 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion 3-to-4: 3D Motion Reconstruction for 4D Synthesis
Jan 20, 2026We present Motion 3-to-4, a feed-forward framework for synthesising high-quality 4D dynamic objects from a single monocular video and an optional 3D reference mesh. While recent advances have significantly improved 2D, video, and 3D content generation, 4D synthesis remains difficult due to limited training data and the inherent ambiguity of recovering geometry and motion from a monocular viewpoint. Motion 3-to-4 addresses these challenges by decomposing 4D synthesis into static 3D shape generation and motion reconstruction. Using a canonical reference mesh, our model learns a compact motion latent representation and predicts per-frame vertex trajectories to recover complete, temporally coherent geometry. A scalable frame-wise transformer further enables robustness to varying sequence lengths. Evaluations on both standard benchmarks and a new dataset with accurate ground-truth geometry show that Motion 3-to-4 delivers superior fidelity and spatial consistency compared to prior work. Project page is available at https://motion3-to-4.github.io/.
MCA-RG: Enhancing LLMs with Medical Concept Alignment for Radiology Report Generation
Jul 09, 2025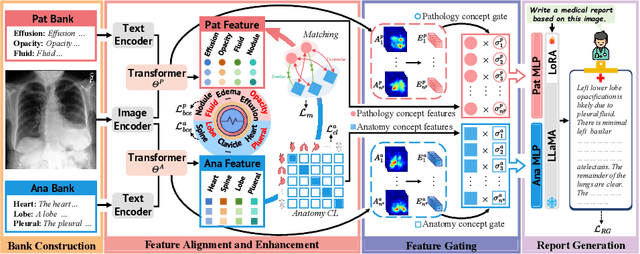
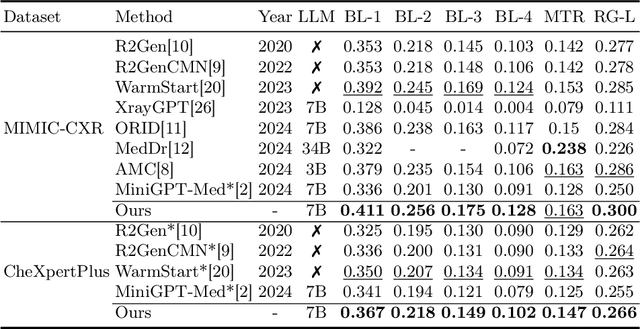
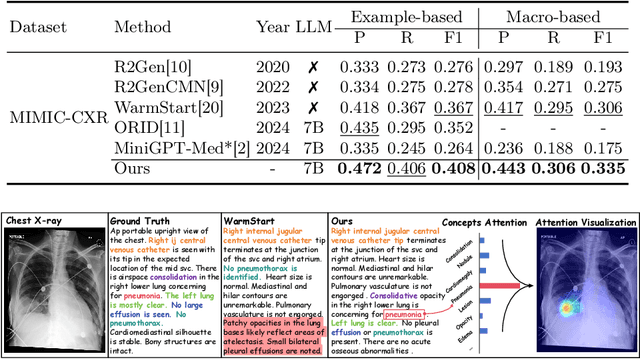
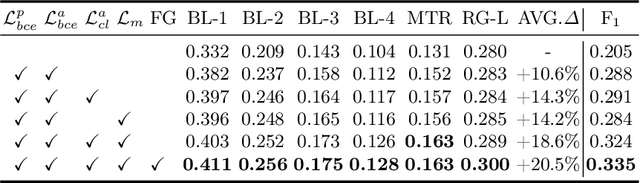
Despite significant advancements in adapting Large Language Models (LLMs) for radiology report generation (RRG), clinical adoption remains challenging due to difficulties in accurately mapping pathological and anatomical features to their corresponding text descriptions. Additionally, semantic agnostic feature extraction further hampers the generation of accurate diagnostic reports. To address these challenges, we introduce Medical Concept Aligned Radiology Report Generation (MCA-RG), a knowledge-driven framework that explicitly aligns visual features with distinct medical concepts to enhance the report generation process. MCA-RG utilizes two curated concept banks: a pathology bank containing lesion-related knowledge, and an anatomy bank with anatomical descriptions. The visual features are aligned with these medical concepts and undergo tailored enhancement. We further propose an anatomy-based contrastive learning procedure to improve the generalization of anatomical features, coupled with a matching loss for pathological features to prioritize clinically relevant regions. Additionally, a feature gating mechanism is employed to filter out low-quality concept features. Finally, the visual features are corresponding to individual medical concepts, and are leveraged to guide the report generation process. Experiments on two public benchmarks (MIMIC-CXR and CheXpert Plus) demonstrate that MCA-RG achieves superior performance, highlighting its effectiveness in radiology report generation.
RA-Touch: Retrieval-Augmented Touch Understanding with Enriched Visual Data
May 20, 2025Visuo-tactile perception aims to understand an object's tactile properties, such as texture, softness, and rigidity. However, the field remains underexplored because collecting tactile data is costly and labor-intensive. We observe that visually distinct objects can exhibit similar surface textures or material properties. For example, a leather sofa and a leather jacket have different appearances but share similar tactile properties. This implies that tactile understanding can be guided by material cues in visual data, even without direct tactile supervision. In this paper, we introduce RA-Touch, a retrieval-augmented framework that improves visuo-tactile perception by leveraging visual data enriched with tactile semantics. We carefully recaption a large-scale visual dataset with tactile-focused descriptions, enabling the model to access tactile semantics typically absent from conventional visual datasets. A key challenge remains in effectively utilizing these tactile-aware external descriptions. RA-Touch addresses this by retrieving visual-textual representations aligned with tactile inputs and integrating them to focus on relevant textural and material properties. By outperforming prior methods on the TVL benchmark, our method demonstrates the potential of retrieval-based visual reuse for tactile understanding. Code is available at https://aim-skku.github.io/RA-Touch
Seeing Cells Clearly: Evaluating Machine Vision Strategies for Microglia Centroid Detection in 3D Images
May 07, 2025Microglia are important cells in the brain, and their shape can tell us a lot about brain health. In this project, I test three different tools for finding the center points of microglia in 3D microscope images. The tools include ilastik, 3D Morph, and Omnipose. I look at how well each one finds the cells and how their results compare. My findings show that each tool sees the cells in its own way, and this can affect the kind of information we get from the images.
Question-Aware Gaussian Experts for Audio-Visual Question Answering
Mar 07, 2025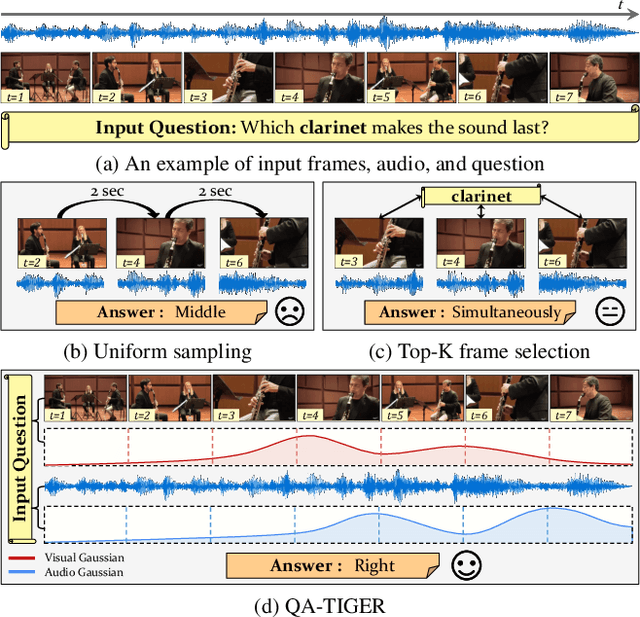

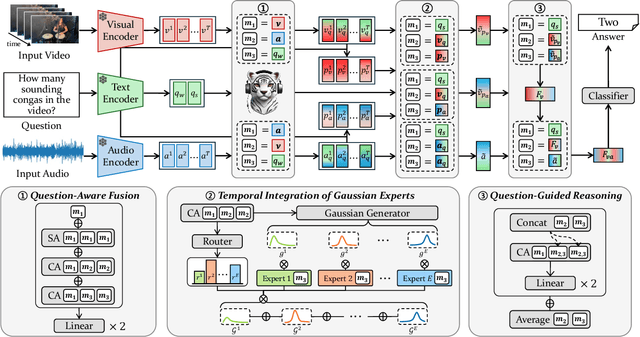
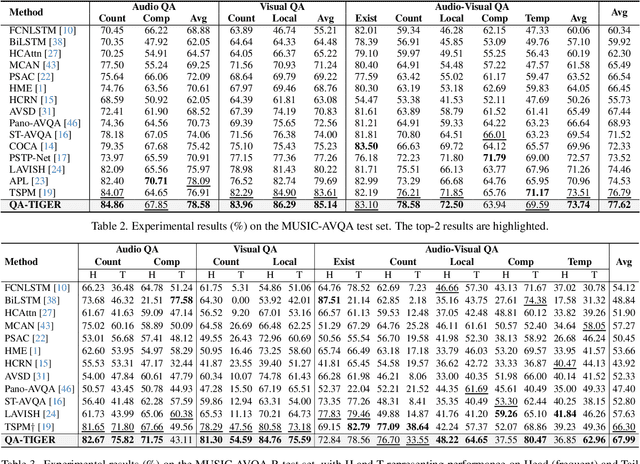
Audio-Visual Question Answering (AVQA) requires not only question-based multimodal reasoning but also precise temporal grounding to capture subtle dynamics for accurate prediction. However, existing methods mainly use question information implicitly, limiting focus on question-specific details. Furthermore, most studies rely on uniform frame sampling, which can miss key question-relevant frames. Although recent Top-K frame selection methods aim to address this, their discrete nature still overlooks fine-grained temporal details. This paper proposes QA-TIGER, a novel framework that explicitly incorporates question information and models continuous temporal dynamics. Our key idea is to use Gaussian-based modeling to adaptively focus on both consecutive and non-consecutive frames based on the question, while explicitly injecting question information and applying progressive refinement. We leverage a Mixture of Experts (MoE) to flexibly implement multiple Gaussian models, activating temporal experts specifically tailored to the question. Extensive experiments on multiple AVQA benchmarks show that QA-TIGER consistently achieves state-of-the-art performance. Code is available at https://aim-skku.github.io/QA-TIGER/
Ref-GS: Directional Factorization for 2D Gaussian Splatting
Dec 01, 2024



In this paper, we introduce Ref-GS, a novel approach for directional light factorization in 2D Gaussian splatting, which enables photorealistic view-dependent appearance rendering and precise geometry recovery. Ref-GS builds upon the deferred rendering of Gaussian splatting and applies directional encoding to the deferred-rendered surface, effectively reducing the ambiguity between orientation and viewing angle. Next, we introduce a spherical Mip-grid to capture varying levels of surface roughness, enabling roughness-aware Gaussian shading. Additionally, we propose a simple yet efficient geometry-lighting factorization that connects geometry and lighting via the vector outer product, significantly reducing renderer overhead when integrating volumetric attributes. Our method achieves superior photorealistic rendering for a range of open-world scenes while also accurately recovering geometry.
TIGER: Text-Instructed 3D Gaussian Retrieval and Coherent Editing
May 23, 2024Editing objects within a scene is a critical functionality required across a broad spectrum of applications in computer vision and graphics. As 3D Gaussian Splatting (3DGS) emerges as a frontier in scene representation, the effective modification of 3D Gaussian scenes has become increasingly vital. This process entails accurately retrieve the target objects and subsequently performing modifications based on instructions. Though available in pieces, existing techniques mainly embed sparse semantics into Gaussians for retrieval, and rely on an iterative dataset update paradigm for editing, leading to over-smoothing or inconsistency issues. To this end, this paper proposes a systematic approach, namely TIGER, for coherent text-instructed 3D Gaussian retrieval and editing. In contrast to the top-down language grounding approach for 3D Gaussians, we adopt a bottom-up language aggregation strategy to generate a denser language embedded 3D Gaussians that supports open-vocabulary retrieval. To overcome the over-smoothing and inconsistency issues in editing, we propose a Coherent Score Distillation (CSD) that aggregates a 2D image editing diffusion model and a multi-view diffusion model for score distillation, producing multi-view consistent editing with much finer details. In various experiments, we demonstrate that our TIGER is able to accomplish more consistent and realistic edits than prior work.
AMD:Anatomical Motion Diffusion with Interpretable Motion Decomposition and Fusion
Dec 21, 2023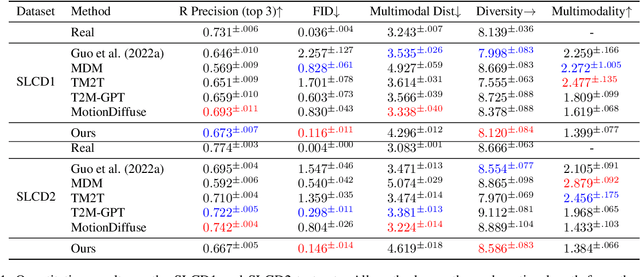
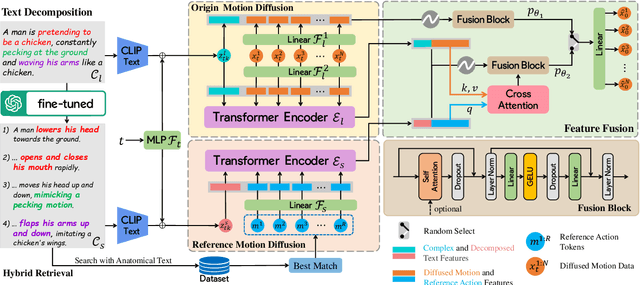
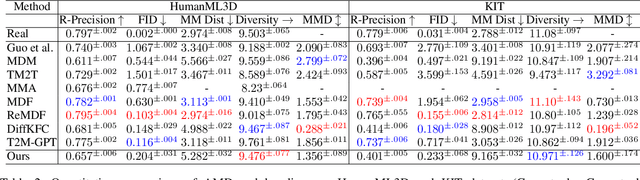

Generating realistic human motion sequences from text descriptions is a challenging task that requires capturing the rich expressiveness of both natural language and human motion.Recent advances in diffusion models have enabled significant progress in human motion synthesis.However, existing methods struggle to handle text inputs that describe complex or long motions.In this paper, we propose the Adaptable Motion Diffusion (AMD) model, which leverages a Large Language Model (LLM) to parse the input text into a sequence of concise and interpretable anatomical scripts that correspond to the target motion.This process exploits the LLM's ability to provide anatomical guidance for complex motion synthesis.We then devise a two-branch fusion scheme that balances the influence of the input text and the anatomical scripts on the inverse diffusion process, which adaptively ensures the semantic fidelity and diversity of the synthesized motion.Our method can effectively handle texts with complex or long motion descriptions, where existing methods often fail. Experiments on datasets with relatively more complex motions, such as CLCD1 and CLCD2, demonstrate that our AMD significantly outperforms existing state-of-the-art models.
Optimized View and Geometry Distillation from Multi-view Diffuser
Dec 17, 2023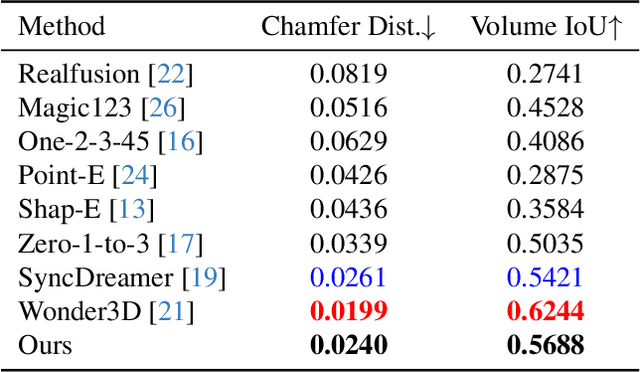

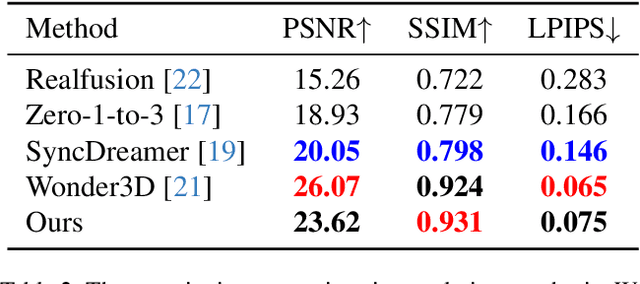
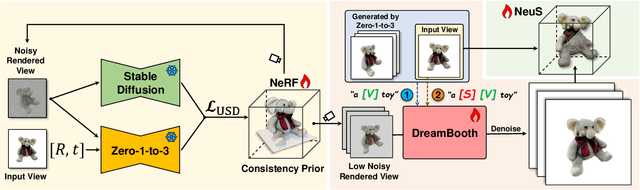
Generating multi-view images from a single input view using image-conditioned diffusion models is a recent advancement and has shown considerable potential. However, issues such as the lack of consistency in synthesized views and over-smoothing in extracted geometry persist. Previous methods integrate multi-view consistency modules or impose additional supervisory to enhance view consistency while compromising on the flexibility of camera positioning and limiting the versatility of view synthesis. In this study, we consider the radiance field optimized during geometry extraction as a more rigid consistency prior, compared to volume and ray aggregation used in previous works. We further identify and rectify a critical bias in the traditional radiance field optimization process through score distillation from a multi-view diffuser. We introduce an Unbiased Score Distillation (USD) that utilizes unconditioned noises from a 2D diffusion model, greatly refining the radiance field fidelity. we leverage the rendered views from the optimized radiance field as the basis and develop a two-step specialization process of a 2D diffusion model, which is adept at conducting object-specific denoising and generating high-quality multi-view images. Finally, we recover faithful geometry and texture directly from the refined multi-view images. Empirical evaluations demonstrate that our optimized geometry and view distillation technique generates comparable results to the state-of-the-art models trained on extensive datasets, all while maintaining freedom in camera positioning. Please see our project page at https://youjiazhang.github.io/USD/.
Fine-grained Appearance Transfer with Diffusion Models
Nov 27, 2023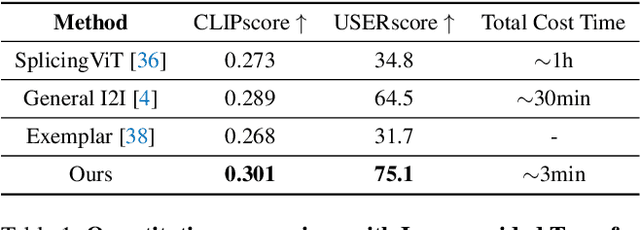

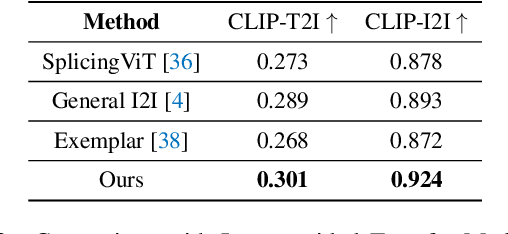
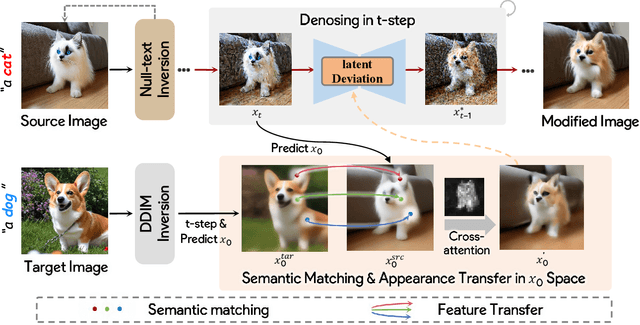
Image-to-image translation (I2I), and particularly its subfield of appearance transfer, which seeks to alter the visual appearance between images while maintaining structural coherence, presents formidable challenges. Despite significant advancements brought by diffusion models, achieving fine-grained transfer remains complex, particularly in terms of retaining detailed structural elements and ensuring information fidelity. This paper proposes an innovative framework designed to surmount these challenges by integrating various aspects of semantic matching, appearance transfer, and latent deviation. A pivotal aspect of our approach is the strategic use of the predicted $x_0$ space by diffusion models within the latent space of diffusion processes. This is identified as a crucial element for the precise and natural transfer of fine-grained details. Our framework exploits this space to accomplish semantic alignment between source and target images, facilitating mask-wise appearance transfer for improved feature acquisition. A significant advancement of our method is the seamless integration of these features into the latent space, enabling more nuanced latent deviations without necessitating extensive model retraining or fine-tuning. The effectiveness of our approach is demonstrated through extensive experiments, which showcase its ability to adeptly handle fine-grained appearance transfers across a wide range of categories and domains. We provide our code at https://github.com/babahui/Fine-grained-Appearance-Transfer