 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMouseGPT: A Large-scale Vision-Language Model for Mouse Behavior Analysis
Mar 13, 2025Analyzing animal behavior is crucial in advancing neuroscience, yet quantifying and deciphering its intricate dynamics remains a significant challenge. Traditional machine vision approaches, despite their ability to detect spontaneous behaviors, fall short due to limited interpretability and reliance on manual labeling, which restricts the exploration of the full behavioral spectrum. Here, we introduce MouseGPT, a Vision-Language Model (VLM) that integrates visual cues with natural language to revolutionize mouse behavior analysis. Built upon our first-of-its-kind dataset - incorporating pose dynamics and open-vocabulary behavioral annotations across over 42 million frames of diverse psychiatric conditions - MouseGPT provides a novel, context-rich method for comprehensive behavior interpretation. Our holistic analysis framework enables detailed behavior profiling, clustering, and novel behavior discovery, offering deep insights without the need for labor - intensive manual annotation. Evaluations reveal that MouseGPT surpasses existing models in precision, adaptability, and descriptive richness, positioning it as a transformative tool for ethology and for unraveling complex behavioral dynamics in animal models.
Relightable Neural Human Assets from Multi-view Gradient Illuminations
Dec 16, 2022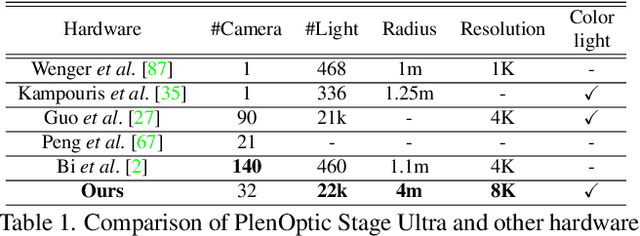


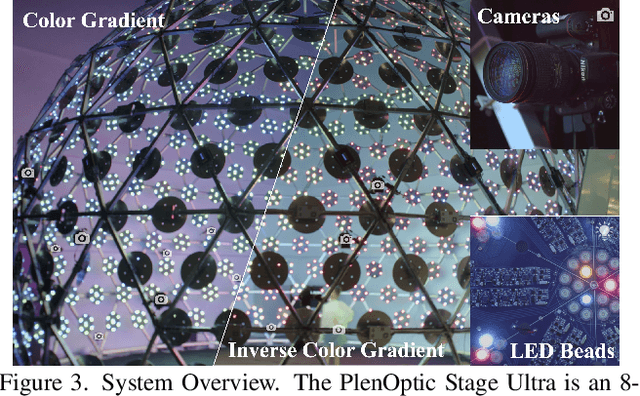
Human modeling and relighting are two fundamental problems in computer vision and graphics, where high-quality datasets can largely facilitate related research. However, most existing human datasets only provide multi-view human images captured under the same illumination. Although valuable for modeling tasks, they are not readily used in relighting problems. To promote research in both fields, in this paper, we present UltraStage, a new 3D human dataset that contains more than 2K high-quality human assets captured under both multi-view and multi-illumination settings. Specifically, for each example, we provide 32 surrounding views illuminated with one white light and two gradient illuminations. In addition to regular multi-view images, gradient illuminations help recover detailed surface normal and spatially-varying material maps, enabling various relighting applications. Inspired by recent advances in neural representation, we further interpret each example into a neural human asset which allows novel view synthesis under arbitrary lighting conditions. We show our neural human assets can achieve extremely high capture performance and are capable of representing fine details such as facial wrinkles and cloth folds. We also validate UltraStage in single image relighting tasks, training neural networks with virtual relighted data from neural assets and demonstrating realistic rendering improvements over prior arts. UltraStage will be publicly available to the community to stimulate significant future developments in various human modeling and rendering tasks.