 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch More, Think Less: Rethinking Long-Horizon Agentic Search for Efficiency and Generalization
Feb 26, 2026Recent deep research agents primarily improve performance by scaling reasoning depth, but this leads to high inference cost and latency in search-intensive scenarios. Moreover, generalization across heterogeneous research settings remains challenging. In this work, we propose \emph{Search More, Think Less} (SMTL), a framework for long-horizon agentic search that targets both efficiency and generalization. SMTL replaces sequential reasoning with parallel evidence acquisition, enabling efficient context management under constrained context budgets. To support generalization across task types, we further introduce a unified data synthesis pipeline that constructs search tasks spanning both deterministic question answering and open-ended research scenarios with task appropriate evaluation metrics. We train an end-to-end agent using supervised fine-tuning and reinforcement learning, achieving strong and often state of the art performance across benchmarks including BrowseComp (48.6\%), GAIA (75.7\%), Xbench (82.0\%), and DeepResearch Bench (45.9\%). Compared to Mirothinker-v1.0, SMTL with maximum 100 interaction steps reduces the average number of reasoning steps on BrowseComp by 70.7\%, while improving accuracy.
O-Mem: Omni Memory System for Personalized, Long Horizon, Self-Evolving Agents
Nov 18, 2025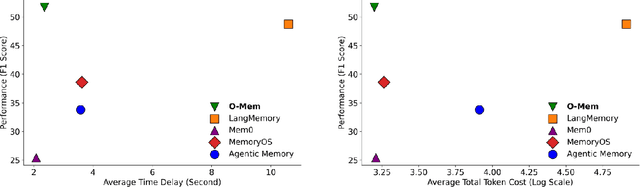
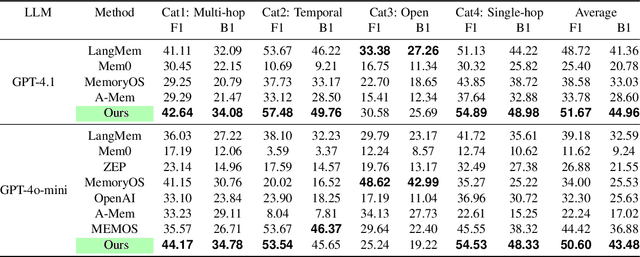
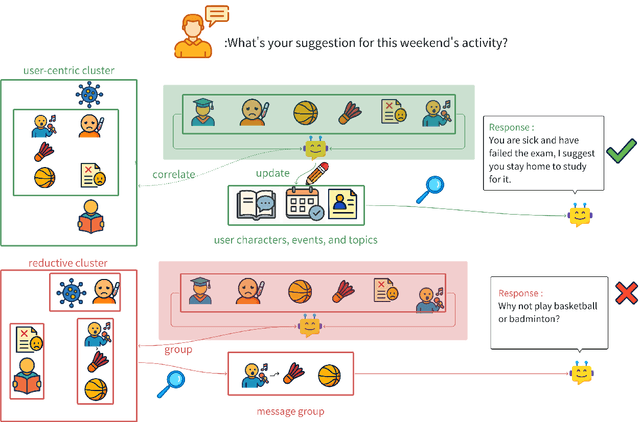

Recent advancements in LLM-powered agents have demonstrated significant potential in generating human-like responses; however, they continue to face challenges in maintaining long-term interactions within complex environments, primarily due to limitations in contextual consistency and dynamic personalization. Existing memory systems often depend on semantic grouping prior to retrieval, which can overlook semantically irrelevant yet critical user information and introduce retrieval noise. In this report, we propose the initial design of O-Mem, a novel memory framework based on active user profiling that dynamically extracts and updates user characteristics and event records from their proactive interactions with agents. O-Mem supports hierarchical retrieval of persona attributes and topic-related context, enabling more adaptive and coherent personalized responses. O-Mem achieves 51.67% on the public LoCoMo benchmark, a nearly 3% improvement upon LangMem,the previous state-of-the-art, and it achieves 62.99% on PERSONAMEM, a 3.5% improvement upon A-Mem,the previous state-of-the-art. O-Mem also boosts token and interaction response time efficiency compared to previous memory frameworks. Our work opens up promising directions for developing efficient and human-like personalized AI assistants in the future.
Towards Faithful and Controllable Personalization via Critique-Post-Edit Reinforcement Learning
Oct 21, 2025Faithfully personalizing large language models (LLMs) to align with individual user preferences is a critical but challenging task. While supervised fine-tuning (SFT) quickly reaches a performance plateau, standard reinforcement learning from human feedback (RLHF) also struggles with the nuances of personalization. Scalar-based reward models are prone to reward hacking which leads to verbose and superficially personalized responses. To address these limitations, we propose Critique-Post-Edit, a robust reinforcement learning framework that enables more faithful and controllable personalization. Our framework integrates two key components: (1) a Personalized Generative Reward Model (GRM) that provides multi-dimensional scores and textual critiques to resist reward hacking, and (2) a Critique-Post-Edit mechanism where the policy model revises its own outputs based on these critiques for more targeted and efficient learning. Under a rigorous length-controlled evaluation, our method substantially outperforms standard PPO on personalization benchmarks. Personalized Qwen2.5-7B achieves an average 11\% win-rate improvement, and personalized Qwen2.5-14B model surpasses the performance of GPT-4.1. These results demonstrate a practical path to faithful, efficient, and controllable personalization.
MiCoTA: Bridging the Learnability Gap with Intermediate CoT and Teacher Assistants
Jul 02, 2025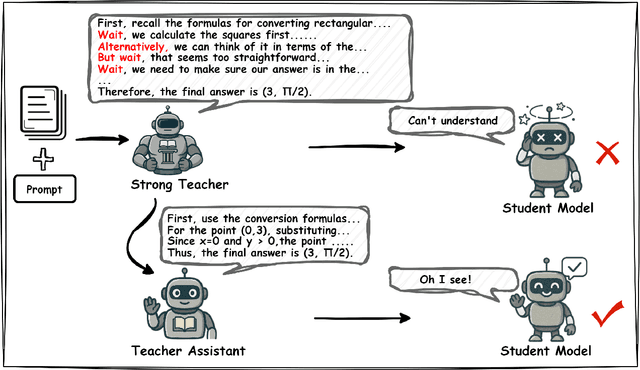
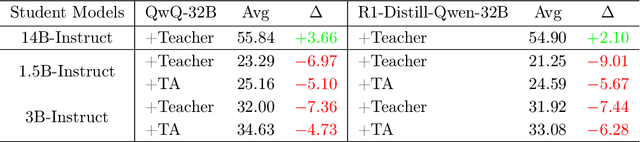
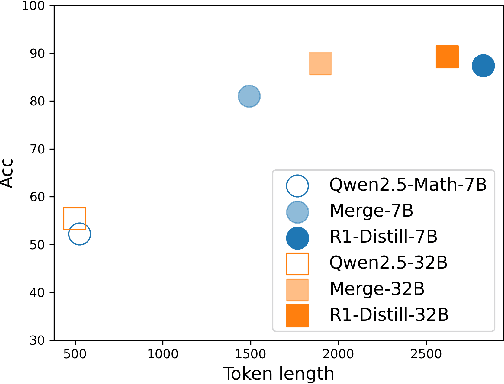
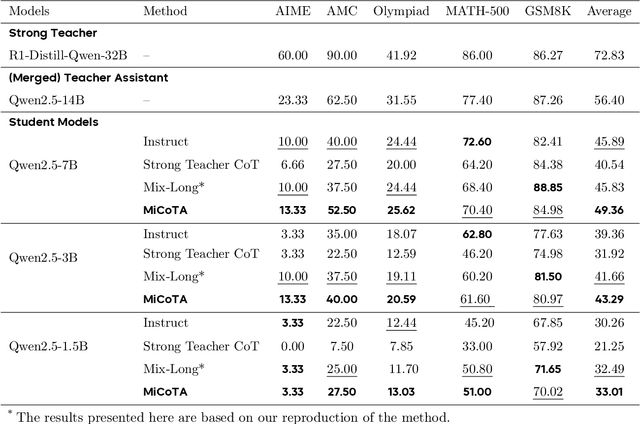
Large language models (LLMs) excel at reasoning tasks requiring long thought sequences for planning, reflection, and refinement. However, their substantial model size and high computational demands are impractical for widespread deployment. Yet, small language models (SLMs) often struggle to learn long-form CoT reasoning due to their limited capacity, a phenomenon we refer to as the "SLMs Learnability Gap". To address this, we introduce \textbf{Mi}d-\textbf{Co}T \textbf{T}eacher \textbf{A}ssistant Distillation (MiCoTAl), a framework for improving long CoT distillation for SLMs. MiCoTA employs intermediate-sized models as teacher assistants and utilizes intermediate-length CoT sequences to bridge both the capacity and reasoning length gaps. Our experiments on downstream tasks demonstrate that although SLMs distilled from large teachers can perform poorly, by applying MiCoTA, they achieve significant improvements in reasoning performance. Specifically, Qwen2.5-7B-Instruct and Qwen2.5-3B-Instruct achieve an improvement of 3.47 and 3.93 respectively on average score on AIME2024, AMC, Olympiad, MATH-500 and GSM8K benchmarks. To better understand the mechanism behind MiCoTA, we perform a quantitative experiment demonstrating that our method produces data more closely aligned with base SLM distributions. Our insights pave the way for future research into long-CoT data distillation for SLMs.
PersonaFeedback: A Large-scale Human-annotated Benchmark For Personalization
Jun 15, 2025With the rapid improvement in the general capabilities of LLMs, LLM personalization, i.e., how to build LLM systems that can generate personalized responses or services that are tailored to distinct user personas, has become an increasingly important research and engineering problem. However, unlike many new challenging benchmarks being released for evaluating the general/reasoning capabilities, the lack of high-quality benchmarks for evaluating LLM personalization greatly hinders progress in this field. To address this, we introduce PersonaFeedback, a new benchmark that directly evaluates LLMs' ability to provide personalized responses given pre-defined user personas and queries. Unlike existing benchmarks that require models to infer implicit user personas from historical interactions, PersonaFeedback decouples persona inference from personalization, focusing on evaluating the model's ability to generate responses tailored to explicit personas. PersonaFeedback consists of 8298 human-annotated test cases, which are categorized into easy, medium, and hard tiers based on the contextual complexity of the user personas and the difficulty in distinguishing subtle differences between two personalized responses. We conduct comprehensive evaluations across a wide range of models. The empirical results reveal that even state-of-the-art LLMs that can solve complex real-world reasoning tasks could fall short on the hard tier of PersonaFeedback where even human evaluators may find the distinctions challenging. Furthermore, we conduct an in-depth analysis of failure modes across various types of systems, demonstrating that the current retrieval-augmented framework should not be seen as a de facto solution for personalization tasks. All benchmark data, annotation protocols, and the evaluation pipeline will be publicly available to facilitate future research on LLM personalization.
COIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
AI PERSONA: Towards Life-long Personalization of LLMs
Dec 17, 2024In this work, we introduce the task of life-long personalization of large language models. While recent mainstream efforts in the LLM community mainly focus on scaling data and compute for improved capabilities of LLMs, we argue that it is also very important to enable LLM systems, or language agents, to continuously adapt to the diverse and ever-changing profiles of every distinct user and provide up-to-date personalized assistance. We provide a clear task formulation and introduce a simple, general, effective, and scalable framework for life-long personalization of LLM systems and language agents. To facilitate future research on LLM personalization, we also introduce methods to synthesize realistic benchmarks and robust evaluation metrics. We will release all codes and data for building and benchmarking life-long personalized LLM systems.
Symbolic Learning Enables Self-Evolving Agents
Jun 26, 2024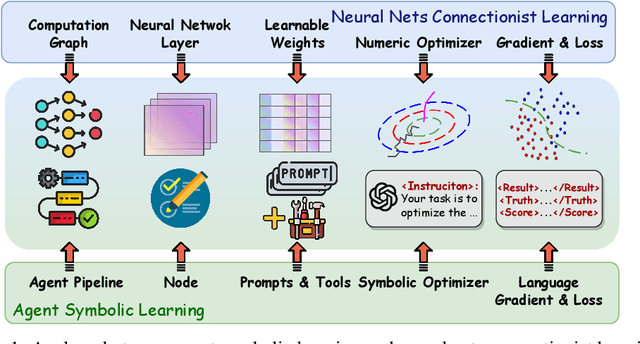
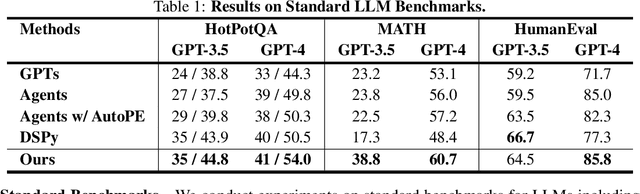
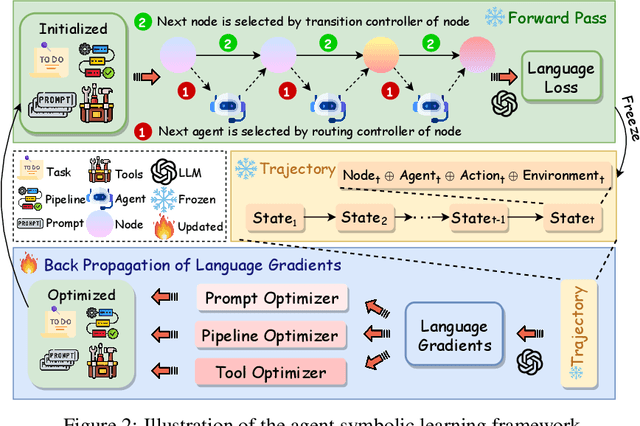
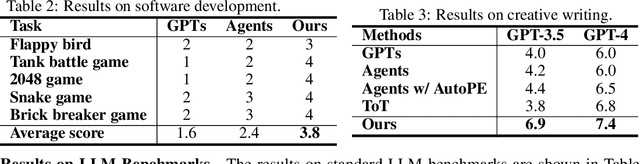
The AI community has been exploring a pathway to artificial general intelligence (AGI) by developing "language agents", which are complex large language models (LLMs) pipelines involving both prompting techniques and tool usage methods. While language agents have demonstrated impressive capabilities for many real-world tasks, a fundamental limitation of current language agents research is that they are model-centric, or engineering-centric. That's to say, the progress on prompts, tools, and pipelines of language agents requires substantial manual engineering efforts from human experts rather than automatically learning from data. We believe the transition from model-centric, or engineering-centric, to data-centric, i.e., the ability of language agents to autonomously learn and evolve in environments, is the key for them to possibly achieve AGI. In this work, we introduce agent symbolic learning, a systematic framework that enables language agents to optimize themselves on their own in a data-centric way using symbolic optimizers. Specifically, we consider agents as symbolic networks where learnable weights are defined by prompts, tools, and the way they are stacked together. Agent symbolic learning is designed to optimize the symbolic network within language agents by mimicking two fundamental algorithms in connectionist learning: back-propagation and gradient descent. Instead of dealing with numeric weights, agent symbolic learning works with natural language simulacrums of weights, loss, and gradients. We conduct proof-of-concept experiments on both standard benchmarks and complex real-world tasks and show that agent symbolic learning enables language agents to update themselves after being created and deployed in the wild, resulting in "self-evolving agents".
Weaver: Foundation Models for Creative Writing
Jan 30, 2024


This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
Agents: An Open-source Framework for Autonomous Language Agents
Sep 14, 2023Recent advances on large language models (LLMs) enable researchers and developers to build autonomous language agents that can automatically solve various tasks and interact with environments, humans, and other agents using natural language interfaces. We consider language agents as a promising direction towards artificial general intelligence and release Agents, an open-source library with the goal of opening up these advances to a wider non-specialist audience. Agents is carefully engineered to support important features including planning, memory, tool usage, multi-agent communication, and fine-grained symbolic control. Agents is user-friendly as it enables non-specialists to build, customize, test, tune, and deploy state-of-the-art autonomous language agents without much coding. The library is also research-friendly as its modularized design makes it easily extensible for researchers. Agents is available at https://github.com/aiwaves-cn/agents.