 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeaver: Foundation Models for Creative Writing
Jan 30, 2024

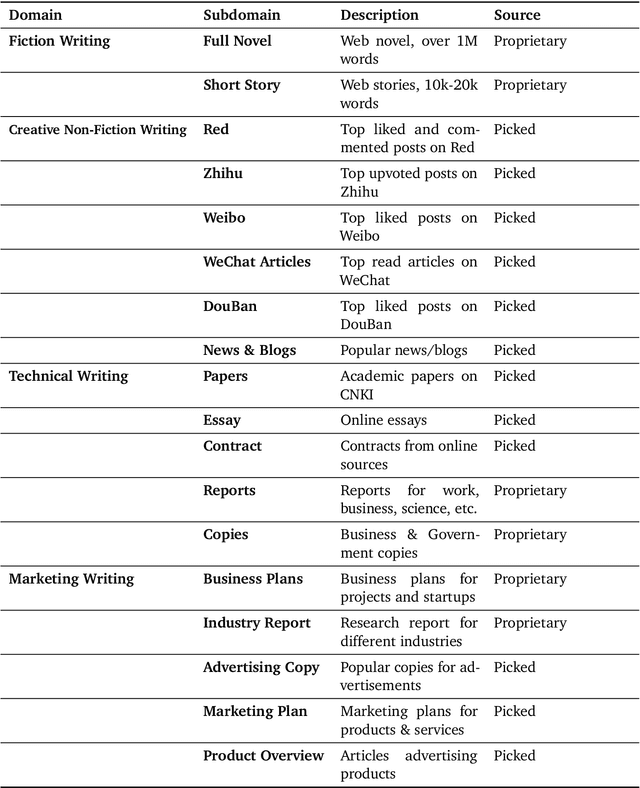

This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
Learning from Training Dynamics: Identifying Mislabeled Data Beyond Manually Designed Features
Dec 20, 2022
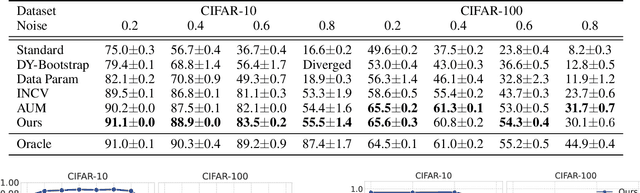
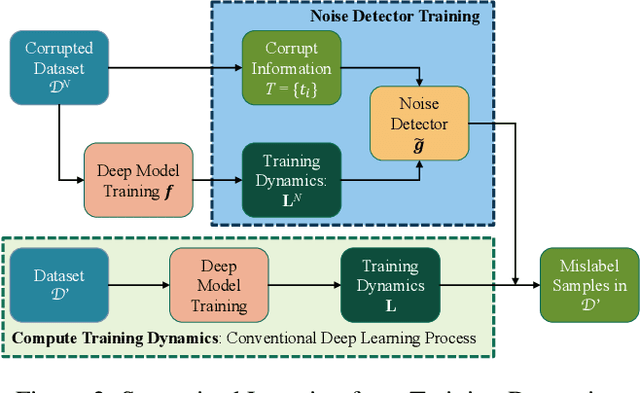

While mislabeled or ambiguously-labeled samples in the training set could negatively affect the performance of deep models, diagnosing the dataset and identifying mislabeled samples helps to improve the generalization power. Training dynamics, i.e., the traces left by iterations of optimization algorithms, have recently been proved to be effective to localize mislabeled samples with hand-crafted features. In this paper, beyond manually designed features, we introduce a novel learning-based solution, leveraging a noise detector, instanced by an LSTM network, which learns to predict whether a sample was mislabeled using the raw training dynamics as input. Specifically, the proposed method trains the noise detector in a supervised manner using the dataset with synthesized label noises and can adapt to various datasets (either naturally or synthesized label-noised) without retraining. We conduct extensive experiments to evaluate the proposed method. We train the noise detector based on the synthesized label-noised CIFAR dataset and test such noise detector on Tiny ImageNet, CUB-200, Caltech-256, WebVision and Clothing1M. Results show that the proposed method precisely detects mislabeled samples on various datasets without further adaptation, and outperforms state-of-the-art methods. Besides, more experiments demonstrate that the mislabel identification can guide a label correction, namely data debugging, providing orthogonal improvements of algorithm-centric state-of-the-art techniques from the data aspect.