 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Serendipity Recommendation System by Constructing Dynamic User Knowledge Graphs with Large Language Models
Aug 06, 2025



The feedback loop in industrial recommendation systems reinforces homogeneous content, creates filter bubble effects, and diminishes user satisfaction. Recently, large language models(LLMs) have demonstrated potential in serendipity recommendation, thanks to their extensive world knowledge and superior reasoning capabilities. However, these models still face challenges in ensuring the rationality of the reasoning process, the usefulness of the reasoning results, and meeting the latency requirements of industrial recommendation systems (RSs). To address these challenges, we propose a method that leverages llm to dynamically construct user knowledge graphs, thereby enhancing the serendipity of recommendation systems. This method comprises a two stage framework:(1) two-hop interest reasoning, where user static profiles and historical behaviors are utilized to dynamically construct user knowledge graphs via llm. Two-hop reasoning, which can enhance the quality and accuracy of LLM reasoning results, is then performed on the constructed graphs to identify users' potential interests; and(2) Near-line adaptation, a cost-effective approach to deploying the aforementioned models in industrial recommendation systems. We propose a u2i (user-to-item) retrieval model that also incorporates i2i (item-to-item) retrieval capabilities, the retrieved items not only exhibit strong relevance to users' newly emerged interests but also retain the high conversion rate of traditional u2i retrieval. Our online experiments on the Dewu app, which has tens of millions of users, indicate that the method increased the exposure novelty rate by 4.62%, the click novelty rate by 4.85%, the average view duration per person by 0.15%, unique visitor click through rate by 0.07%, and unique visitor interaction penetration by 0.30%, enhancing user experience.
LightKG: Efficient Knowledge-Aware Recommendations with Simplified GNN Architecture
Jun 12, 2025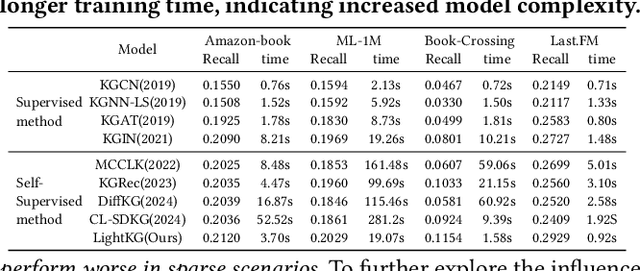

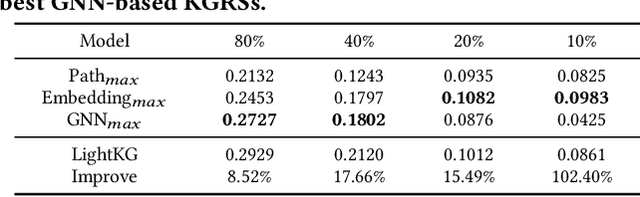
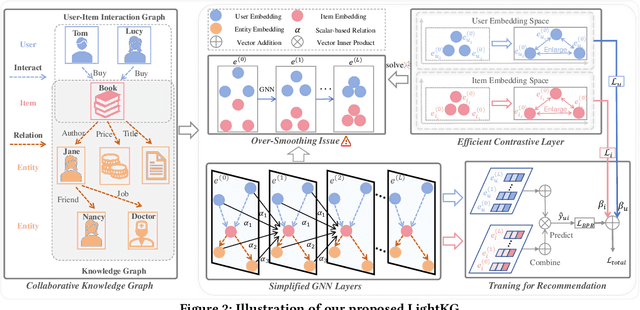
Recently, Graph Neural Networks (GNNs) have become the dominant approach for Knowledge Graph-aware Recommender Systems (KGRSs) due to their proven effectiveness. Building upon GNN-based KGRSs, Self-Supervised Learning (SSL) has been incorporated to address the sparity issue, leading to longer training time. However, through extensive experiments, we reveal that: (1)compared to other KGRSs, the existing GNN-based KGRSs fail to keep their superior performance under sparse interactions even with SSL. (2) More complex models tend to perform worse in sparse interaction scenarios and complex mechanisms, like attention mechanism, can be detrimental as they often increase learning difficulty. Inspired by these findings, we propose LightKG, a simple yet powerful GNN-based KGRS to address sparsity issues. LightKG includes a simplified GNN layer that encodes directed relations as scalar pairs rather than dense embeddings and employs a linear aggregation framework, greatly reducing the complexity of GNNs. Additionally, LightKG incorporates an efficient contrastive layer to implement SSL. It directly minimizes the node similarity in original graph, avoiding the time-consuming subgraph generation and comparison required in previous SSL methods. Experiments on four benchmark datasets show that LightKG outperforms 12 competitive KGRSs in both sparse and dense scenarios while significantly reducing training time. Specifically, it surpasses the best baselines by an average of 5.8\% in recommendation accuracy and saves 84.3\% of training time compared to KGRSs with SSL. Our code is available at https://github.com/1371149/LightKG.
Does Knowledge Graph Really Matter for Recommender Systems?
Apr 04, 2024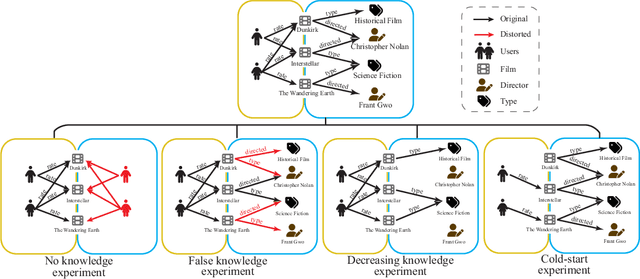

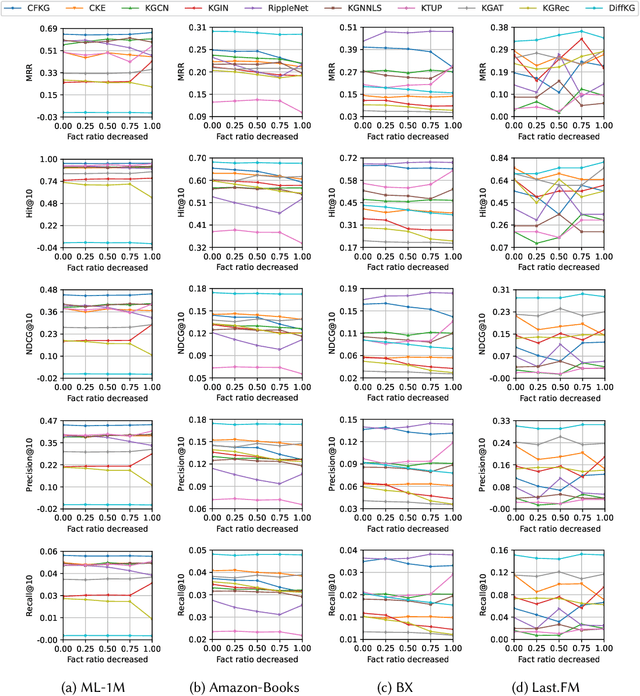
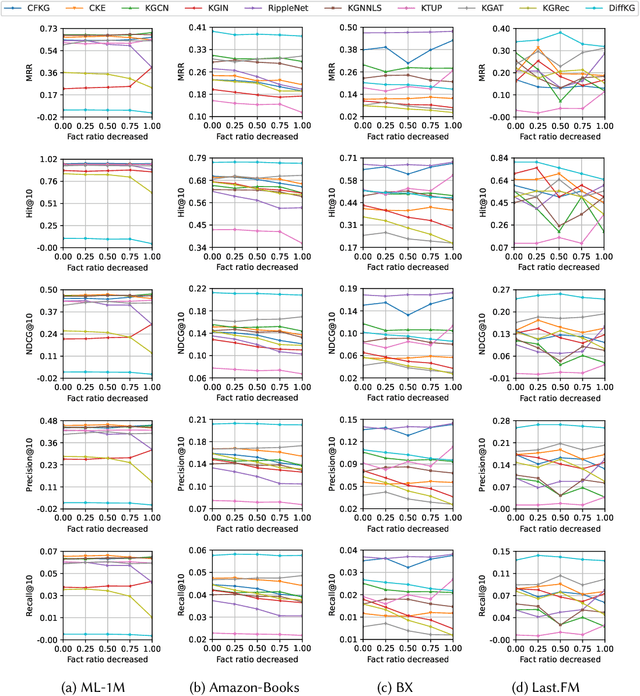
Recommender systems (RSs) are designed to provide personalized recommendations to users. Recently, knowledge graphs (KGs) have been widely introduced in RSs to improve recommendation accuracy. In this study, however, we demonstrate that RSs do not necessarily perform worse even if the KG is downgraded to the user-item interaction graph only (or removed). We propose an evaluation framework KG4RecEval to systematically evaluate how much a KG contributes to the recommendation accuracy of a KG-based RS, using our defined metric KGER (KG utilization efficiency in recommendation). We consider the scenarios where knowledge in a KG gets completely removed, randomly distorted and decreased, and also where recommendations are for cold-start users. Our extensive experiments on four commonly used datasets and a number of state-of-the-art KG-based RSs reveal that: to remove, randomly distort or decrease knowledge does not necessarily decrease recommendation accuracy, even for cold-start users. These findings inspire us to rethink how to better utilize knowledge from existing KGs, whereby we discuss and provide insights into what characteristics of datasets and KG-based RSs may help improve KG utilization efficiency.
Causality-Aided Trade-off Analysis for Machine Learning Fairness
May 22, 2023


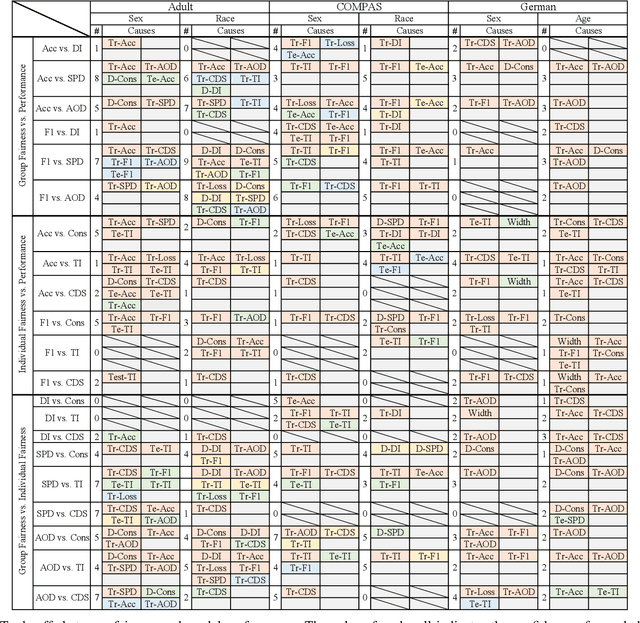
There has been an increasing interest in enhancing the fairness of machine learning (ML). Despite the growing number of fairness-improving methods, we lack a systematic understanding of the trade-offs among factors considered in the ML pipeline when fairness-improving methods are applied. This understanding is essential for developers to make informed decisions regarding the provision of fair ML services. Nonetheless, it is extremely difficult to analyze the trade-offs when there are multiple fairness parameters and other crucial metrics involved, coupled, and even in conflict with one another. This paper uses causality analysis as a principled method for analyzing trade-offs between fairness parameters and other crucial metrics in ML pipelines. To ractically and effectively conduct causality analysis, we propose a set of domain-specific optimizations to facilitate accurate causal discovery and a unified, novel interface for trade-off analysis based on well-established causal inference methods. We conduct a comprehensive empirical study using three real-world datasets on a collection of widelyused fairness-improving techniques. Our study obtains actionable suggestions for users and developers of fair ML. We further demonstrate the versatile usage of our approach in selecting the optimal fairness-improving method, paving the way for more ethical and socially responsible AI technologies.
Measuring Discrimination to Boost Comparative Testing for Multiple Deep Learning Models
Mar 09, 2021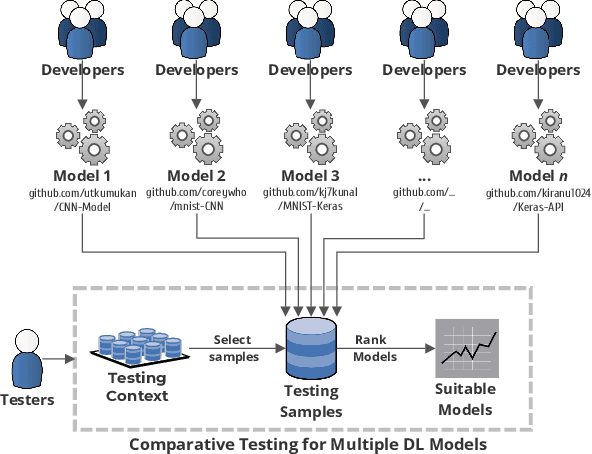
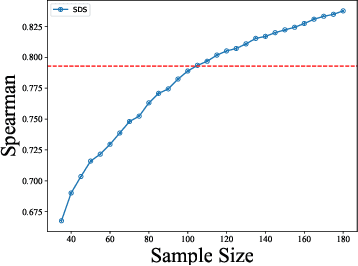
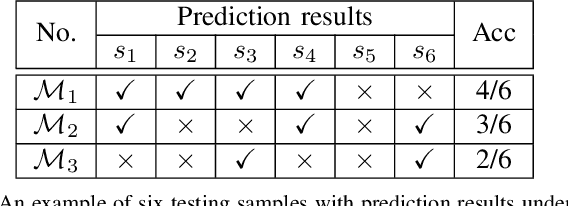
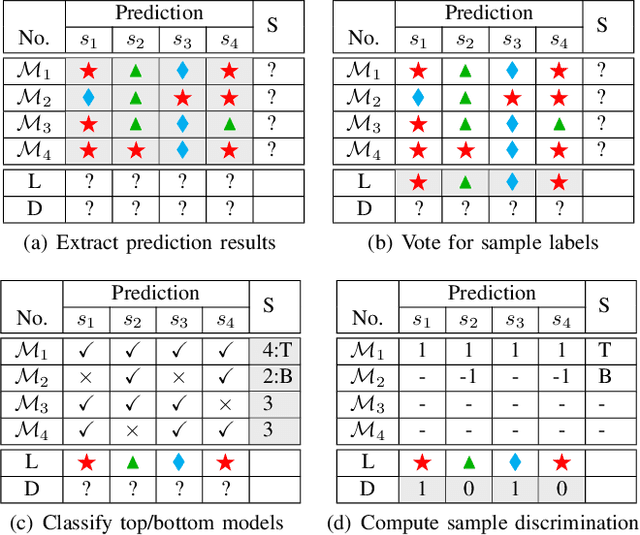
The boom of DL technology leads to massive DL models built and shared, which facilitates the acquisition and reuse of DL models. For a given task, we encounter multiple DL models available with the same functionality, which are considered as candidates to achieve this task. Testers are expected to compare multiple DL models and select the more suitable ones w.r.t. the whole testing context. Due to the limitation of labeling effort, testers aim to select an efficient subset of samples to make an as precise rank estimation as possible for these models. To tackle this problem, we propose Sample Discrimination based Selection (SDS) to select efficient samples that could discriminate multiple models, i.e., the prediction behaviors (right/wrong) of these samples would be helpful to indicate the trend of model performance. To evaluate SDS, we conduct an extensive empirical study with three widely-used image datasets and 80 real world DL models. The experimental results show that, compared with state-of-the-art baseline methods, SDS is an effective and efficient sample selection method to rank multiple DL models.
Connecting Software Metrics across Versions to Predict Defects
Dec 28, 2017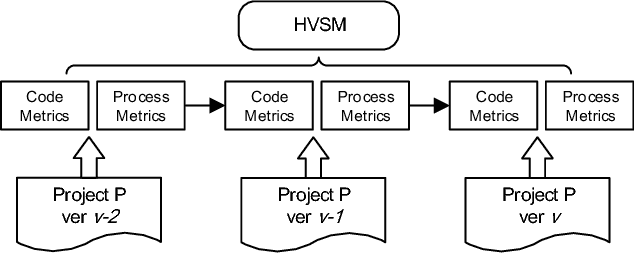
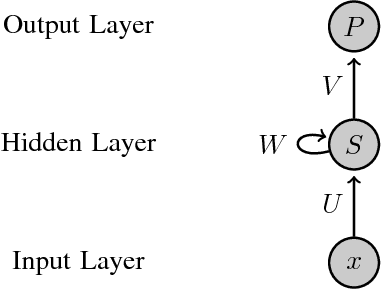
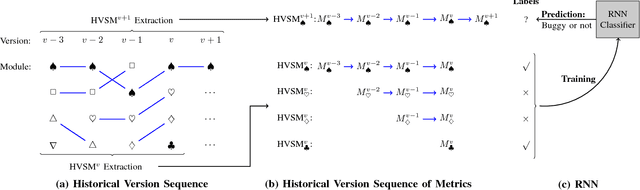
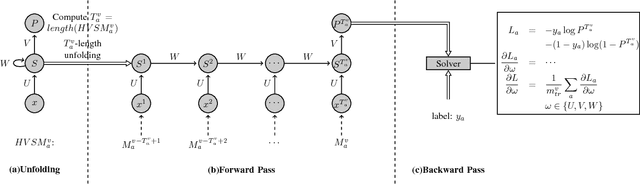
Accurate software defect prediction could help software practitioners allocate test resources to defect-prone modules effectively and efficiently. In the last decades, much effort has been devoted to build accurate defect prediction models, including developing quality defect predictors and modeling techniques. However, current widely used defect predictors such as code metrics and process metrics could not well describe how software modules change over the project evolution, which we believe is important for defect prediction. In order to deal with this problem, in this paper, we propose to use the Historical Version Sequence of Metrics (HVSM) in continuous software versions as defect predictors. Furthermore, we leverage Recurrent Neural Network (RNN), a popular modeling technique, to take HVSM as the input to build software prediction models. The experimental results show that, in most cases, the proposed HVSM-based RNN model has a significantly better effort-aware ranking effectiveness than the commonly used baseline models.