 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeMF: Inverse Volume Rendering with Neural Microflake Field
Apr 04, 2023



Recovering the physical attributes of an object's appearance from its images captured under an unknown illumination is challenging yet essential for photo-realistic rendering. Recent approaches adopt the emerging implicit scene representations and have shown impressive results.However, they unanimously adopt a surface-based representation,and hence can not well handle scenes with very complex geometry, translucent object and etc. In this paper, we propose to conduct inverse volume rendering, in contrast to surface-based, by representing a scene using microflake volume, which assumes the space is filled with infinite small flakes and light reflects or scatters at each spatial location according to microflake distributions. We further adopt the coordinate networks to implicitly encode the microflake volume, and develop a differentiable microflake volume renderer to train the network in an end-to-end way in principle.Our NeMF enables effective recovery of appearance attributes for highly complex geometry and scattering object, enables high-quality relighting, material editing, and especially simulates volume rendering effects, such as scattering, which is infeasible for surface-based approaches.
Active Domain Adaptation with Multi-level Contrastive Units for Semantic Segmentation
May 25, 2022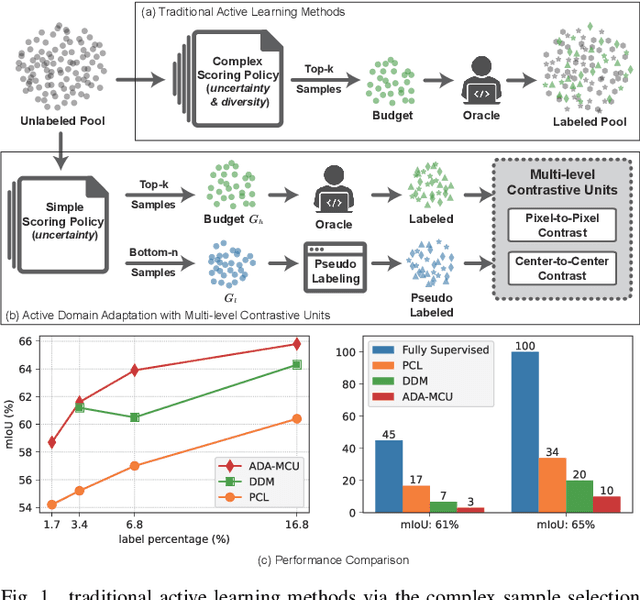
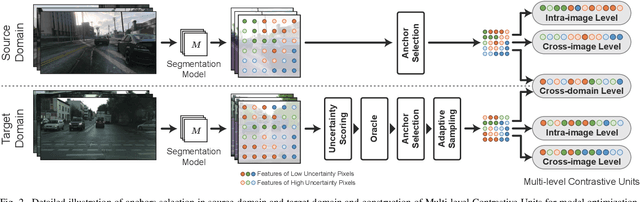
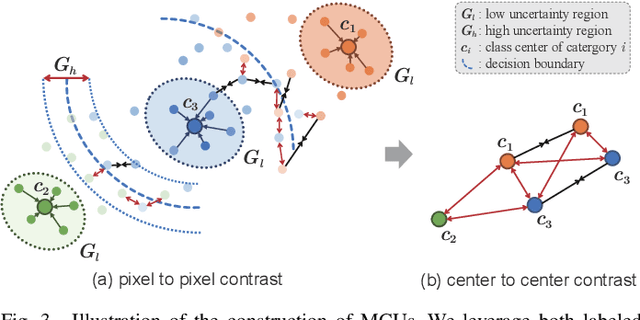
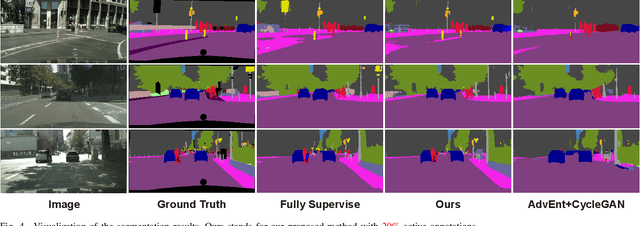
To further reduce the cost of semi-supervised domain adaptation (SSDA) labeling, a more effective way is to use active learning (AL) to annotate a selected subset with specific properties. However, domain adaptation tasks are always addressed in two interactive aspects: domain transfer and the enhancement of discrimination, which requires the selected data to be both uncertain under the model and diverse in feature space. Contrary to active learning in classification tasks, it is usually challenging to select pixels that contain both the above properties in segmentation tasks, leading to the complex design of pixel selection strategy. To address such an issue, we propose a novel Active Domain Adaptation scheme with Multi-level Contrastive Units (ADA-MCU) for semantic image segmentation. A simple pixel selection strategy followed with the construction of multi-level contrastive units is introduced to optimize the model for both domain adaptation and active supervised learning. In practice, MCUs are constructed from intra-image, cross-image, and cross-domain levels by using both labeled and unlabeled pixels. At each level, we define contrastive losses from center-to-center and pixel-to-pixel manners, with the aim of jointly aligning the category centers and reducing outliers near the decision boundaries. In addition, we also introduce a categories correlation matrix to implicitly describe the relationship between categories, which are used to adjust the weights of the losses for MCUs. Extensive experimental results on standard benchmarks show that the proposed method achieves competitive performance against state-of-the-art SSDA methods with 50% fewer labeled pixels and significantly outperforms state-of-the-art with a large margin by using the same level of annotation cost.
High-resolution Face Swapping via Latent Semantics Disentanglement
Mar 30, 2022

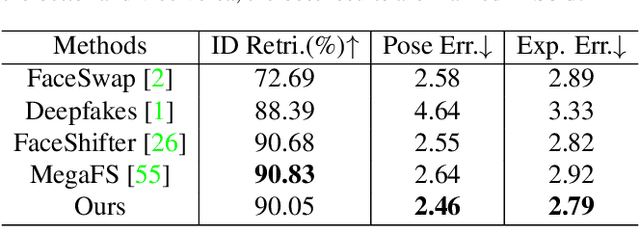

We present a novel high-resolution face swapping method using the inherent prior knowledge of a pre-trained GAN model. Although previous research can leverage generative priors to produce high-resolution results, their quality can suffer from the entangled semantics of the latent space. We explicitly disentangle the latent semantics by utilizing the progressive nature of the generator, deriving structure attributes from the shallow layers and appearance attributes from the deeper ones. Identity and pose information within the structure attributes are further separated by introducing a landmark-driven structure transfer latent direction. The disentangled latent code produces rich generative features that incorporate feature blending to produce a plausible swapping result. We further extend our method to video face swapping by enforcing two spatio-temporal constraints on the latent space and the image space. Extensive experiments demonstrate that the proposed method outperforms state-of-the-art image/video face swapping methods in terms of hallucination quality and consistency. Code can be found at: https://github.com/cnnlstm/FSLSD_HiRes.