 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNCL-BU at SemEval-2026 Task 3: Fine-tuning XLM-RoBERTa for Multilingual Dimensional Sentiment Regression
Apr 10, 2026Dimensional Aspect-Based Sentiment Analysis (DimABSA) extends traditional ABSA from categorical polarity labels to continuous valence-arousal (VA) regression. This paper describes a system developed for Track A - Subtask 1 (Dimensional Aspect Sentiment Regression), aiming to predict real-valued VA scores in the [1, 9] range for each given aspect in a text. A fine-tuning approach based on XLM-RoBERTa-base is adopted, constructing the input as [CLS] T [SEP] a_i [SEP] and training dual regression heads with sigmoid-scaled outputs for valence and arousal prediction. Separate models are trained for each language-domain combination (English and Chinese across restaurant, laptop, and finance domains), and training and development sets are merged for final test predictions. In development experiments, the fine-tuning approach is compared against several large language models including GPT-5.2, LLaMA-3-70B, LLaMA-3.3-70B, and LLaMA-4-Maverick under a few-shot prompting setting, demonstrating that task-specific fine-tuning substantially and consistently outperforms these LLM-based methods across all evaluation datasets. The code is publicly available at https://github.com/tongwu17/SemEval-2026-Task3-Track-A.
HiSpatial: Taming Hierarchical 3D Spatial Understanding in Vision-Language Models
Mar 26, 2026Achieving human-like spatial intelligence for vision-language models (VLMs) requires inferring 3D structures from 2D observations, recognizing object properties and relations in 3D space, and performing high-level spatial reasoning. In this paper, we propose a principled hierarchical framework that decomposes the learning of 3D spatial understanding in VLMs into four progressively complex levels, from geometric perception to abstract spatial reasoning. Guided by this framework, we construct an automated pipeline that processes approximately 5M images with over 45M objects to generate 3D spatial VQA pairs across diverse tasks and scenes for VLM supervised fine-tuning. We also develop an RGB-D VLM incorporating metric-scale point maps as auxiliary inputs to further enhance spatial understanding. Extensive experiments demonstrate that our approach achieves state-of-the-art performance on multiple spatial understanding and reasoning benchmarks, surpassing specialized spatial models and large proprietary systems such as Gemini-2.5-pro and GPT-5. Moreover, our analysis reveals clear dependencies among hierarchical task levels, offering new insights into how multi-level task design facilitates the emergence of 3D spatial intelligence.
NCL-UoR at SemEval-2026 Task 5: Embedding-Based Methods, Fine-Tuning, and LLMs for Word Sense Plausibility Rating
Mar 09, 2026Word sense plausibility rating requires predicting the human-perceived plausibility of a given word sense on a 1--5 scale in the context of short narrative stories containing ambiguous homonyms. This paper systematically compares three approaches: (1) embedding-based methods pairing sentence embeddings with standard regressors, (2) transformer fine-tuning with parameter-efficient adaptation, and (3) large language model (LLM) prompting with structured reasoning and explicit decision rules. The best-performing system employs a structured prompting strategy that decomposes evaluation into narrative components (precontext, target sentence, ending) and applies explicit decision rules for rating calibration. The analysis reveals that structured prompting with decision rules substantially outperforms both fine-tuned models and embedding-based approaches, and that prompt design matters more than model scale for this task. The code is publicly available at https://github.com/tongwu17/SemEval-2026-Task5.
KGHaluBench: A Knowledge Graph-Based Hallucination Benchmark for Evaluating the Breadth and Depth of LLM Knowledge
Feb 23, 2026Large Language Models (LLMs) possess a remarkable capacity to generate persuasive and intelligible language. However, coherence does not equate to truthfulness, as the responses often contain subtle hallucinations. Existing benchmarks are limited by static and narrow questions, leading to limited coverage and misleading evaluations. We present KGHaluBench, a Knowledge Graph-based hallucination benchmark that assesses LLMs across the breadth and depth of their knowledge, providing a fairer and more comprehensive insight into LLM truthfulness. Our framework utilises the KG to dynamically construct challenging, multifaceted questions, whose difficulty is then statistically estimated to address popularity bias. Our automated verification pipeline detects abstentions and verifies the LLM's response at both conceptual and correctness levels to identify different types of hallucinations. We evaluate 25 frontier models, using novel accuracy and hallucination metrics. The results provide a more interpretable insight into the knowledge factors that cause hallucinations across different model sizes. KGHaluBench is publicly available to support future developments in hallucination mitigation.
Systematic Characterization of Minimal Deep Learning Architectures: A Unified Analysis of Convergence, Pruning, and Quantization
Jan 25, 2026Deep learning networks excel at classification, yet identifying minimal architectures that reliably solve a task remains challenging. We present a computational methodology for systematically exploring and analyzing the relationships among convergence, pruning, and quantization. The workflow first performs a structured design sweep across a large set of architectures, then evaluates convergence behavior, pruning sensitivity, and quantization robustness on representative models. Focusing on well-known image classification of increasing complexity, and across Deep Neural Networks, Convolutional Neural Networks, and Vision Transformers, our initial results show that, despite architectural diversity, performance is largely invariant and learning dynamics consistently exhibit three regimes: unstable, learning, and overfitting. We further characterize the minimal learnable parameters required for stable learning, uncover distinct convergence and pruning phases, and quantify the effect of reduced numeric precision on trainable parameters. Aligning with intuition, the results confirm that deeper architectures are more resilient to pruning than shallower ones, with parameter redundancy as high as 60%, and quantization impacts models with fewer learnable parameters more severely and has a larger effect on harder image datasets. These findings provide actionable guidance for selecting compact, stable models under pruning and low-precision constraints in image classification.
Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
Oct 24, 2025



This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.
AdaGAT: Adaptive Guidance Adversarial Training for the Robustness of Deep Neural Networks
Aug 24, 2025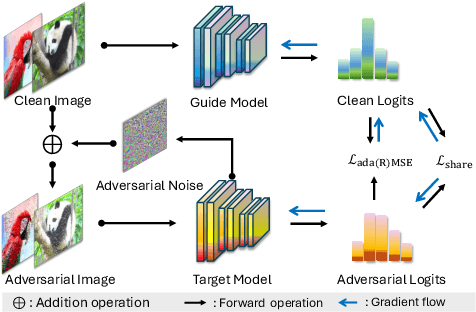
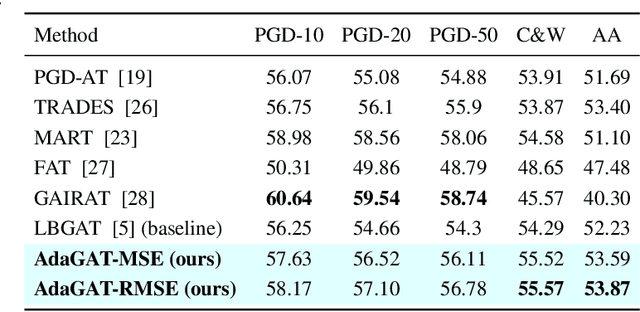
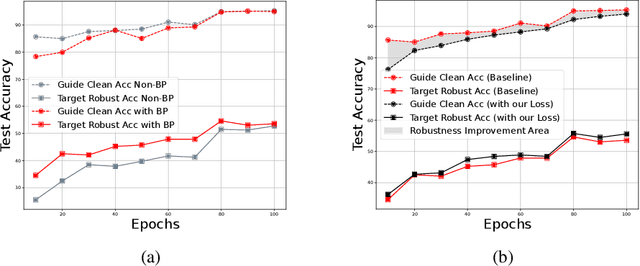
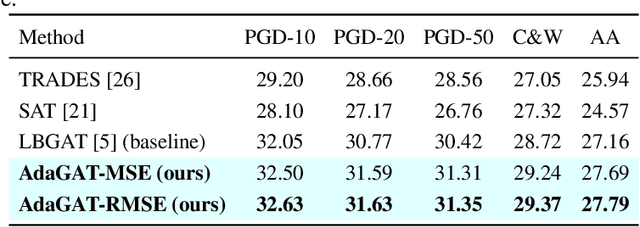
Adversarial distillation (AD) is a knowledge distillation technique that facilitates the transfer of robustness from teacher deep neural network (DNN) models to lightweight target (student) DNN models, enabling the target models to perform better than only training the student model independently. Some previous works focus on using a small, learnable teacher (guide) model to improve the robustness of a student model. Since a learnable guide model starts learning from scratch, maintaining its optimal state for effective knowledge transfer during co-training is challenging. Therefore, we propose a novel Adaptive Guidance Adversarial Training (AdaGAT) method. Our method, AdaGAT, dynamically adjusts the training state of the guide model to install robustness to the target model. Specifically, we develop two separate loss functions as part of the AdaGAT method, allowing the guide model to participate more actively in backpropagation to achieve its optimal state. We evaluated our approach via extensive experiments on three datasets: CIFAR-10, CIFAR-100, and TinyImageNet, using the WideResNet-34-10 model as the target model. Our observations reveal that appropriately adjusting the guide model within a certain accuracy range enhances the target model's robustness across various adversarial attacks compared to a variety of baseline models.
Deep Learning-Assisted Detection of Sarcopenia in Cross-Sectional Computed Tomography Imaging
Aug 24, 2025Sarcopenia is a progressive loss of muscle mass and function linked to poor surgical outcomes such as prolonged hospital stays, impaired mobility, and increased mortality. Although it can be assessed through cross-sectional imaging by measuring skeletal muscle area (SMA), the process is time-consuming and adds to clinical workloads, limiting timely detection and management; however, this process could become more efficient and scalable with the assistance of artificial intelligence applications. This paper presents high-quality three-dimensional cross-sectional computed tomography (CT) images of patients with sarcopenia collected at the Freeman Hospital, Newcastle upon Tyne Hospitals NHS Foundation Trust. Expert clinicians manually annotated the SMA at the third lumbar vertebra, generating precise segmentation masks. We develop deep-learning models to measure SMA in CT images and automate this task. Our methodology employed transfer learning and self-supervised learning approaches using labelled and unlabeled CT scan datasets. While we developed qualitative assessment models for detecting sarcopenia, we observed that the quantitative assessment of SMA is more precise and informative. This approach also mitigates the issue of class imbalance and limited data availability. Our model predicted the SMA, on average, with an error of +-3 percentage points against the manually measured SMA. The average dice similarity coefficient of the predicted masks was 93%. Our results, therefore, show a pathway to full automation of sarcopenia assessment and detection.
D2R: dual regularization loss with collaborative adversarial generation for model robustness
Jun 08, 2025The robustness of Deep Neural Network models is crucial for defending models against adversarial attacks. Recent defense methods have employed collaborative learning frameworks to enhance model robustness. Two key limitations of existing methods are (i) insufficient guidance of the target model via loss functions and (ii) non-collaborative adversarial generation. We, therefore, propose a dual regularization loss (D2R Loss) method and a collaborative adversarial generation (CAG) strategy for adversarial training. D2R loss includes two optimization steps. The adversarial distribution and clean distribution optimizations enhance the target model's robustness by leveraging the strengths of different loss functions obtained via a suitable function space exploration to focus more precisely on the target model's distribution. CAG generates adversarial samples using a gradient-based collaboration between guidance and target models. We conducted extensive experiments on three benchmark databases, including CIFAR-10, CIFAR-100, Tiny ImageNet, and two popular target models, WideResNet34-10 and PreActResNet18. Our results show that D2R loss with CAG produces highly robust models.
UoR-NCL at SemEval-2025 Task 1: Using Generative LLMs and CLIP Models for Multilingual Multimodal Idiomaticity Representation
Feb 28, 2025



SemEval-2025 Task 1 focuses on ranking images based on their alignment with a given nominal compound that may carry idiomatic meaning in both English and Brazilian Portuguese. To address this challenge, this work uses generative large language models (LLMs) and multilingual CLIP models to enhance idiomatic compound representations. LLMs generate idiomatic meanings for potentially idiomatic compounds, enriching their semantic interpretation. These meanings are then encoded using multilingual CLIP models, serving as representations for image ranking. Contrastive learning and data augmentation techniques are applied to fine-tune these embeddings for improved performance. Experimental results show that multimodal representations extracted through this method outperformed those based solely on the original nominal compounds. The fine-tuning approach shows promising outcomes but is less effective than using embeddings without fine-tuning. The source code used in this paper is available at https://github.com/tongwu17/SemEval-2025-Task1-UoR-NCL.