 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMouseGPT: A Large-scale Vision-Language Model for Mouse Behavior Analysis
Mar 13, 2025Analyzing animal behavior is crucial in advancing neuroscience, yet quantifying and deciphering its intricate dynamics remains a significant challenge. Traditional machine vision approaches, despite their ability to detect spontaneous behaviors, fall short due to limited interpretability and reliance on manual labeling, which restricts the exploration of the full behavioral spectrum. Here, we introduce MouseGPT, a Vision-Language Model (VLM) that integrates visual cues with natural language to revolutionize mouse behavior analysis. Built upon our first-of-its-kind dataset - incorporating pose dynamics and open-vocabulary behavioral annotations across over 42 million frames of diverse psychiatric conditions - MouseGPT provides a novel, context-rich method for comprehensive behavior interpretation. Our holistic analysis framework enables detailed behavior profiling, clustering, and novel behavior discovery, offering deep insights without the need for labor - intensive manual annotation. Evaluations reveal that MouseGPT surpasses existing models in precision, adaptability, and descriptive richness, positioning it as a transformative tool for ethology and for unraveling complex behavioral dynamics in animal models.
IMUSIC: IMU-based Facial Expression Capture
Feb 03, 2024



For facial motion capture and analysis, the dominated solutions are generally based on visual cues, which cannot protect privacy and are vulnerable to occlusions. Inertial measurement units (IMUs) serve as potential rescues yet are mainly adopted for full-body motion capture. In this paper, we propose IMUSIC to fill the gap, a novel path for facial expression capture using purely IMU signals, significantly distant from previous visual solutions.The key design in our IMUSIC is a trilogy. We first design micro-IMUs to suit facial capture, companion with an anatomy-driven IMU placement scheme. Then, we contribute a novel IMU-ARKit dataset, which provides rich paired IMU/visual signals for diverse facial expressions and performances. Such unique multi-modality brings huge potential for future directions like IMU-based facial behavior analysis. Moreover, utilizing IMU-ARKit, we introduce a strong baseline approach to accurately predict facial blendshape parameters from purely IMU signals. Specifically, we tailor a Transformer diffusion model with a two-stage training strategy for this novel tracking task. The IMUSIC framework empowers us to perform accurate facial capture in scenarios where visual methods falter and simultaneously safeguard user privacy. We conduct extensive experiments about both the IMU configuration and technical components to validate the effectiveness of our IMUSIC approach. Notably, IMUSIC enables various potential and novel applications, i.e., privacy-protecting facial capture, hybrid capture against occlusions, or detecting minute facial movements that are often invisible through visual cues. We will release our dataset and implementations to enrich more possibilities of facial capture and analysis in our community.
Improved Langevin Monte Carlo for stochastic optimization via landscape modification
Feb 08, 2023Given a target function $H$ to minimize or a target Gibbs distribution $\pi_{\beta}^0 \propto e^{-\beta H}$ to sample from in the low temperature, in this paper we propose and analyze Langevin Monte Carlo (LMC) algorithms that run on an alternative landscape as specified by $H^f_{\beta,c,1}$ and target a modified Gibbs distribution $\pi^f_{\beta,c,1} \propto e^{-\beta H^f_{\beta,c,1}}$, where the landscape of $H^f_{\beta,c,1}$ is a transformed version of that of $H$ which depends on the parameters $f,\beta$ and $c$. While the original Log-Sobolev constant affiliated with $\pi^0_{\beta}$ exhibits exponential dependence on both $\beta$ and the energy barrier $M$ in the low temperature regime, with appropriate tuning of these parameters and subject to assumptions on $H$, we prove that the energy barrier of the transformed landscape is reduced which consequently leads to polynomial dependence on both $\beta$ and $M$ in the modified Log-Sobolev constant associated with $\pi^f_{\beta,c,1}$. This yield improved total variation mixing time bounds and improved convergence toward a global minimum of $H$. We stress that the technique developed in this paper is not only limited to LMC and is broadly applicable to other gradient-based optimization or sampling algorithms.
NARRATE: A Normal Assisted Free-View Portrait Stylizer
Jul 03, 2022
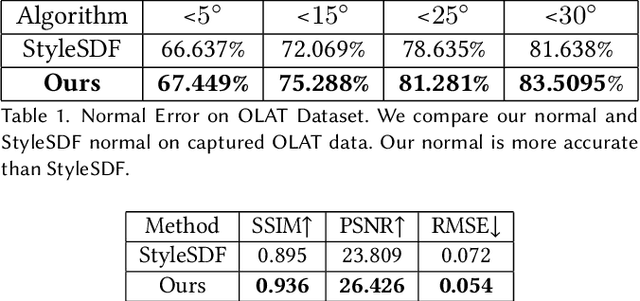
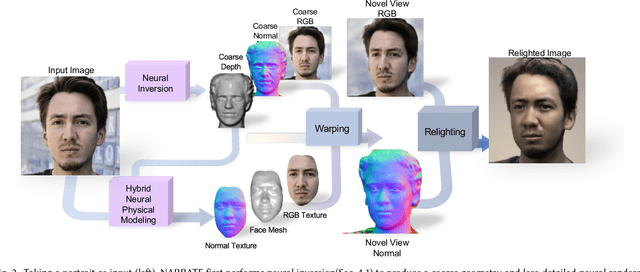
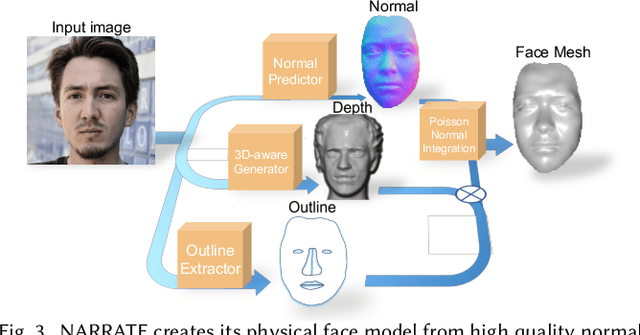
In this work, we propose NARRATE, a novel pipeline that enables simultaneously editing portrait lighting and perspective in a photorealistic manner. As a hybrid neural-physical face model, NARRATE leverages complementary benefits of geometry-aware generative approaches and normal-assisted physical face models. In a nutshell, NARRATE first inverts the input portrait to a coarse geometry and employs neural rendering to generate images resembling the input, as well as producing convincing pose changes. However, inversion step introduces mismatch, bringing low-quality images with less facial details. As such, we further estimate portrait normal to enhance the coarse geometry, creating a high-fidelity physical face model. In particular, we fuse the neural and physical renderings to compensate for the imperfect inversion, resulting in both realistic and view-consistent novel perspective images. In relighting stage, previous works focus on single view portrait relighting but ignoring consistency between different perspectives as well, leading unstable and inconsistent lighting effects for view changes. We extend Total Relighting to fix this problem by unifying its multi-view input normal maps with the physical face model. NARRATE conducts relighting with consistent normal maps, imposing cross-view constraints and exhibiting stable and coherent illumination effects. We experimentally demonstrate that NARRATE achieves more photorealistic, reliable results over prior works. We further bridge NARRATE with animation and style transfer tools, supporting pose change, light change, facial animation, and style transfer, either separately or in combination, all at a photographic quality. We showcase vivid free-view facial animations as well as 3D-aware relightable stylization, which help facilitate various AR/VR applications like virtual cinematography, 3D video conferencing, and post-production.
Relightable Neural Video Portrait
Jul 30, 2021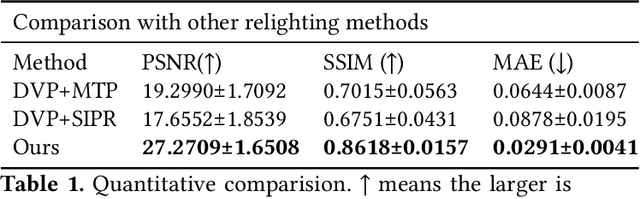
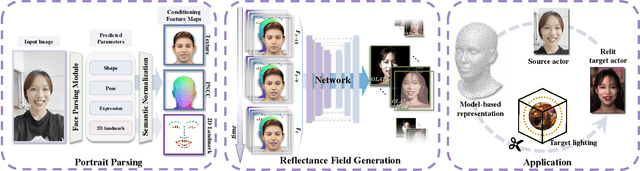

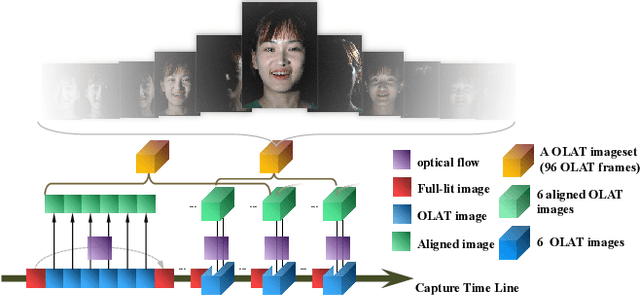
Photo-realistic facial video portrait reenactment benefits virtual production and numerous VR/AR experiences. The task remains challenging as the portrait should maintain high realism and consistency with the target environment. In this paper, we present a relightable neural video portrait, a simultaneous relighting and reenactment scheme that transfers the head pose and facial expressions from a source actor to a portrait video of a target actor with arbitrary new backgrounds and lighting conditions. Our approach combines 4D reflectance field learning, model-based facial performance capture and target-aware neural rendering. Specifically, we adopt a rendering-to-video translation network to first synthesize high-quality OLAT imagesets and alpha mattes from hybrid facial performance capture results. We then design a semantic-aware facial normalization scheme to enable reliable explicit control as well as a multi-frame multi-task learning strategy to encode content, segmentation and temporal information simultaneously for high-quality reflectance field inference. After training, our approach further enables photo-realistic and controllable video portrait editing of the target performer. Reliable face poses and expression editing is obtained by applying the same hybrid facial capture and normalization scheme to the source video input, while our explicit alpha and OLAT output enable high-quality relit and background editing. With the ability to achieve simultaneous relighting and reenactment, we are able to improve the realism in a variety of virtual production and video rewrite applications.