 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Interaction Summarization and Contrastive Prompting for Explainable Recommendations
Jul 08, 2025Explainable recommendations, which use the information of user and item with interaction to generate a explanation for why the user would interact with the item, are crucial for improving user trust and decision transparency to the recommender system. Existing methods primarily rely on encoding features of users and items to embeddings, which often leads to information loss due to dimensionality reduction, sparse interactions, and so on. With the advancements of large language models (LLMs) in language comprehension, some methods use embeddings as LLM inputs for explanation generation. However, since embeddings lack inherent semantics, LLMs must adjust or extend their parameters to interpret them, a process that inevitably incurs information loss. To address this issue, we propose a novel approach combining profile generation via hierarchical interaction summarization (PGHIS), which leverages a pretrained LLM to hierarchically summarize user-item interactions, generating structured textual profiles as explicit representations of user and item characteristics. Additionally, we propose contrastive prompting for explanation generation (CPEG) which employs contrastive learning to guide another reasoning language models in producing high-quality ground truth recommendation explanations. Finally, we use the textual profiles of user and item as input and high-quality explanation as output to fine-tune a LLM for generating explanations. Experimental results on multiple datasets demonstrate that our approach outperforms existing state-of-the-art methods, achieving a great improvement on metrics about explainability (e.g., 5% on GPTScore) and text quality. Furthermore, our generated ground truth explanations achieve a significantly higher win rate compared to user-written reviews and those produced by other methods, demonstrating the effectiveness of CPEG in generating high-quality ground truths.
A Framework For Image Synthesis Using Supervised Contrastive Learning
Dec 05, 2024Text-to-image (T2I) generation aims at producing realistic images corresponding to text descriptions. Generative Adversarial Network (GAN) has proven to be successful in this task. Typical T2I GANs are 2 phase methods that first pretrain an inter-modal representation from aligned image-text pairs and then use GAN to train image generator on that basis. However, such representation ignores the inner-modal semantic correspondence, e.g. the images with same label. The semantic label in priory describes the inherent distribution pattern with underlying cross-image relationships, which is supplement to the text description for understanding the full characteristics of image. In this paper, we propose a framework leveraging both inter- and inner-modal correspondence by label guided supervised contrastive learning. We extend the T2I GANs to two parameter-sharing contrast branches in both pretraining and generation phases. This integration effectively clusters the semantically similar image-text pair representations, thereby fostering the generation of higher-quality images. We demonstrate our framework on four novel T2I GANs by both single-object dataset CUB and multi-object dataset COCO, achieving significant improvements in the Inception Score (IS) and Frechet Inception Distance (FID) metrics of imagegeneration evaluation. Notably, on more complex multi-object COCO, our framework improves FID by 30.1%, 27.3%, 16.2% and 17.1% for AttnGAN, DM-GAN, SSA-GAN and GALIP, respectively. We also validate our superiority by comparing with other label guided T2I GANs. The results affirm the effectiveness and competitiveness of our approach in advancing the state-of-the-art GAN for T2I generation
ActiveRAG: Revealing the Treasures of Knowledge via Active Learning
Feb 21, 2024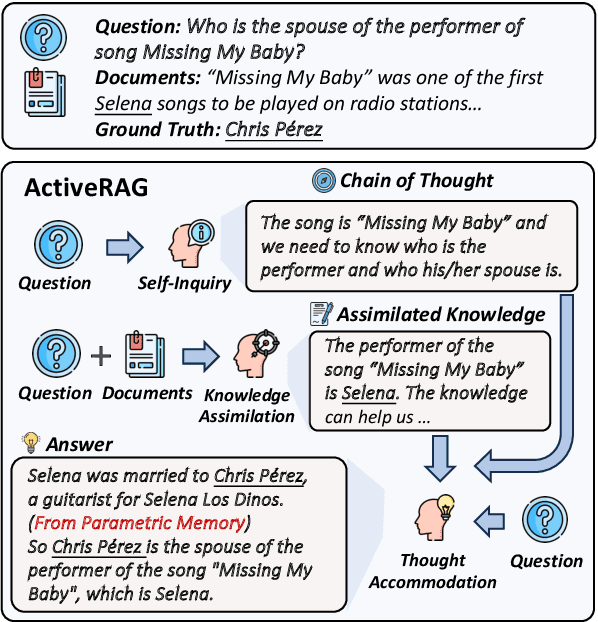
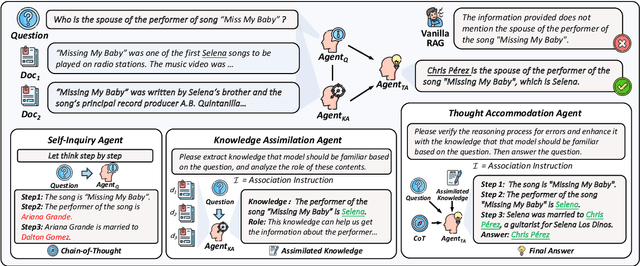
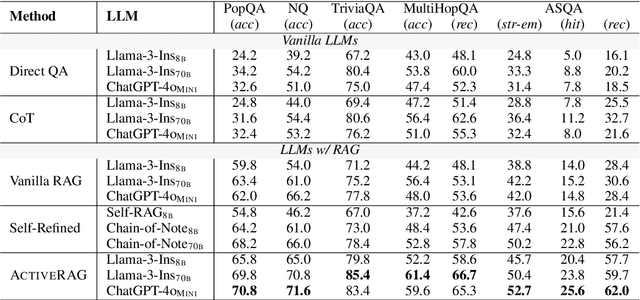
Retrieval Augmented Generation (RAG) has introduced a new paradigm for Large Language Models (LLMs), aiding in the resolution of knowledge-intensive tasks. However, current RAG models position LLMs as passive knowledge receptors, thereby restricting their capacity for learning and comprehending external knowledge. In this paper, we present ActiveRAG, an innovative RAG framework that shifts from passive knowledge acquisition to an active learning mechanism. This approach utilizes the Knowledge Construction mechanism to develop a deeper understanding of external knowledge by associating it with previously acquired or memorized knowledge. Subsequently, it designs the Cognitive Nexus mechanism to incorporate the outcomes from both chains of thought and knowledge construction, thereby calibrating the intrinsic cognition of LLMs. Our experimental results demonstrate that ActiveRAG surpasses previous RAG models, achieving a 5% improvement on question-answering datasets. All data and codes are available at https://github.com/OpenMatch/ActiveRAG.
Weaver: Foundation Models for Creative Writing
Jan 30, 2024


This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
Connecting Software Metrics across Versions to Predict Defects
Dec 28, 2017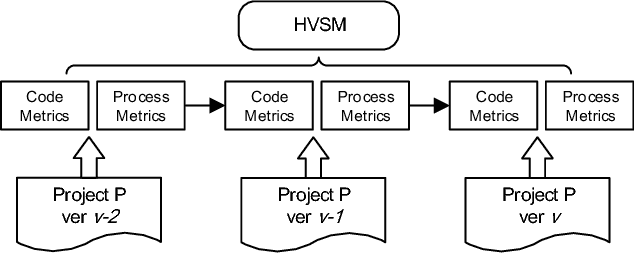
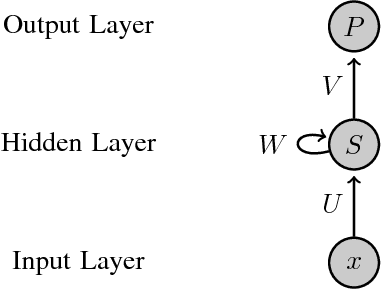
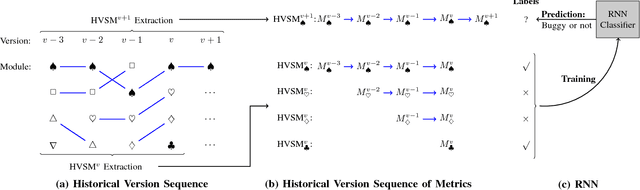
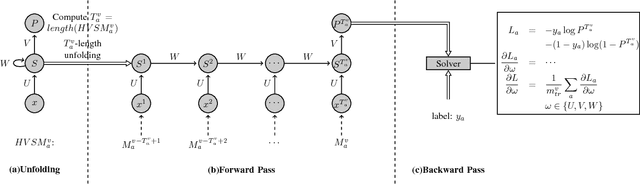
Accurate software defect prediction could help software practitioners allocate test resources to defect-prone modules effectively and efficiently. In the last decades, much effort has been devoted to build accurate defect prediction models, including developing quality defect predictors and modeling techniques. However, current widely used defect predictors such as code metrics and process metrics could not well describe how software modules change over the project evolution, which we believe is important for defect prediction. In order to deal with this problem, in this paper, we propose to use the Historical Version Sequence of Metrics (HVSM) in continuous software versions as defect predictors. Furthermore, we leverage Recurrent Neural Network (RNN), a popular modeling technique, to take HVSM as the input to build software prediction models. The experimental results show that, in most cases, the proposed HVSM-based RNN model has a significantly better effort-aware ranking effectiveness than the commonly used baseline models.