 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMD:Anatomical Motion Diffusion with Interpretable Motion Decomposition and Fusion
Dec 21, 2023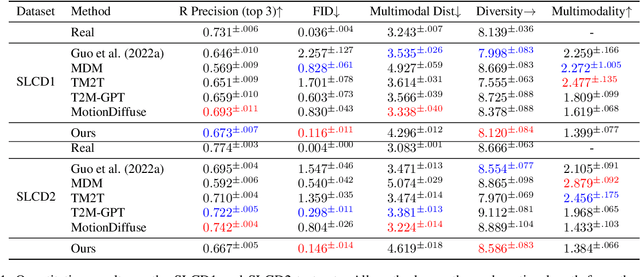
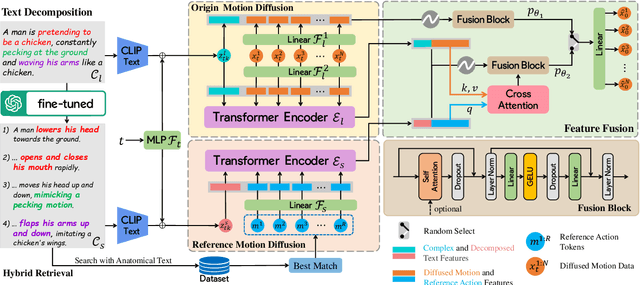
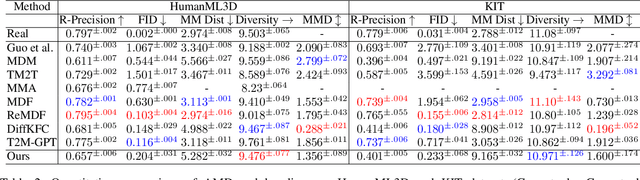

Generating realistic human motion sequences from text descriptions is a challenging task that requires capturing the rich expressiveness of both natural language and human motion.Recent advances in diffusion models have enabled significant progress in human motion synthesis.However, existing methods struggle to handle text inputs that describe complex or long motions.In this paper, we propose the Adaptable Motion Diffusion (AMD) model, which leverages a Large Language Model (LLM) to parse the input text into a sequence of concise and interpretable anatomical scripts that correspond to the target motion.This process exploits the LLM's ability to provide anatomical guidance for complex motion synthesis.We then devise a two-branch fusion scheme that balances the influence of the input text and the anatomical scripts on the inverse diffusion process, which adaptively ensures the semantic fidelity and diversity of the synthesized motion.Our method can effectively handle texts with complex or long motion descriptions, where existing methods often fail. Experiments on datasets with relatively more complex motions, such as CLCD1 and CLCD2, demonstrate that our AMD significantly outperforms existing state-of-the-art models.