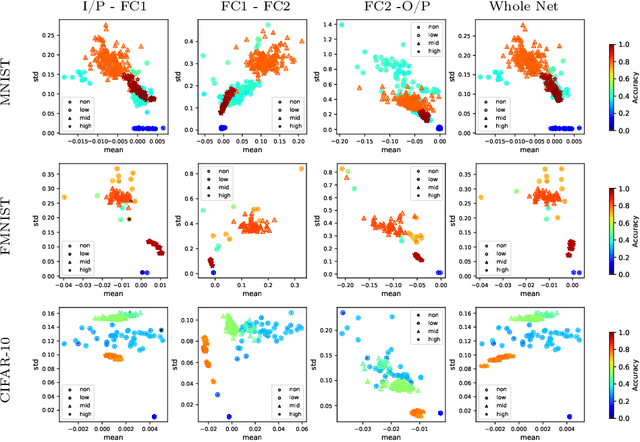
We scrutinize the structural and operational aspects of deep learning models, particularly focusing on the nuances of learnable parameters (weight) statistics, distribution, node interaction, and visualization. By establishing correlations between variance in weight patterns and overall network performance, we investigate the varying (optimal and suboptimal) performances of various deep-learning models. Our empirical analysis extends across widely recognized datasets such as MNIST, Fashion-MNIST, and CIFAR-10, and various deep learning models such as deep neural networks (DNNs), convolutional neural networks (CNNs), and vision transformer (ViT), enabling us to pinpoint characteristics of learnable parameters that correlate with successful networks. Through extensive experiments on the diverse architectures of deep learning models, we shed light on the critical factors that influence the functionality and efficiency of DNNs. Our findings reveal that successful networks, irrespective of datasets or models, are invariably similar to other successful networks in their converged weights statistics and distribution, while poor-performing networks vary in their weights. In addition, our research shows that the learnable parameters of widely varied deep learning models such as DNN, CNN, and ViT exhibit similar learning characteristics.
Heuristic design of fuzzy inference systems: A review of three decades of research
Aug 27, 2019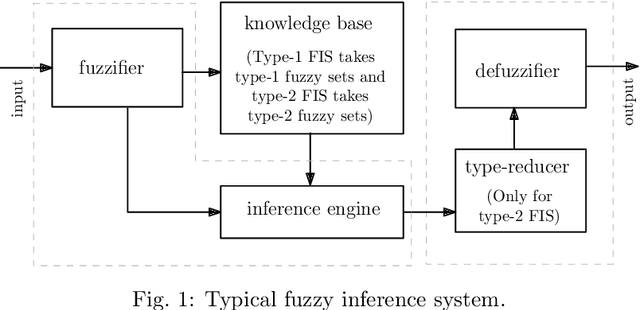
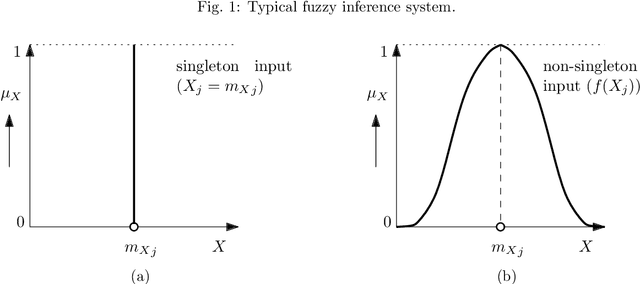
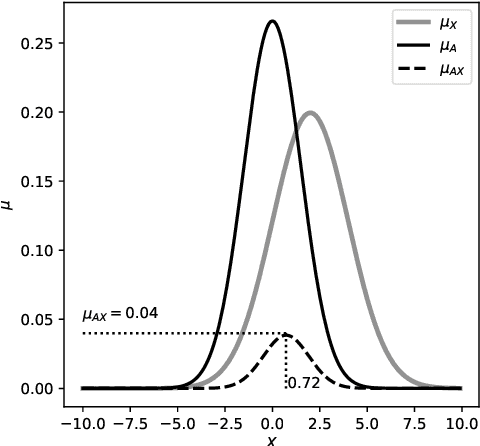
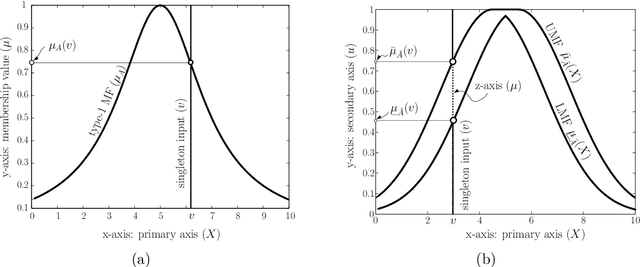
This paper provides an in-depth review of the optimal design of type-1 and type-2 fuzzy inference systems (FIS) using five well known computational frameworks: genetic-fuzzy systems (GFS), neuro-fuzzy systems (NFS), hierarchical fuzzy systems (HFS), evolving fuzzy systems (EFS), and multi-objective fuzzy systems (MFS), which is in view that some of them are linked to each other. The heuristic design of GFS uses evolutionary algorithms for optimizing both Mamdani-type and Takagi-Sugeno-Kang-type fuzzy systems. Whereas, the NFS combines the FIS with neural network learning systems to improve the approximation ability. An HFS combines two or more low-dimensional fuzzy logic units in a hierarchical design to overcome the curse of dimensionality. An EFS solves the data streaming issues by evolving the system incrementally, and an MFS solves the multi-objective trade-offs like the simultaneous maximization of both interpretability and accuracy. This paper offers a synthesis of these dimensions and explores their potentials, challenges, and opportunities in FIS research. This review also examines the complex relations among these dimensions and the possibilities of combining one or more computational frameworks adding another dimension: deep fuzzy systems.
ACO for Continuous Function Optimization: A Performance Analysis
Jul 06, 2017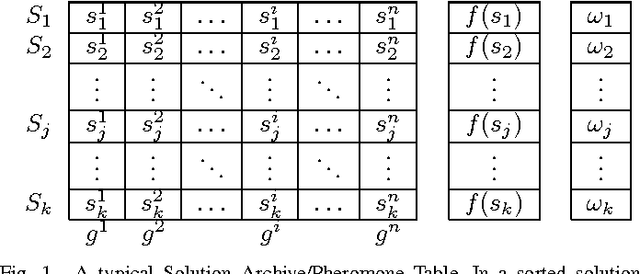
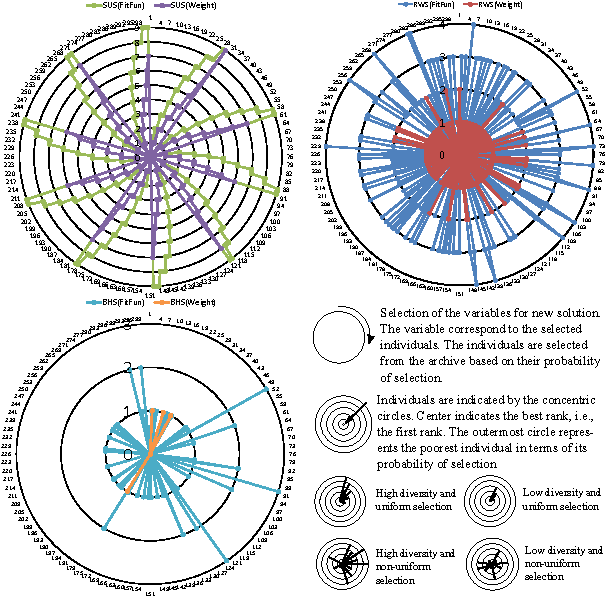
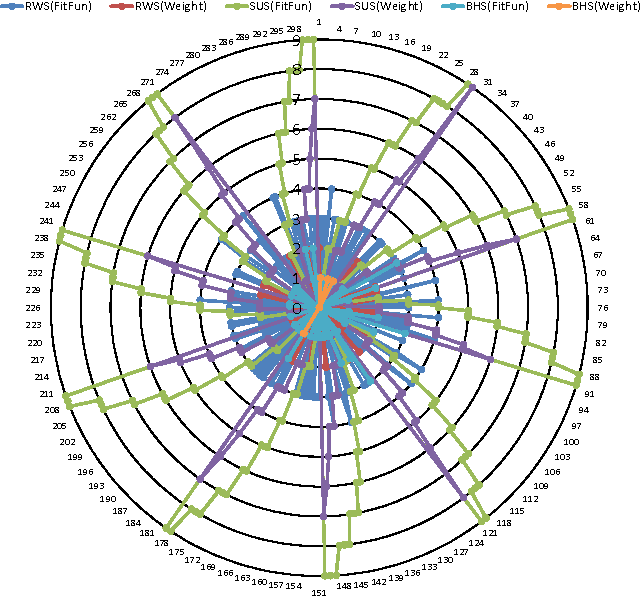
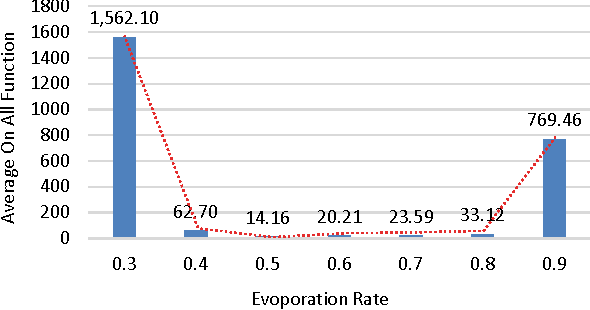
The performance of the meta-heuristic algorithms often depends on their parameter settings. Appropriate tuning of the underlying parameters can drastically improve the performance of a meta-heuristic. The Ant Colony Optimization (ACO), a population based meta-heuristic algorithm inspired by the foraging behavior of the ants, is no different. Fundamentally, the ACO depends on the construction of new solutions, variable by variable basis using Gaussian sampling of the selected variables from an archive of solutions. A comprehensive performance analysis of the underlying parameters such as: selection strategy, distance measure metric and pheromone evaporation rate of the ACO suggests that the Roulette Wheel Selection strategy enhances the performance of the ACO due to its ability to provide non-uniformity and adequate diversity in the selection of a solution. On the other hand, the Squared Euclidean distance-measure metric offers better performance than other distance-measure metrics. It is observed from the analysis that the ACO is sensitive towards the evaporation rate. Experimental analysis between classical ACO and other meta-heuristic suggested that the performance of the well-tuned ACO surpasses its counterparts.
Simultaneous Optimization of Neural Network Weights and Active Nodes using Metaheuristics
Jul 06, 2017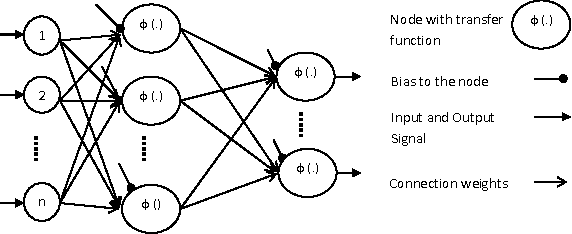
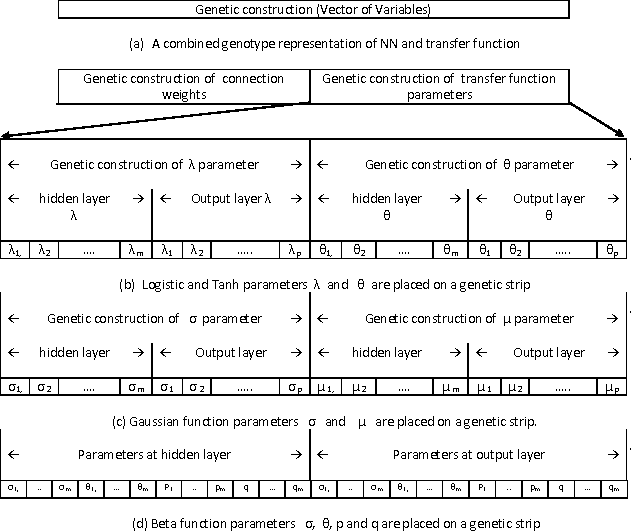

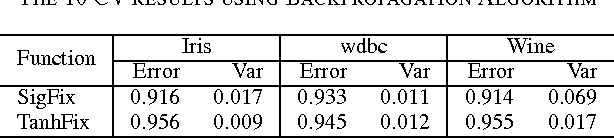
Optimization of neural network (NN) significantly influenced by the transfer function used in its active nodes. It has been observed that the homogeneity in the activation nodes does not provide the best solution. Therefore, the customizable transfer functions whose underlying parameters are subjected to optimization were used to provide heterogeneity to NN. For the experimental purpose, a meta-heuristic framework using a combined genotype representation of connection weights and transfer function parameter was used. The performance of adaptive Logistic, Tangent-hyperbolic, Gaussian and Beta functions were analyzed. In present research work, concise comparisons between different transfer function and between the NN optimization algorithms are presented. The comprehensive analysis of the results obtained over the benchmark dataset suggests that the Artificial Bee Colony with adaptive transfer function provides the best results in terms of classification accuracy over the particle swarm optimization and differential evolution.