 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALinFiK: Learning to Approximate Linearized Future Influence Kernel for Scalable Third-Parity LLM Data Valuation
Mar 02, 2025Large Language Models (LLMs) heavily rely on high-quality training data, making data valuation crucial for optimizing model performance, especially when working within a limited budget. In this work, we aim to offer a third-party data valuation approach that benefits both data providers and model developers. We introduce a linearized future influence kernel (LinFiK), which assesses the value of individual data samples in improving LLM performance during training. We further propose ALinFiK, a learning strategy to approximate LinFiK, enabling scalable data valuation. Our comprehensive evaluations demonstrate that this approach surpasses existing baselines in effectiveness and efficiency, demonstrating significant scalability advantages as LLM parameters increase.
InstructOCR: Instruction Boosting Scene Text Spotting
Dec 20, 2024In the field of scene text spotting, previous OCR methods primarily relied on image encoders and pre-trained text information, but they often overlooked the advantages of incorporating human language instructions. To address this gap, we propose InstructOCR, an innovative instruction-based scene text spotting model that leverages human language instructions to enhance the understanding of text within images. Our framework employs both text and image encoders during training and inference, along with instructions meticulously designed based on text attributes. This approach enables the model to interpret text more accurately and flexibly. Extensive experiments demonstrate the effectiveness of our model and we achieve state-of-the-art results on widely used benchmarks. Furthermore, the proposed framework can be seamlessly applied to scene text VQA tasks. By leveraging instruction strategies during pre-training, the performance on downstream VQA tasks can be significantly improved, with a 2.6% increase on the TextVQA dataset and a 2.1% increase on the ST-VQA dataset. These experimental results provide insights into the benefits of incorporating human language instructions for OCR-related tasks.
Symbolic Learning Enables Self-Evolving Agents
Jun 26, 2024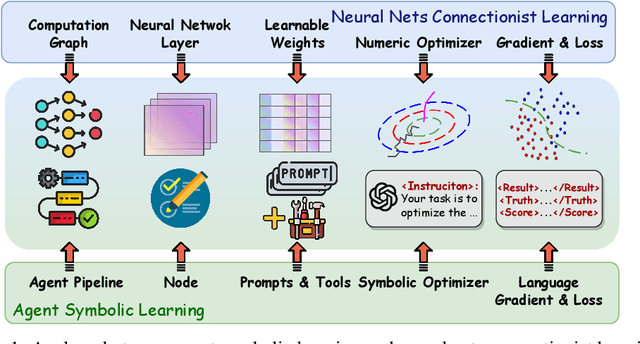
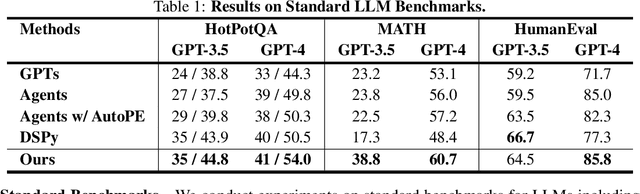
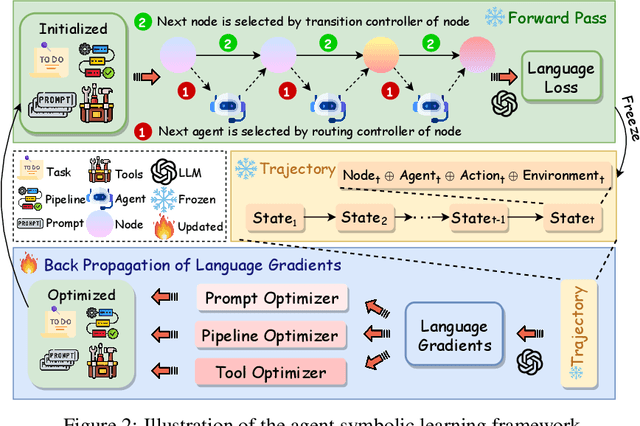
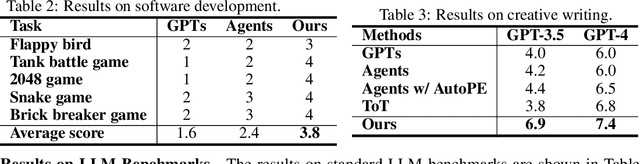
The AI community has been exploring a pathway to artificial general intelligence (AGI) by developing "language agents", which are complex large language models (LLMs) pipelines involving both prompting techniques and tool usage methods. While language agents have demonstrated impressive capabilities for many real-world tasks, a fundamental limitation of current language agents research is that they are model-centric, or engineering-centric. That's to say, the progress on prompts, tools, and pipelines of language agents requires substantial manual engineering efforts from human experts rather than automatically learning from data. We believe the transition from model-centric, or engineering-centric, to data-centric, i.e., the ability of language agents to autonomously learn and evolve in environments, is the key for them to possibly achieve AGI. In this work, we introduce agent symbolic learning, a systematic framework that enables language agents to optimize themselves on their own in a data-centric way using symbolic optimizers. Specifically, we consider agents as symbolic networks where learnable weights are defined by prompts, tools, and the way they are stacked together. Agent symbolic learning is designed to optimize the symbolic network within language agents by mimicking two fundamental algorithms in connectionist learning: back-propagation and gradient descent. Instead of dealing with numeric weights, agent symbolic learning works with natural language simulacrums of weights, loss, and gradients. We conduct proof-of-concept experiments on both standard benchmarks and complex real-world tasks and show that agent symbolic learning enables language agents to update themselves after being created and deployed in the wild, resulting in "self-evolving agents".
TIGER: Text-Instructed 3D Gaussian Retrieval and Coherent Editing
May 23, 2024Editing objects within a scene is a critical functionality required across a broad spectrum of applications in computer vision and graphics. As 3D Gaussian Splatting (3DGS) emerges as a frontier in scene representation, the effective modification of 3D Gaussian scenes has become increasingly vital. This process entails accurately retrieve the target objects and subsequently performing modifications based on instructions. Though available in pieces, existing techniques mainly embed sparse semantics into Gaussians for retrieval, and rely on an iterative dataset update paradigm for editing, leading to over-smoothing or inconsistency issues. To this end, this paper proposes a systematic approach, namely TIGER, for coherent text-instructed 3D Gaussian retrieval and editing. In contrast to the top-down language grounding approach for 3D Gaussians, we adopt a bottom-up language aggregation strategy to generate a denser language embedded 3D Gaussians that supports open-vocabulary retrieval. To overcome the over-smoothing and inconsistency issues in editing, we propose a Coherent Score Distillation (CSD) that aggregates a 2D image editing diffusion model and a multi-view diffusion model for score distillation, producing multi-view consistent editing with much finer details. In various experiments, we demonstrate that our TIGER is able to accomplish more consistent and realistic edits than prior work.
Weaver: Foundation Models for Creative Writing
Jan 30, 2024

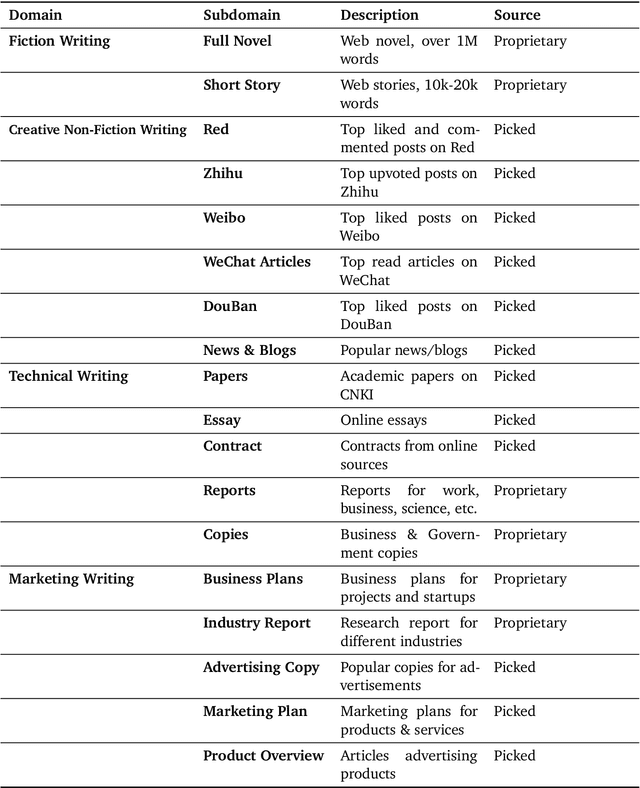

This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
Explanations of Classifiers Enhance Medical Image Segmentation via End-to-end Pre-training
Jan 16, 2024Medical image segmentation aims to identify and locate abnormal structures in medical images, such as chest radiographs, using deep neural networks. These networks require a large number of annotated images with fine-grained masks for the regions of interest, making pre-training strategies based on classification datasets essential for sample efficiency. Based on a large-scale medical image classification dataset, our work collects explanations from well-trained classifiers to generate pseudo labels of segmentation tasks. Specifically, we offer a case study on chest radiographs and train image classifiers on the CheXpert dataset to identify 14 pathological observations in radiology. We then use Integrated Gradients (IG) method to distill and boost the explanations obtained from the classifiers, generating massive diagnosis-oriented localization labels (DoLL). These DoLL-annotated images are used for pre-training the model before fine-tuning it for downstream segmentation tasks, including COVID-19 infectious areas, lungs, heart, and clavicles. Our method outperforms other baselines, showcasing significant advantages in model performance and training efficiency across various segmentation settings.
Towards Explainable Artificial Intelligence (XAI): A Data Mining Perspective
Jan 13, 2024



Given the complexity and lack of transparency in deep neural networks (DNNs), extensive efforts have been made to make these systems more interpretable or explain their behaviors in accessible terms. Unlike most reviews, which focus on algorithmic and model-centric perspectives, this work takes a "data-centric" view, examining how data collection, processing, and analysis contribute to explainable AI (XAI). We categorize existing work into three categories subject to their purposes: interpretations of deep models, referring to feature attributions and reasoning processes that correlate data points with model outputs; influences of training data, examining the impact of training data nuances, such as data valuation and sample anomalies, on decision-making processes; and insights of domain knowledge, discovering latent patterns and fostering new knowledge from data and models to advance social values and scientific discovery. Specifically, we distill XAI methodologies into data mining operations on training and testing data across modalities, such as images, text, and tabular data, as well as on training logs, checkpoints, models and other DNN behavior descriptors. In this way, our study offers a comprehensive, data-centric examination of XAI from a lens of data mining methods and applications.
GraphPAS: Parallel Architecture Search for Graph Neural Networks
Dec 07, 2021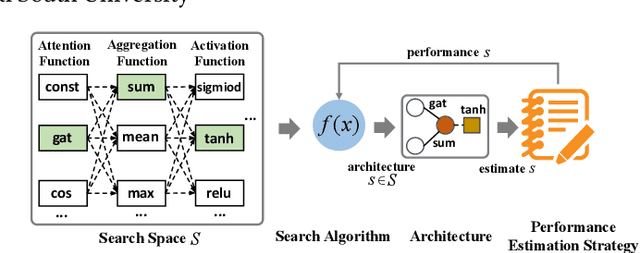

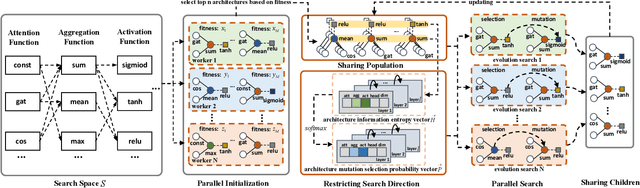
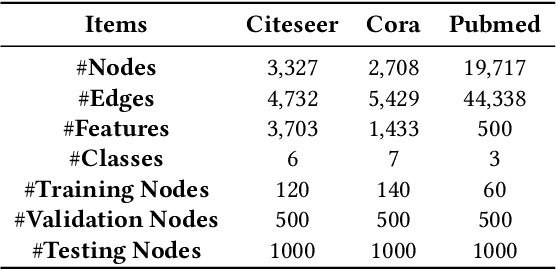
Graph neural architecture search has received a lot of attention as Graph Neural Networks (GNNs) has been successfully applied on the non-Euclidean data recently. However, exploring all possible GNNs architectures in the huge search space is too time-consuming or impossible for big graph data. In this paper, we propose a parallel graph architecture search (GraphPAS) framework for graph neural networks. In GraphPAS, we explore the search space in parallel by designing a sharing-based evolution learning, which can improve the search efficiency without losing the accuracy. Additionally, architecture information entropy is adopted dynamically for mutation selection probability, which can reduce space exploration. The experimental result shows that GraphPAS outperforms state-of-art models with efficiency and accuracy simultaneously.
Cross-layer Optimization for High Speed Adders: A Pareto Driven Machine Learning Approach
Oct 16, 2018
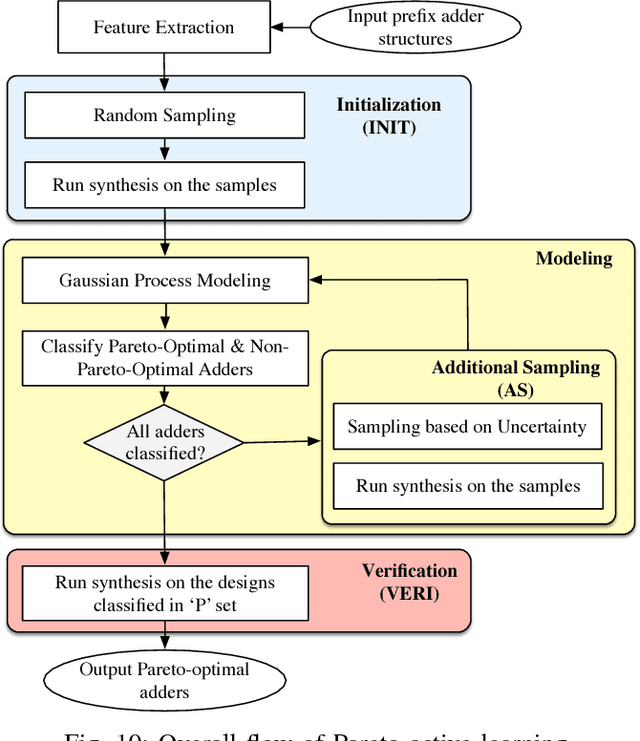
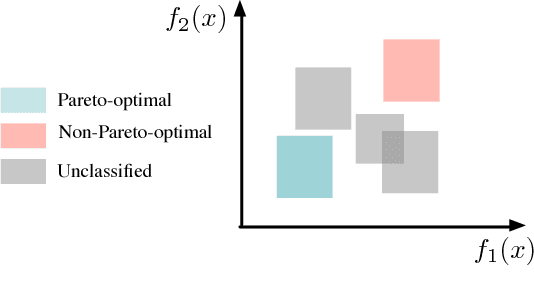
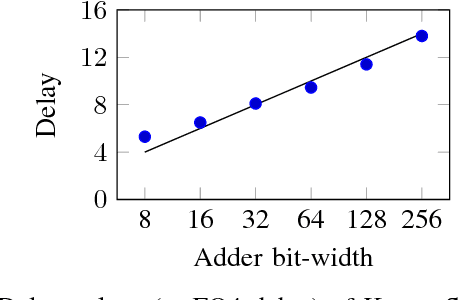
In spite of maturity to the modern electronic design automation (EDA) tools, optimized designs at architectural stage may become sub-optimal after going through physical design flow. Adder design has been such a long studied fundamental problem in VLSI industry yet designers cannot achieve optimal solutions by running EDA tools on the set of available prefix adder architectures. In this paper, we enhance a state-of-the-art prefix adder synthesis algorithm to obtain a much wider solution space in architectural domain. On top of that, a machine learning-based design space exploration methodology is applied to predict the Pareto frontier of the adders in physical domain, which is infeasible by exhaustively running EDA tools for innumerable architectural solutions. Considering the high cost of obtaining the true values for learning, an active learning algorithm is utilized to select the representative data during learning process, which uses less labeled data while achieving better quality of Pareto frontier. Experimental results demonstrate that our framework can achieve Pareto frontier of high quality over a wide design space, bridging the gap between architectural and physical designs.