 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNARRATE: A Normal Assisted Free-View Portrait Stylizer
Jul 03, 2022
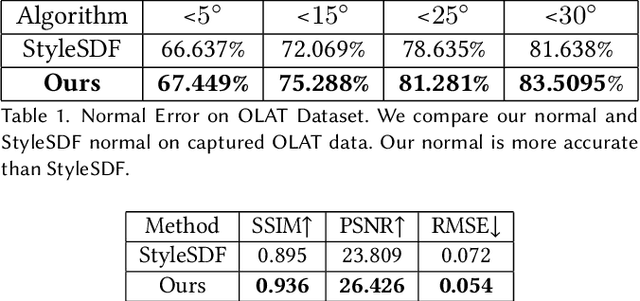
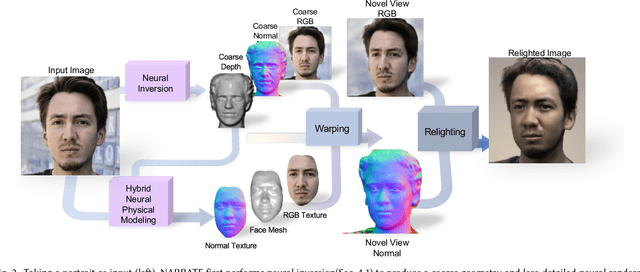
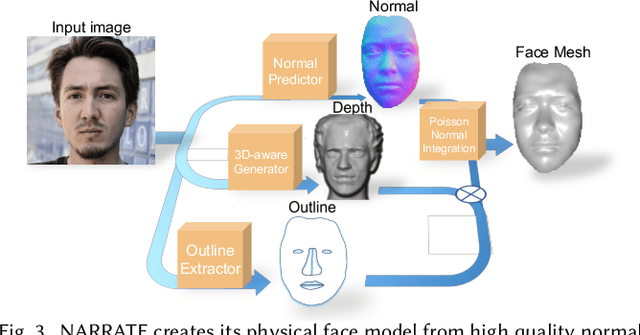
In this work, we propose NARRATE, a novel pipeline that enables simultaneously editing portrait lighting and perspective in a photorealistic manner. As a hybrid neural-physical face model, NARRATE leverages complementary benefits of geometry-aware generative approaches and normal-assisted physical face models. In a nutshell, NARRATE first inverts the input portrait to a coarse geometry and employs neural rendering to generate images resembling the input, as well as producing convincing pose changes. However, inversion step introduces mismatch, bringing low-quality images with less facial details. As such, we further estimate portrait normal to enhance the coarse geometry, creating a high-fidelity physical face model. In particular, we fuse the neural and physical renderings to compensate for the imperfect inversion, resulting in both realistic and view-consistent novel perspective images. In relighting stage, previous works focus on single view portrait relighting but ignoring consistency between different perspectives as well, leading unstable and inconsistent lighting effects for view changes. We extend Total Relighting to fix this problem by unifying its multi-view input normal maps with the physical face model. NARRATE conducts relighting with consistent normal maps, imposing cross-view constraints and exhibiting stable and coherent illumination effects. We experimentally demonstrate that NARRATE achieves more photorealistic, reliable results over prior works. We further bridge NARRATE with animation and style transfer tools, supporting pose change, light change, facial animation, and style transfer, either separately or in combination, all at a photographic quality. We showcase vivid free-view facial animations as well as 3D-aware relightable stylization, which help facilitate various AR/VR applications like virtual cinematography, 3D video conferencing, and post-production.
NeuVV: Neural Volumetric Videos with Immersive Rendering and Editing
Feb 12, 2022



Some of the most exciting experiences that Metaverse promises to offer, for instance, live interactions with virtual characters in virtual environments, require real-time photo-realistic rendering. 3D reconstruction approaches to rendering, active or passive, still require extensive cleanup work to fix the meshes or point clouds. In this paper, we present a neural volumography technique called neural volumetric video or NeuVV to support immersive, interactive, and spatial-temporal rendering of volumetric video contents with photo-realism and in real-time. The core of NeuVV is to efficiently encode a dynamic neural radiance field (NeRF) into renderable and editable primitives. We introduce two types of factorization schemes: a hyper-spherical harmonics (HH) decomposition for modeling smooth color variations over space and time and a learnable basis representation for modeling abrupt density and color changes caused by motion. NeuVV factorization can be integrated into a Video Octree (VOctree) analogous to PlenOctree to significantly accelerate training while reducing memory overhead. Real-time NeuVV rendering further enables a class of immersive content editing tools. Specifically, NeuVV treats each VOctree as a primitive and implements volume-based depth ordering and alpha blending to realize spatial-temporal compositions for content re-purposing. For example, we demonstrate positioning varied manifestations of the same performance at different 3D locations with different timing, adjusting color/texture of the performer's clothing, casting spotlight shadows and synthesizing distance falloff lighting, etc, all at an interactive speed. We further develop a hybrid neural-rasterization rendering framework to support consumer-level VR headsets so that the aforementioned volumetric video viewing and editing, for the first time, can be conducted immersively in virtual 3D space.
Relightable Neural Video Portrait
Jul 30, 2021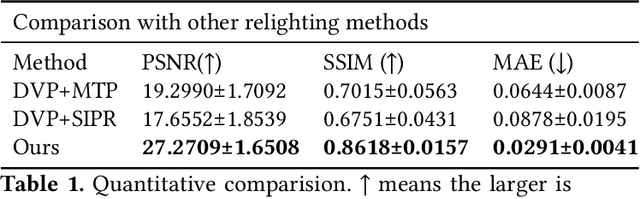
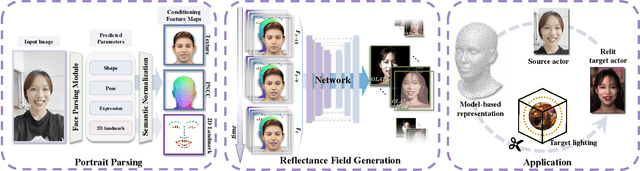

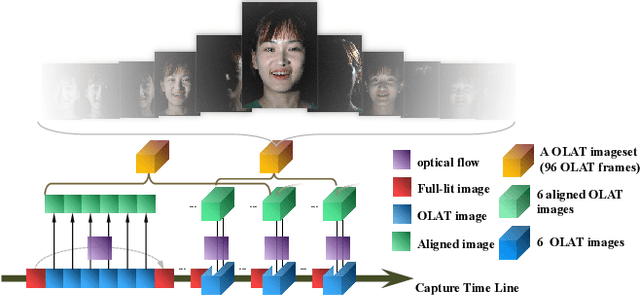
Photo-realistic facial video portrait reenactment benefits virtual production and numerous VR/AR experiences. The task remains challenging as the portrait should maintain high realism and consistency with the target environment. In this paper, we present a relightable neural video portrait, a simultaneous relighting and reenactment scheme that transfers the head pose and facial expressions from a source actor to a portrait video of a target actor with arbitrary new backgrounds and lighting conditions. Our approach combines 4D reflectance field learning, model-based facial performance capture and target-aware neural rendering. Specifically, we adopt a rendering-to-video translation network to first synthesize high-quality OLAT imagesets and alpha mattes from hybrid facial performance capture results. We then design a semantic-aware facial normalization scheme to enable reliable explicit control as well as a multi-frame multi-task learning strategy to encode content, segmentation and temporal information simultaneously for high-quality reflectance field inference. After training, our approach further enables photo-realistic and controllable video portrait editing of the target performer. Reliable face poses and expression editing is obtained by applying the same hybrid facial capture and normalization scheme to the source video input, while our explicit alpha and OLAT output enable high-quality relit and background editing. With the ability to achieve simultaneous relighting and reenactment, we are able to improve the realism in a variety of virtual production and video rewrite applications.