 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMouseGPT: A Large-scale Vision-Language Model for Mouse Behavior Analysis
Mar 13, 2025Analyzing animal behavior is crucial in advancing neuroscience, yet quantifying and deciphering its intricate dynamics remains a significant challenge. Traditional machine vision approaches, despite their ability to detect spontaneous behaviors, fall short due to limited interpretability and reliance on manual labeling, which restricts the exploration of the full behavioral spectrum. Here, we introduce MouseGPT, a Vision-Language Model (VLM) that integrates visual cues with natural language to revolutionize mouse behavior analysis. Built upon our first-of-its-kind dataset - incorporating pose dynamics and open-vocabulary behavioral annotations across over 42 million frames of diverse psychiatric conditions - MouseGPT provides a novel, context-rich method for comprehensive behavior interpretation. Our holistic analysis framework enables detailed behavior profiling, clustering, and novel behavior discovery, offering deep insights without the need for labor - intensive manual annotation. Evaluations reveal that MouseGPT surpasses existing models in precision, adaptability, and descriptive richness, positioning it as a transformative tool for ethology and for unraveling complex behavioral dynamics in animal models.
Exploring the Spatiotemporal Features of Online Food Recommendation Service
Aug 08, 2023Online Food Recommendation Service (OFRS) has remarkable spatiotemporal characteristics and the advantage of being able to conveniently satisfy users' needs in a timely manner. There have been a variety of studies that have begun to explore its spatiotemporal properties, but a comprehensive and in-depth analysis of the OFRS spatiotemporal features is yet to be conducted. Therefore, this paper studies the OFRS based on three questions: how spatiotemporal features play a role; why self-attention cannot be used to model the spatiotemporal sequences of OFRS; and how to combine spatiotemporal features to improve the efficiency of OFRS. Firstly, through experimental analysis, we systemically extracted the spatiotemporal features of OFRS, identified the most valuable features and designed an effective combination method. Secondly, we conducted a detailed analysis of the spatiotemporal sequences, which revealed the shortcomings of self-attention in OFRS, and proposed a more optimized spatiotemporal sequence method for replacing self-attention. In addition, we also designed a Dynamic Context Adaptation Model to further improve the efficiency and performance of OFRS. Through the offline experiments on two large datasets and online experiments for a week, the feasibility and superiority of our model were proven.
Multi-Granularity Attention Model for Group Recommendation
Aug 08, 2023Group recommendation provides personalized recommendations to a group of users based on their shared interests, preferences, and characteristics. Current studies have explored different methods for integrating individual preferences and making collective decisions that benefit the group as a whole. However, most of them heavily rely on users with rich behavior and ignore latent preferences of users with relatively sparse behavior, leading to insufficient learning of individual interests. To address this challenge, we present the Multi-Granularity Attention Model (MGAM), a novel approach that utilizes multiple levels of granularity (i.e., subsets, groups, and supersets) to uncover group members' latent preferences and mitigate recommendation noise. Specially, we propose a Subset Preference Extraction module that enhances the representation of users' latent subset-level preferences by incorporating their previous interactions with items and utilizing a hierarchical mechanism. Additionally, our method introduces a Group Preference Extraction module and a Superset Preference Extraction module, which explore users' latent preferences on two levels: the group-level, which maintains users' original preferences, and the superset-level, which includes group-group exterior information. By incorporating the subset-level embedding, group-level embedding, and superset-level embedding, our proposed method effectively reduces group recommendation noise across multiple granularities and comprehensively learns individual interests. Extensive offline and online experiments have demonstrated the superiority of our method in terms of performance.
Relightable Neural Human Assets from Multi-view Gradient Illuminations
Dec 16, 2022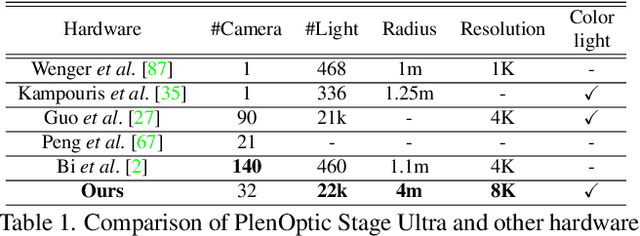


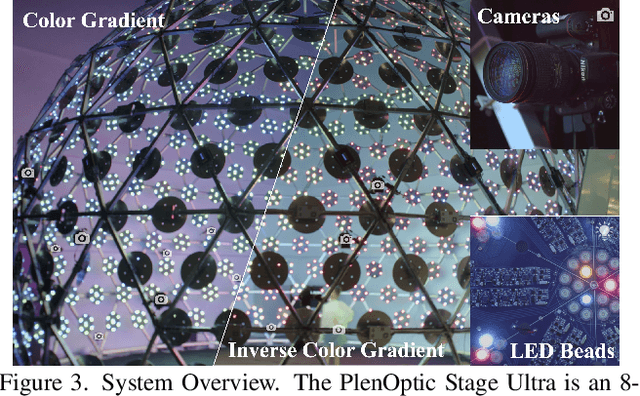
Human modeling and relighting are two fundamental problems in computer vision and graphics, where high-quality datasets can largely facilitate related research. However, most existing human datasets only provide multi-view human images captured under the same illumination. Although valuable for modeling tasks, they are not readily used in relighting problems. To promote research in both fields, in this paper, we present UltraStage, a new 3D human dataset that contains more than 2K high-quality human assets captured under both multi-view and multi-illumination settings. Specifically, for each example, we provide 32 surrounding views illuminated with one white light and two gradient illuminations. In addition to regular multi-view images, gradient illuminations help recover detailed surface normal and spatially-varying material maps, enabling various relighting applications. Inspired by recent advances in neural representation, we further interpret each example into a neural human asset which allows novel view synthesis under arbitrary lighting conditions. We show our neural human assets can achieve extremely high capture performance and are capable of representing fine details such as facial wrinkles and cloth folds. We also validate UltraStage in single image relighting tasks, training neural networks with virtual relighted data from neural assets and demonstrating realistic rendering improvements over prior arts. UltraStage will be publicly available to the community to stimulate significant future developments in various human modeling and rendering tasks.
BASM: A Bottom-up Adaptive Spatiotemporal Model for Online Food Ordering Service
Nov 22, 2022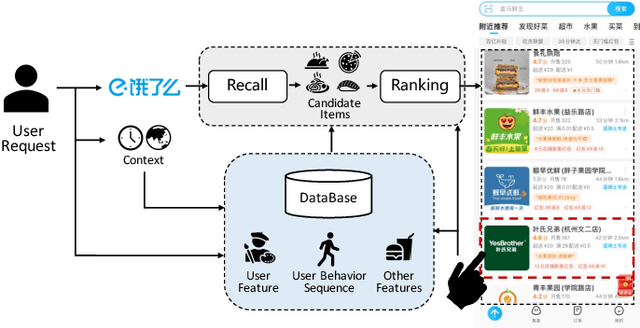
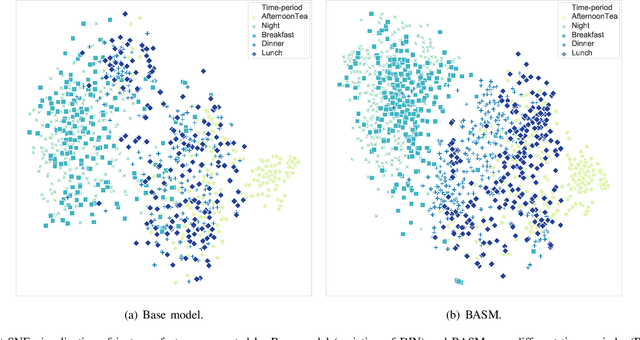
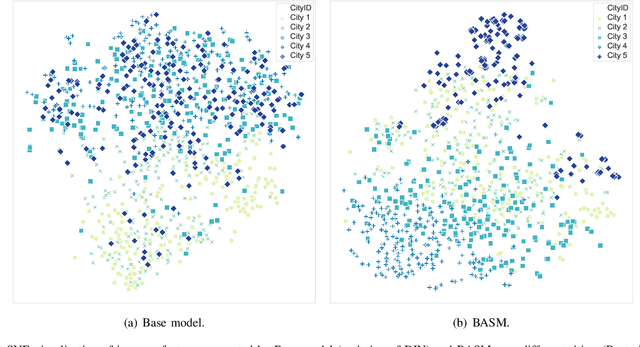
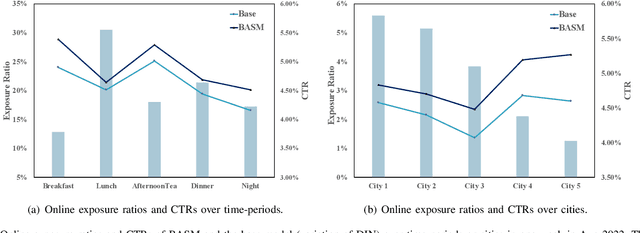
Online Food Ordering Service (OFOS) is a popular location-based service that helps people to order what you want. Compared with traditional e-commerce recommendation systems, users' interests may be diverse under different spatiotemporal contexts, leading to various spatiotemporal data distribution, which limits the fitting capacity of the model. However, numerous current works simply mix all samples to train a set of model parameters, which makes it difficult to capture the diversity in different spatiotemporal contexts. Therefore, we address this challenge by proposing a Bottom-up Adaptive Spatiotemporal Model(BASM) to adaptively fit the spatiotemporal data distribution, which further improve the fitting capability of the model. Specifically, a spatiotemporal-aware embedding layer performs weight adaptation on field granularity in feature embedding, to achieve the purpose of dynamically perceiving spatiotemporal contexts. Meanwhile, we propose a spatiotemporal semantic transformation layer to explicitly convert the concatenated input of the raw semantic to spatiotemporal semantic, which can further enhance the semantic representation under different spatiotemporal contexts. Furthermore, we introduce a novel spatiotemporal adaptive bias tower to capture diverse spatiotemporal bias, reducing the difficulty to model spatiotemporal distinction. To further verify the effectiveness of BASM, we also novelly propose two new metrics, Time-period-wise AUC (TAUC) and City-wise AUC (CAUC). Extensive offline evaluations on public and industrial datasets are conducted to demonstrate the effectiveness of our proposed modle. The online A/B experiment also further illustrates the practicability of the model online service. This proposed method has now been implemented on the Ele.me, a major online food ordering platform in China, serving more than 100 million online users.
Spatiotemporal-Enhanced Network for Click-Through Rate Prediction in Location-based Services
Sep 20, 2022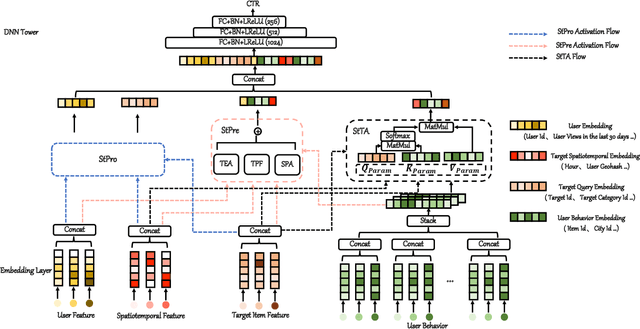
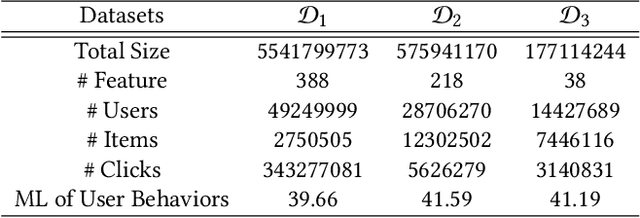
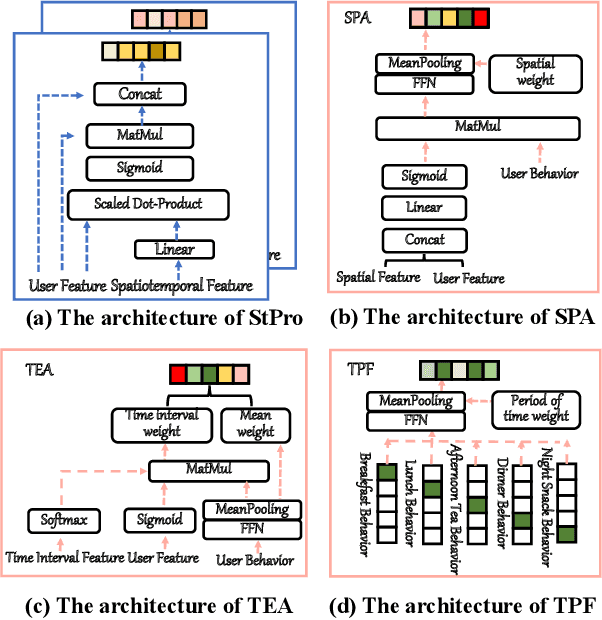
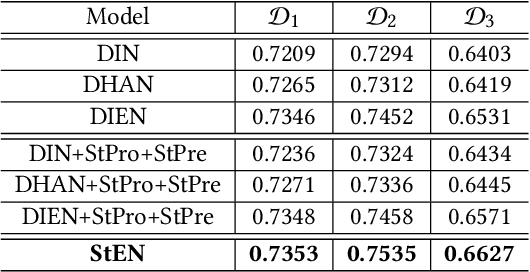
In Location-Based Services(LBS), user behavior naturally has a strong dependence on the spatiotemporal information, i.e., in different geographical locations and at different times, user click behavior will change significantly. Appropriate spatiotemporal enhancement modeling of user click behavior and large-scale sparse attributes is key to building an LBS model. Although most of existing methods have been proved to be effective, they are difficult to apply to takeaway scenarios due to insufficient modeling of spatiotemporal information. In this paper, we address this challenge by seeking to explicitly model the timing and locations of interactions and proposing a Spatiotemporal-Enhanced Network, namely StEN. In particular, StEN applies a Spatiotemporal Profile Activation module to capture common spatiotemporal preference through attribute features. A Spatiotemporal Preference Activation is further applied to model the personalized spatiotemporal preference embodied by behaviors in detail. Moreover, a Spatiotemporal-aware Target Attention mechanism is adopted to generate different parameters for target attention at different locations and times, thereby improving the personalized spatiotemporal awareness of the model.Comprehensive experiments are conducted on three large-scale industrial datasets, and the results demonstrate the state-of-the-art performance of our methods. In addition, we have also released an industrial dataset for takeaway industry to make up for the lack of public datasets in this community.
Digital-twin-enhanced metal tube bending forming real-time prediction method based on Multi-source-input MTL
Jul 03, 2022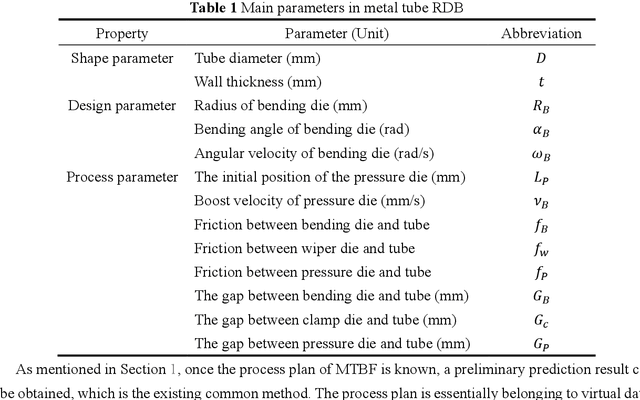



As one of the most widely used metal tube bending methods, the rotary draw bending (RDB) process enables reliable and high-precision metal tube bending forming (MTBF). The forming accuracy is seriously affected by the springback and other potential forming defects, of which the mechanism analysis is difficult to deal with. At the same time, the existing methods are mainly conducted in offline space, ignoring the real-time information in the physical world, which is unreliable and inefficient. To address this issue, a digital-twin-enhanced (DT-enhanced) metal tube bending forming real-time prediction method based on multi-source-input multi-task learning (MTL) is proposed. The new method can achieve comprehensive MTBF real-time prediction. By sharing the common feature of the multi-close domain and adopting group regularization strategy on feature sharing and accepting layers, the accuracy and efficiency of the multi-source-input MTL can be guaranteed. Enhanced by DT, the physical real-time deformation data is aligned in the image dimension by an improved Grammy Angle Field (GAF) conversion, realizing the reflection of the actual processing. Different from the traditional offline prediction methods, the new method integrates the virtual and physical data to achieve a more efficient and accurate real-time prediction result. and the DT mapping connection between virtual and physical systems can be achieved. To exclude the effects of equipment errors, the effectiveness of the proposed method is verified on the physical experiment-verified FE simulation scenarios. At the same time, the common pre-training networks are compared with the proposed method. The results show that the proposed DT-enhanced prediction method is more accurate and efficient.
A generic physics-informed neural network-based framework for reliability assessment of multi-state systems
Dec 01, 2021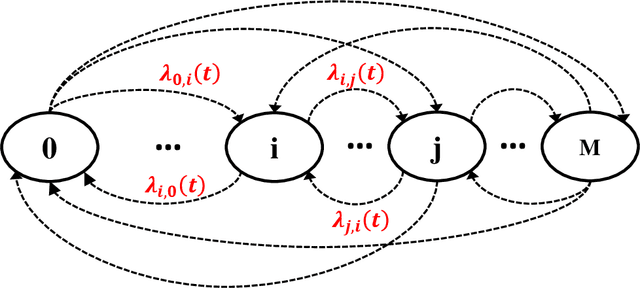

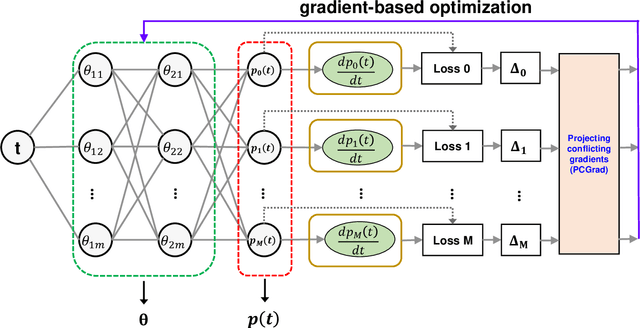
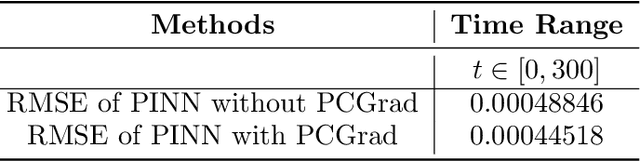
In this paper, we leverage the recent advances in physics-informed neural network (PINN) and develop a generic PINN-based framework to assess the reliability of multi-state systems (MSSs). The proposed methodology consists of two major steps. In the first step, we recast the reliability assessment of MSS as a machine learning problem using the framework of PINN. A feedforward neural network with two individual loss groups are constructed to encode the initial condition and state transitions governed by ordinary differential equations (ODEs) in MSS. Next, we tackle the problem of high imbalance in the magnitude of the back-propagated gradients in PINN from a multi-task learning perspective. Particularly, we treat each element in the loss function as an individual task, and adopt a gradient surgery approach named projecting conflicting gradients (PCGrad), where a task's gradient is projected onto the norm plane of any other task that has a conflicting gradient. The gradient projection operation significantly mitigates the detrimental effects caused by the gradient interference when training PINN, thus accelerating the convergence speed of PINN to high-precision solutions to MSS reliability assessment. With the proposed PINN-based framework, we investigate its applications for MSS reliability assessment in several different contexts in terms of time-independent or dependent state transitions and system scales varying from small to medium. The results demonstrate that the proposed PINN-based framework shows generic and remarkable performance in MSS reliability assessment, and the incorporation of PCGrad in PINN leads to substantial improvement in solution quality and convergence speed.
An Uncertainty-Informed Framework for Trustworthy Fault Diagnosis in Safety-Critical Applications
Oct 08, 2021


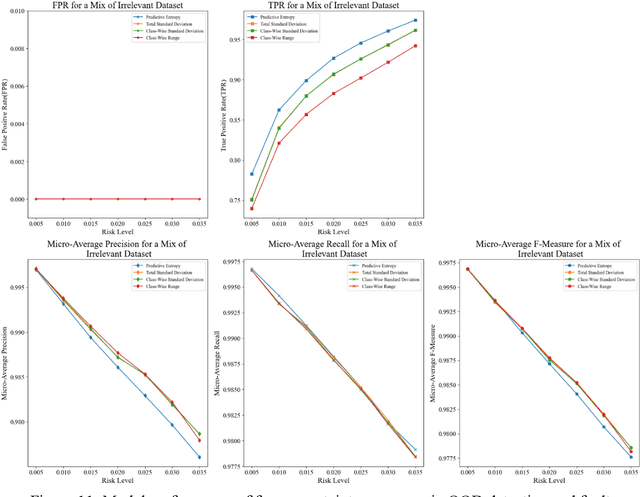
There has been a growing interest in deep learning-based prognostic and health management (PHM) for building end-to-end maintenance decision support systems, especially due to the rapid development of autonomous systems. However, the low trustworthiness of PHM hinders its applications in safety-critical assets when handling data from an unknown distribution that differs from the training dataset, referred to as the out-of-distribution (OOD) dataset. To bridge this gap, we propose an uncertainty-informed framework to diagnose faults and meanwhile detect the OOD dataset, enabling the capability of learning unknowns and achieving trustworthy fault diagnosis. Particularly, we develop a probabilistic Bayesian convolutional neural network (CNN) to quantify both epistemic and aleatory uncertainties in fault diagnosis. The fault diagnosis model flags the OOD dataset with large predictive uncertainty for expert intervention and is confident in providing predictions for the data within tolerable uncertainty. This results in trustworthy fault diagnosis and reduces the risk of erroneous decision-making, thus potentially avoiding undesirable consequences. The proposed framework is demonstrated by the fault diagnosis of bearings with three OOD datasets attributed to random number generation, an unknown fault mode, and four common sensor faults, respectively. The results show that the proposed framework is of particular advantage in tackling unknowns and enhancing the trustworthiness of fault diagnosis in safety-critical applications.
Physics-Informed Deep Learning: A Promising Technique for System Reliability Assessment
Sep 05, 2021


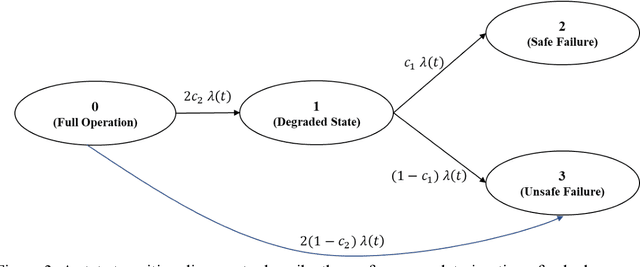
Considerable research has been devoted to deep learning-based predictive models for system prognostics and health management in the reliability and safety community. However, there is limited study on the utilization of deep learning for system reliability assessment. This paper aims to bridge this gap and explore this new interface between deep learning and system reliability assessment by exploiting the recent advances of physics-informed deep learning. Particularly, we present an approach to frame system reliability assessment in the context of physics-informed deep learning and discuss the potential value of physics-informed generative adversarial networks for the uncertainty quantification and measurement data incorporation in system reliability assessment. The proposed approach is demonstrated by three numerical examples involving a dual-processor computing system. The results indicate the potential value of physics-informed deep learning to alleviate computational challenges and combine measurement data and mathematical models for system reliability assessment.