 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Synergizing Vision Foundation Models via Self-organized Expert Specialization
Jun 02, 2026Unifying the complementary strengths of diverse Vision Foundation Models (VFMs) into a single efficient model is highly desirable but challenged by the negative transfer inherent in monolithic distillation. To address these feature conflicts, we introduce \textbf{PRISM}, a novel dual-stream Mixture-of-Experts (MoE) framework that synergizes VFMs via modular specialization. We propose a two-stage paradigm: (1) expertise deconstruction, where a teacher-conditional router guides experts to specialize in distinct representational subspaces to mitigate interference, followed by (2) dynamic recomposition, where the router learns to assemble these experts into tailored computational pathways for downstream tasks. Experiments on PASCAL-Context and NYUD-v2 show that \textbf{PRISM} establishes a new state of the art, validating that sparse, emergent specialization is a scalable approach for integrating diverse visual knowledge.
HotComment: A Benchmark for Evaluating Popularity of Online Comments
Apr 28, 2026Online comments play a crucial role in shaping public sentiment and opinion dynamics on social media. However, evaluating their popularity remains challenging, not only because it depends on linguistic quality, originality, and emotional resonance, but also because stylistic preferences vary widely across platforms and user groups, causing the same comment to resonate differently in different communities. In this work, we present HotComment, a multimodal benchmark integrating video and text modalities that comprehensively quantifies popularity from three enhanced aspects: (1) Content Quality, which evaluates semantic similarity with ground-truth human comments and extends quality assessment through four interpretable dimensions; (2) Popularity Prediction, based on trends from models trained on real-world interaction data; and (3) User Behavior Simulation, which models the distribution of platform users and approximates \textbf{engagement scores} through an agent-based framework. Furthermore, we propose StyleCmt, inspired by social ripple effects, where multiple stylistic dimensions align to amplify socially resonant expressions and suppress incongruent ones.
Seeing Further and Wider: Joint Spatio-Temporal Enlargement for Micro-Video Popularity Prediction
Apr 22, 2026Micro-video popularity prediction (MVPP) aims to forecast the future popularity of videos on online media, which is essential for applications such as content recommendation and traffic allocation. In real-world scenarios, it is critical for MVPP approaches to understand both the temporal dynamics of a given video (temporal) and its historical relevance to other videos (spatial). However, existing approaches sufer from limitations in both dimensions: temporally, they rely on sparse short-range sampling that restricts content perception; spatially, they depend on flat retrieval memory with limited capacity and low efficiency, hindering scalable knowledge utilization. To overcome these limitations, we propose a unified framework that achieves joint spatio-temporal enlargement, enabling precise perception of extremely long video sequences while supporting a scalable memory bank that can infinitely expand to incorporate all relevant historical videos. Technically, we employ a Temporal Enlargement driven by a frame scoring module that extracts highlight cues from video frames through two complementary pathways: sparse sampling and dense perception. Their outputs are adaptively fused to enable robust long-sequence content understanding. For Spatial Enlargement, we construct a Topology-Aware Memory Bank that hierarchically clusters historically relevant content based on topological relationships. Instead of directly expanding memory capacity, we update the encoder features of the corresponding clusters when incorporating new videos, enabling unbounded historical association without unbounded storage growth. Extensive experiments on three widely used MVPP benchmarks demonstrate that our method consistently outperforms 11 strong baselines across mainstream metrics, achieving robust improvements in both prediction accuracy and ranking consistency.
Hypergraph-State Collaborative Reasoning for Multi-Object Tracking
Apr 14, 2026Motion reasoning serves as the cornerstone of multi-object tracking (MOT), as it enables consistent association of targets across frames. However, existing motion estimation approaches face two major limitations: (1) instability caused by noisy or probabilistic predictions, and (2) vulnerability under occlusion, where trajectories often fragment once visual cues disappear. To overcome these issues, we propose a collaborative reasoning framework that enhances motion estimation through joint inference among multiple correlated objects. By allowing objects with similar motion states to mutually constrain and refine each other, our framework stabilizes noisy trajectories and infers plausible motion continuity even when target is occluded. To realize this concept, we design HyperSSM, an architecture that integrates Hypergraph computation and a State Space Model (SSM) for unified spatial-temporal reasoning. The Hypergraph module captures spatial motion correlations through dynamic hyperedges, while the SSM enforces temporal smoothness via structured state transitions. This synergistic design enables simultaneous optimization of spatial consensus and temporal coherence, resulting in robust and stable motion estimation. Extensive experiments on four mainstream and diverse benchmarks(MOT17, MOT20, DanceTrack, and SportsMOT) covering various motion patterns and scene complexities, demonstrate that our approach achieves state-of-the-art performance across a wide range of tracking scenarios.
Logical Phase Transitions: Understanding Collapse in LLM Logical Reasoning
Jan 06, 2026Symbolic logical reasoning is a critical yet underexplored capability of large language models (LLMs), providing reliable and verifiable decision-making in high-stakes domains such as mathematical reasoning and legal judgment. In this study, we present a systematic analysis of logical reasoning under controlled increases in logical complexity, and reveal a previously unrecognized phenomenon, which we term Logical Phase Transitions: rather than degrading smoothly, logical reasoning performance remains stable within a regime but collapses abruptly beyond a critical logical depth, mirroring physical phase transitions such as water freezing beyond a critical temperature threshold. Building on this insight, we propose Neuro-Symbolic Curriculum Tuning, a principled framework that adaptively aligns natural language with logical symbols to establish a shared representation, and reshapes training dynamics around phase-transition boundaries to progressively strengthen reasoning at increasing logical depths. Experiments on five benchmarks show that our approach effectively mitigates logical reasoning collapse at high complexity, yielding average accuracy gains of +1.26 in naive prompting and +3.95 in CoT, while improving generalization to unseen logical compositions. Code and data are available at https://github.com/AI4SS/Logical-Phase-Transitions.
MCA-RG: Enhancing LLMs with Medical Concept Alignment for Radiology Report Generation
Jul 09, 2025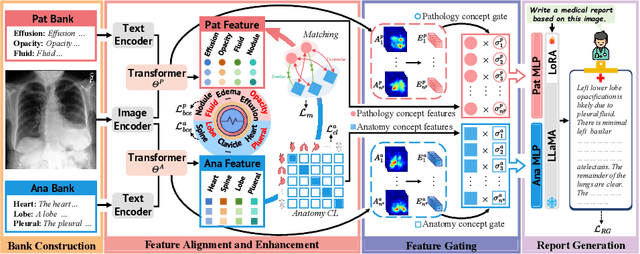
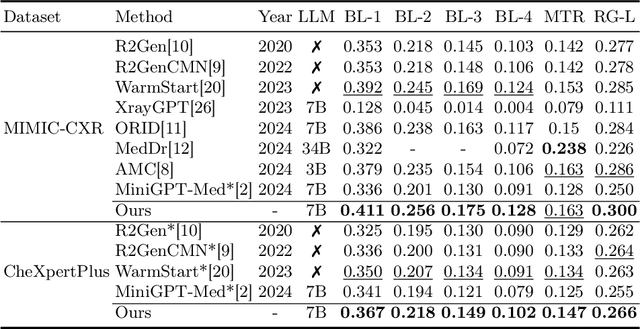
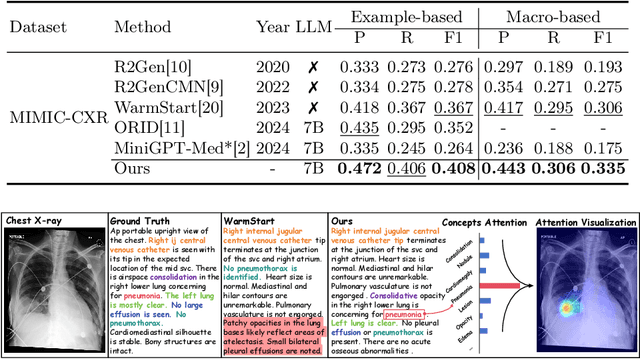
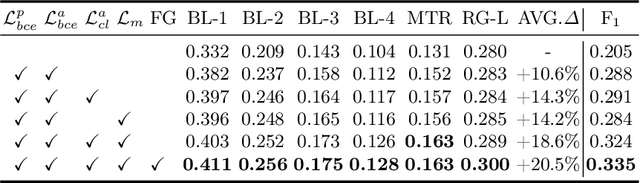
Despite significant advancements in adapting Large Language Models (LLMs) for radiology report generation (RRG), clinical adoption remains challenging due to difficulties in accurately mapping pathological and anatomical features to their corresponding text descriptions. Additionally, semantic agnostic feature extraction further hampers the generation of accurate diagnostic reports. To address these challenges, we introduce Medical Concept Aligned Radiology Report Generation (MCA-RG), a knowledge-driven framework that explicitly aligns visual features with distinct medical concepts to enhance the report generation process. MCA-RG utilizes two curated concept banks: a pathology bank containing lesion-related knowledge, and an anatomy bank with anatomical descriptions. The visual features are aligned with these medical concepts and undergo tailored enhancement. We further propose an anatomy-based contrastive learning procedure to improve the generalization of anatomical features, coupled with a matching loss for pathological features to prioritize clinically relevant regions. Additionally, a feature gating mechanism is employed to filter out low-quality concept features. Finally, the visual features are corresponding to individual medical concepts, and are leveraged to guide the report generation process. Experiments on two public benchmarks (MIMIC-CXR and CheXpert Plus) demonstrate that MCA-RG achieves superior performance, highlighting its effectiveness in radiology report generation.
Cross-Modality Masked Learning for Survival Prediction in ICI Treated NSCLC Patients
Jul 09, 2025Accurate prognosis of non-small cell lung cancer (NSCLC) patients undergoing immunotherapy is essential for personalized treatment planning, enabling informed patient decisions, and improving both treatment outcomes and quality of life. However, the lack of large, relevant datasets and effective multi-modal feature fusion strategies pose significant challenges in this domain. To address these challenges, we present a large-scale dataset and introduce a novel framework for multi-modal feature fusion aimed at enhancing the accuracy of survival prediction. The dataset comprises 3D CT images and corresponding clinical records from NSCLC patients treated with immune checkpoint inhibitors (ICI), along with progression-free survival (PFS) and overall survival (OS) data. We further propose a cross-modality masked learning approach for medical feature fusion, consisting of two distinct branches, each tailored to its respective modality: a Slice-Depth Transformer for extracting 3D features from CT images and a graph-based Transformer for learning node features and relationships among clinical variables in tabular data. The fusion process is guided by a masked modality learning strategy, wherein the model utilizes the intact modality to reconstruct missing components. This mechanism improves the integration of modality-specific features, fostering more effective inter-modality relationships and feature interactions. Our approach demonstrates superior performance in multi-modal integration for NSCLC survival prediction, surpassing existing methods and setting a new benchmark for prognostic models in this context.
MVP: Winning Solution to SMP Challenge 2025 Video Track
Jul 01, 2025Social media platforms serve as central hubs for content dissemination, opinion expression, and public engagement across diverse modalities. Accurately predicting the popularity of social media videos enables valuable applications in content recommendation, trend detection, and audience engagement. In this paper, we present Multimodal Video Predictor (MVP), our winning solution to the Video Track of the SMP Challenge 2025. MVP constructs expressive post representations by integrating deep video features extracted from pretrained models with user metadata and contextual information. The framework applies systematic preprocessing techniques, including log-transformations and outlier removal, to improve model robustness. A gradient-boosted regression model is trained to capture complex patterns across modalities. Our approach ranked first in the official evaluation of the Video Track, demonstrating its effectiveness and reliability for multimodal video popularity prediction on social platforms. The source code is available at https://anonymous.4open.science/r/SMPDVideo.
HyperFusion: Hierarchical Multimodal Ensemble Learning for Social Media Popularity Prediction
Jul 01, 2025Social media popularity prediction plays a crucial role in content optimization, marketing strategies, and user engagement enhancement across digital platforms. However, predicting post popularity remains challenging due to the complex interplay between visual, textual, temporal, and user behavioral factors. This paper presents HyperFusion, a hierarchical multimodal ensemble learning framework for social media popularity prediction. Our approach employs a three-tier fusion architecture that progressively integrates features across abstraction levels: visual representations from CLIP encoders, textual embeddings from transformer models, and temporal-spatial metadata with user characteristics. The framework implements a hierarchical ensemble strategy combining CatBoost, TabNet, and custom multi-layer perceptrons. To address limited labeled data, we propose a two-stage training methodology with pseudo-labeling and iterative refinement. We introduce novel cross-modal similarity measures and hierarchical clustering features that capture inter-modal dependencies. Experimental results demonstrate that HyperFusion achieves competitive performance on the SMP challenge dataset. Our team achieved third place in the SMP Challenge 2025 (Image Track). The source code is available at https://anonymous.4open.science/r/SMPDImage.
SF2T: Self-supervised Fragment Finetuning of Video-LLMs for Fine-Grained Understanding
Apr 10, 2025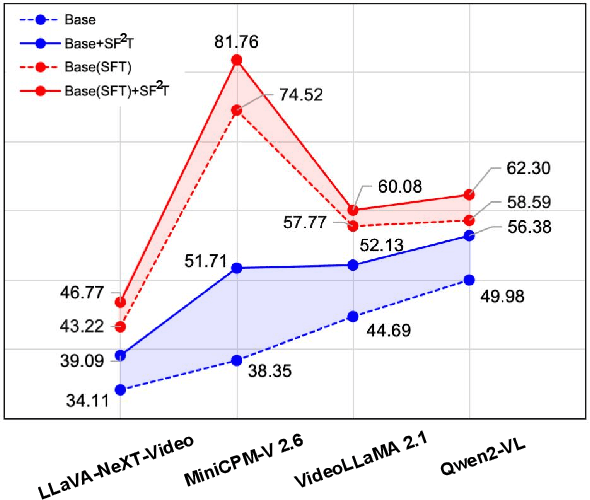



Video-based Large Language Models (Video-LLMs) have witnessed substantial advancements in recent years, propelled by the advancement in multi-modal LLMs. Although these models have demonstrated proficiency in providing the overall description of videos, they struggle with fine-grained understanding, particularly in aspects such as visual dynamics and video details inquiries. To tackle these shortcomings, we find that fine-tuning Video-LLMs on self-supervised fragment tasks, greatly improve their fine-grained video understanding abilities. Hence we propose two key contributions:(1) Self-Supervised Fragment Fine-Tuning (SF$^2$T), a novel effortless fine-tuning method, employs the rich inherent characteristics of videos for training, while unlocking more fine-grained understanding ability of Video-LLMs. Moreover, it relieves researchers from labor-intensive annotations and smartly circumvents the limitations of natural language, which often fails to capture the complex spatiotemporal variations in videos; (2) A novel benchmark dataset, namely FineVidBench, for rigorously assessing Video-LLMs' performance at both the scene and fragment levels, offering a comprehensive evaluation of their capabilities. We assessed multiple models and validated the effectiveness of SF$^2$T on them. Experimental results reveal that our approach improves their ability to capture and interpret spatiotemporal details.