 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiViBench: An Omnimodal Benchmark for Interactive Livestream Video Understanding
Jan 21, 2026The development of multimodal large language models (MLLMs) has advanced general video understanding. However, existing video evaluation benchmarks primarily focus on non-interactive videos, such as movies and recordings. To fill this gap, this paper proposes the first omnimodal benchmark for interactive livestream videos, LiViBench. It features a diverse set of 24 tasks, highlighting the perceptual, reasoning, and livestream-specific challenges. To efficiently construct the dataset, we design a standardized semi-automatic annotation workflow that incorporates the human-in-the-loop at multiple stages. The workflow leverages multiple MLLMs to form a multi-agent system for comprehensive video description and uses a seed-question-driven method to construct high-quality annotations. All interactive videos in the benchmark include audio, speech, and real-time comments modalities. To enhance models' understanding of interactive videos, we design tailored two-stage instruction-tuning and propose a Video-to-Comment Retrieval (VCR) module to improve the model's ability to utilize real-time comments. Based on these advancements, we develop LiVi-LLM-7B, an MLLM with enhanced knowledge of interactive livestreams. Experiments show that our model outperforms larger open-source models with up to 72B parameters, narrows the gap with leading proprietary models on LiViBench, and achieves enhanced performance on general video benchmarks, including VideoMME, LongVideoBench, MLVU, and VideoEval-Pro.
GAP: Graph-Assisted Prompts for Dialogue-based Medication Recommendation
May 19, 2025Medication recommendations have become an important task in the healthcare domain, especially in measuring the accuracy and safety of medical dialogue systems (MDS). Different from the recommendation task based on electronic health records (EHRs), dialogue-based medication recommendations require research on the interaction details between patients and doctors, which is crucial but may not exist in EHRs. Recent advancements in large language models (LLM) have extended the medical dialogue domain. These LLMs can interpret patients' intent and provide medical suggestions including medication recommendations, but some challenges are still worth attention. During a multi-turn dialogue, LLMs may ignore the fine-grained medical information or connections across the dialogue turns, which is vital for providing accurate suggestions. Besides, LLMs may generate non-factual responses when there is a lack of domain-specific knowledge, which is more risky in the medical domain. To address these challenges, we propose a \textbf{G}raph-\textbf{A}ssisted \textbf{P}rompts (\textbf{GAP}) framework for dialogue-based medication recommendation. It extracts medical concepts and corresponding states from dialogue to construct an explicitly patient-centric graph, which can describe the neglected but important information. Further, combined with external medical knowledge graphs, GAP can generate abundant queries and prompts, thus retrieving information from multiple sources to reduce the non-factual responses. We evaluate GAP on a dialogue-based medication recommendation dataset and further explore its potential in a more difficult scenario, dynamically diagnostic interviewing. Extensive experiments demonstrate its competitive performance when compared with strong baselines.
MouseGPT: A Large-scale Vision-Language Model for Mouse Behavior Analysis
Mar 13, 2025Analyzing animal behavior is crucial in advancing neuroscience, yet quantifying and deciphering its intricate dynamics remains a significant challenge. Traditional machine vision approaches, despite their ability to detect spontaneous behaviors, fall short due to limited interpretability and reliance on manual labeling, which restricts the exploration of the full behavioral spectrum. Here, we introduce MouseGPT, a Vision-Language Model (VLM) that integrates visual cues with natural language to revolutionize mouse behavior analysis. Built upon our first-of-its-kind dataset - incorporating pose dynamics and open-vocabulary behavioral annotations across over 42 million frames of diverse psychiatric conditions - MouseGPT provides a novel, context-rich method for comprehensive behavior interpretation. Our holistic analysis framework enables detailed behavior profiling, clustering, and novel behavior discovery, offering deep insights without the need for labor - intensive manual annotation. Evaluations reveal that MouseGPT surpasses existing models in precision, adaptability, and descriptive richness, positioning it as a transformative tool for ethology and for unraveling complex behavioral dynamics in animal models.
TIGER: Text-Instructed 3D Gaussian Retrieval and Coherent Editing
May 23, 2024Editing objects within a scene is a critical functionality required across a broad spectrum of applications in computer vision and graphics. As 3D Gaussian Splatting (3DGS) emerges as a frontier in scene representation, the effective modification of 3D Gaussian scenes has become increasingly vital. This process entails accurately retrieve the target objects and subsequently performing modifications based on instructions. Though available in pieces, existing techniques mainly embed sparse semantics into Gaussians for retrieval, and rely on an iterative dataset update paradigm for editing, leading to over-smoothing or inconsistency issues. To this end, this paper proposes a systematic approach, namely TIGER, for coherent text-instructed 3D Gaussian retrieval and editing. In contrast to the top-down language grounding approach for 3D Gaussians, we adopt a bottom-up language aggregation strategy to generate a denser language embedded 3D Gaussians that supports open-vocabulary retrieval. To overcome the over-smoothing and inconsistency issues in editing, we propose a Coherent Score Distillation (CSD) that aggregates a 2D image editing diffusion model and a multi-view diffusion model for score distillation, producing multi-view consistent editing with much finer details. In various experiments, we demonstrate that our TIGER is able to accomplish more consistent and realistic edits than prior work.
Are LLM-based Evaluators Confusing NLG Quality Criteria?
Feb 19, 2024



Some prior work has shown that LLMs perform well in NLG evaluation for different tasks. However, we discover that LLMs seem to confuse different evaluation criteria, which reduces their reliability. For further verification, we first consider avoiding issues of inconsistent conceptualization and vague expression in existing NLG quality criteria themselves. So we summarize a clear hierarchical classification system for 11 common aspects with corresponding different criteria from previous studies involved. Inspired by behavioral testing, we elaborately design 18 types of aspect-targeted perturbation attacks for fine-grained analysis of the evaluation behaviors of different LLMs. We also conduct human annotations beyond the guidance of the classification system to validate the impact of the perturbations. Our experimental results reveal confusion issues inherent in LLMs, as well as other noteworthy phenomena, and necessitate further research and improvements for LLM-based evaluation.
S2M: Converting Single-Turn to Multi-Turn Datasets for Conversational Question Answering
Dec 27, 2023Supplying data augmentation to conversational question answering (CQA) can effectively improve model performance. However, there is less improvement from single-turn datasets in CQA due to the distribution gap between single-turn and multi-turn datasets. On the other hand, while numerous single-turn datasets are available, we have not utilized them effectively. To solve this problem, we propose a novel method to convert single-turn datasets to multi-turn datasets. The proposed method consists of three parts, namely, a QA pair Generator, a QA pair Reassembler, and a question Rewriter. Given a sample consisting of context and single-turn QA pairs, the Generator obtains candidate QA pairs and a knowledge graph based on the context. The Reassembler utilizes the knowledge graph to get sequential QA pairs, and the Rewriter rewrites questions from a conversational perspective to obtain a multi-turn dataset S2M. Our experiments show that our method can synthesize effective training resources for CQA. Notably, S2M ranks 1st place on the QuAC leaderboard at the time of submission (Aug 24th, 2022).
AdapterDistillation: Non-Destructive Task Composition with Knowledge Distillation
Dec 26, 2023



Leveraging knowledge from multiple tasks through introducing a small number of task specific parameters into each transformer layer, also known as adapters, receives much attention recently. However, adding an extra fusion layer to implement knowledge composition not only increases the inference time but also is non-scalable for some applications. To avoid these issues, we propose a two-stage knowledge distillation algorithm called AdapterDistillation. In the first stage, we extract task specific knowledge by using local data to train a student adapter. In the second stage, we distill the knowledge from the existing teacher adapters into the student adapter to help its inference. Extensive experiments on frequently asked question retrieval in task-oriented dialog systems validate the efficiency of AdapterDistillation. We show that AdapterDistillation outperforms existing algorithms in terms of accuracy, resource consumption and inference time.
From Beginner to Expert: Modeling Medical Knowledge into General LLMs
Dec 02, 2023



Recently, large language model (LLM) based artificial intelligence (AI) systems have demonstrated remarkable capabilities in natural language understanding and generation. However, these models face a significant challenge when it comes to sensitive applications, such as reasoning over medical knowledge and answering medical questions in a physician-like manner. Prior studies attempted to overcome this challenge by increasing the model size (>100B) to learn more general medical knowledge, while there is still room for improvement in LLMs with smaller-scale model sizes (<100B). In this work, we start from a pre-trained general LLM model (AntGLM-10B) and fine-tune it from a medical beginner towards a medical expert (called AntGLM-Med-10B), which leverages a 3-stage optimization procedure, \textit{i.e.}, general medical knowledge injection, medical domain instruction tuning, and specific medical task adaptation. Our contributions are threefold: (1) We specifically investigate how to adapt a pre-trained general LLM in medical domain, especially for a specific medical task. (2) We collect and construct large-scale medical datasets for each stage of the optimization process. These datasets encompass various data types and tasks, such as question-answering, medical reasoning, multi-choice questions, and medical conversations. (3) Specifically for multi-choice questions in the medical domain, we propose a novel Verification-of-Choice approach for prompting engineering, which significantly enhances the reasoning ability of LLMs. Remarkably, by combining the above approaches, our AntGLM-Med-10B model can outperform the most of LLMs on PubMedQA, including both general and medical LLMs, even when these LLMs have larger model size.
NeMF: Inverse Volume Rendering with Neural Microflake Field
Apr 04, 2023



Recovering the physical attributes of an object's appearance from its images captured under an unknown illumination is challenging yet essential for photo-realistic rendering. Recent approaches adopt the emerging implicit scene representations and have shown impressive results.However, they unanimously adopt a surface-based representation,and hence can not well handle scenes with very complex geometry, translucent object and etc. In this paper, we propose to conduct inverse volume rendering, in contrast to surface-based, by representing a scene using microflake volume, which assumes the space is filled with infinite small flakes and light reflects or scatters at each spatial location according to microflake distributions. We further adopt the coordinate networks to implicitly encode the microflake volume, and develop a differentiable microflake volume renderer to train the network in an end-to-end way in principle.Our NeMF enables effective recovery of appearance attributes for highly complex geometry and scattering object, enables high-quality relighting, material editing, and especially simulates volume rendering effects, such as scattering, which is infeasible for surface-based approaches.
Relightable Neural Human Assets from Multi-view Gradient Illuminations
Dec 16, 2022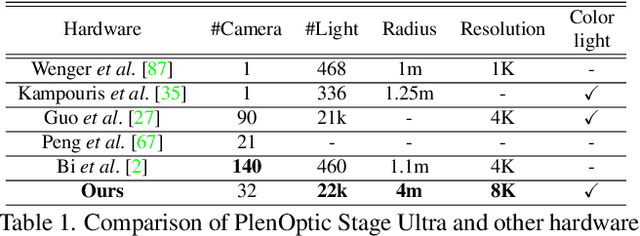


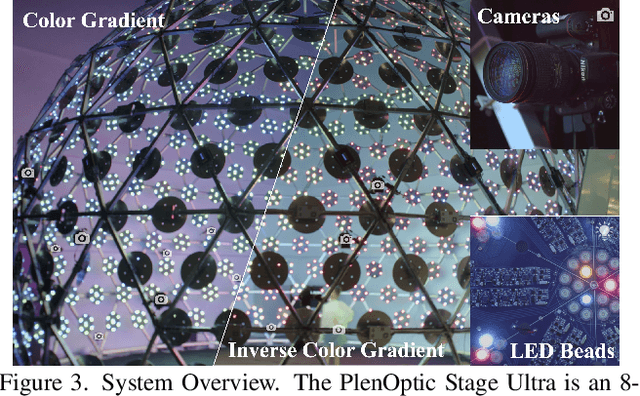
Human modeling and relighting are two fundamental problems in computer vision and graphics, where high-quality datasets can largely facilitate related research. However, most existing human datasets only provide multi-view human images captured under the same illumination. Although valuable for modeling tasks, they are not readily used in relighting problems. To promote research in both fields, in this paper, we present UltraStage, a new 3D human dataset that contains more than 2K high-quality human assets captured under both multi-view and multi-illumination settings. Specifically, for each example, we provide 32 surrounding views illuminated with one white light and two gradient illuminations. In addition to regular multi-view images, gradient illuminations help recover detailed surface normal and spatially-varying material maps, enabling various relighting applications. Inspired by recent advances in neural representation, we further interpret each example into a neural human asset which allows novel view synthesis under arbitrary lighting conditions. We show our neural human assets can achieve extremely high capture performance and are capable of representing fine details such as facial wrinkles and cloth folds. We also validate UltraStage in single image relighting tasks, training neural networks with virtual relighted data from neural assets and demonstrating realistic rendering improvements over prior arts. UltraStage will be publicly available to the community to stimulate significant future developments in various human modeling and rendering tasks.