 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixRI: Mixing Features of Reference Images for Novel Object Pose Estimation
Jan 11, 2026We present MixRI, a lightweight network that solves the CAD-based novel object pose estimation problem in RGB images. It can be instantly applied to a novel object at test time without finetuning. We design our network to meet the demands of real-world applications, emphasizing reduced memory requirements and fast inference time. Unlike existing works that utilize many reference images and have large network parameters, we directly match points based on the multi-view information between the query and reference images with a lightweight network. Thanks to our reference image fusion strategy, we significantly decrease the number of reference images, thus decreasing the time needed to process these images and the memory required to store them. Furthermore, with our lightweight network, our method requires less inference time. Though with fewer reference images, experiments on seven core datasets in the BOP challenge show that our method achieves comparable results with other methods that require more reference images and larger network parameters.
* Accepted by ICCV 2025
SpatialTree: How Spatial Abilities Branch Out in MLLMs
Dec 23, 2025Cognitive science suggests that spatial ability develops progressively-from perception to reasoning and interaction. Yet in multimodal LLMs (MLLMs), this hierarchy remains poorly understood, as most studies focus on a narrow set of tasks. We introduce SpatialTree, a cognitive-science-inspired hierarchy that organizes spatial abilities into four levels: low-level perception (L1), mental mapping (L2), simulation (L3), and agentic competence (L4). Based on this taxonomy, we construct the first capability-centric hierarchical benchmark, thoroughly evaluating mainstream MLLMs across 27 sub-abilities. The evaluation results reveal a clear structure: L1 skills are largely orthogonal, whereas higher-level skills are strongly correlated, indicating increasing interdependency. Through targeted supervised fine-tuning, we uncover a surprising transfer dynamic-negative transfer within L1, but strong cross-level transfer from low- to high-level abilities with notable synergy. Finally, we explore how to improve the entire hierarchy. We find that naive RL that encourages extensive "thinking" is unreliable: it helps complex reasoning but hurts intuitive perception. We propose a simple auto-think strategy that suppresses unnecessary deliberation, enabling RL to consistently improve performance across all levels. By building SpatialTree, we provide a proof-of-concept framework for understanding and systematically scaling spatial abilities in MLLMs.
Martian World Models: Controllable Video Synthesis with Physically Accurate 3D Reconstructions
Jul 10, 2025



Synthesizing realistic Martian landscape videos is crucial for mission rehearsal and robotic simulation. However, this task poses unique challenges due to the scarcity of high-quality Martian data and the significant domain gap between Martian and terrestrial imagery. To address these challenges, we propose a holistic solution composed of two key components: 1) A data curation pipeline Multimodal Mars Synthesis (M3arsSynth), which reconstructs 3D Martian environments from real stereo navigation images, sourced from NASA's Planetary Data System (PDS), and renders high-fidelity multiview 3D video sequences. 2) A Martian terrain video generator, MarsGen, which synthesizes novel videos visually realistic and geometrically consistent with the 3D structure encoded in the data. Our M3arsSynth engine spans a wide range of Martian terrains and acquisition dates, enabling the generation of physically accurate 3D surface models at metric-scale resolution. MarsGen, fine-tuned on M3arsSynth data, synthesizes videos conditioned on an initial image frame and, optionally, camera trajectories or textual prompts, allowing for video generation in novel environments. Experimental results show that our approach outperforms video synthesis models trained on terrestrial datasets, achieving superior visual fidelity and 3D structural consistency.
CryoFastAR: Fast Cryo-EM Ab Initio Reconstruction Made Easy
Jun 06, 2025Pose estimation from unordered images is fundamental for 3D reconstruction, robotics, and scientific imaging. Recent geometric foundation models, such as DUSt3R, enable end-to-end dense 3D reconstruction but remain underexplored in scientific imaging fields like cryo-electron microscopy (cryo-EM) for near-atomic protein reconstruction. In cryo-EM, pose estimation and 3D reconstruction from unordered particle images still depend on time-consuming iterative optimization, primarily due to challenges such as low signal-to-noise ratios (SNR) and distortions from the contrast transfer function (CTF). We introduce CryoFastAR, the first geometric foundation model that can directly predict poses from Cryo-EM noisy images for Fast ab initio Reconstruction. By integrating multi-view features and training on large-scale simulated cryo-EM data with realistic noise and CTF modulations, CryoFastAR enhances pose estimation accuracy and generalization. To enhance training stability, we propose a progressive training strategy that first allows the model to extract essential features under simpler conditions before gradually increasing difficulty to improve robustness. Experiments show that CryoFastAR achieves comparable quality while significantly accelerating inference over traditional iterative approaches on both synthetic and real datasets.
SmartAvatar: Text- and Image-Guided Human Avatar Generation with VLM AI Agents
Jun 05, 2025



SmartAvatar is a vision-language-agent-driven framework for generating fully rigged, animation-ready 3D human avatars from a single photo or textual prompt. While diffusion-based methods have made progress in general 3D object generation, they continue to struggle with precise control over human identity, body shape, and animation readiness. In contrast, SmartAvatar leverages the commonsense reasoning capabilities of large vision-language models (VLMs) in combination with off-the-shelf parametric human generators to deliver high-quality, customizable avatars. A key innovation is an autonomous verification loop, where the agent renders draft avatars, evaluates facial similarity, anatomical plausibility, and prompt alignment, and iteratively adjusts generation parameters for convergence. This interactive, AI-guided refinement process promotes fine-grained control over both facial and body features, enabling users to iteratively refine their avatars via natural-language conversations. Unlike diffusion models that rely on static pre-trained datasets and offer limited flexibility, SmartAvatar brings users into the modeling loop and ensures continuous improvement through an LLM-driven procedural generation and verification system. The generated avatars are fully rigged and support pose manipulation with consistent identity and appearance, making them suitable for downstream animation and interactive applications. Quantitative benchmarks and user studies demonstrate that SmartAvatar outperforms recent text- and image-driven avatar generation systems in terms of reconstructed mesh quality, identity fidelity, attribute accuracy, and animation readiness, making it a versatile tool for realistic, customizable avatar creation on consumer-grade hardware.
Agentic 3D Scene Generation with Spatially Contextualized VLMs
May 26, 2025Despite recent advances in multimodal content generation enabled by vision-language models (VLMs), their ability to reason about and generate structured 3D scenes remains largely underexplored. This limitation constrains their utility in spatially grounded tasks such as embodied AI, immersive simulations, and interactive 3D applications. We introduce a new paradigm that enables VLMs to generate, understand, and edit complex 3D environments by injecting a continually evolving spatial context. Constructed from multimodal input, this context consists of three components: a scene portrait that provides a high-level semantic blueprint, a semantically labeled point cloud capturing object-level geometry, and a scene hypergraph that encodes rich spatial relationships, including unary, binary, and higher-order constraints. Together, these components provide the VLM with a structured, geometry-aware working memory that integrates its inherent multimodal reasoning capabilities with structured 3D understanding for effective spatial reasoning. Building on this foundation, we develop an agentic 3D scene generation pipeline in which the VLM iteratively reads from and updates the spatial context. The pipeline features high-quality asset generation with geometric restoration, environment setup with automatic verification, and ergonomic adjustment guided by the scene hypergraph. Experiments show that our framework can handle diverse and challenging inputs, achieving a level of generalization not observed in prior work. Further results demonstrate that injecting spatial context enables VLMs to perform downstream tasks such as interactive scene editing and path planning, suggesting strong potential for spatially intelligent systems in computer graphics, 3D vision, and embodied applications.
Multimodal Generation of Animatable 3D Human Models with AvatarForge
Mar 11, 2025We introduce AvatarForge, a framework for generating animatable 3D human avatars from text or image inputs using AI-driven procedural generation. While diffusion-based methods have made strides in general 3D object generation, they struggle with high-quality, customizable human avatars due to the complexity and diversity of human body shapes, poses, exacerbated by the scarcity of high-quality data. Additionally, animating these avatars remains a significant challenge for existing methods. AvatarForge overcomes these limitations by combining LLM-based commonsense reasoning with off-the-shelf 3D human generators, enabling fine-grained control over body and facial details. Unlike diffusion models which often rely on pre-trained datasets lacking precise control over individual human features, AvatarForge offers a more flexible approach, bringing humans into the iterative design and modeling loop, with its auto-verification system allowing for continuous refinement of the generated avatars, and thus promoting high accuracy and customization. Our evaluations show that AvatarForge outperforms state-of-the-art methods in both text- and image-to-avatar generation, making it a versatile tool for artistic creation and animation.
WorldCraft: Photo-Realistic 3D World Creation and Customization via LLM Agents
Feb 21, 2025Constructing photorealistic virtual worlds has applications across various fields, but it often requires the extensive labor of highly trained professionals to operate conventional 3D modeling software. To democratize this process, we introduce WorldCraft, a system where large language model (LLM) agents leverage procedural generation to create indoor and outdoor scenes populated with objects, allowing users to control individual object attributes and the scene layout using intuitive natural language commands. In our framework, a coordinator agent manages the overall process and works with two specialized LLM agents to complete the scene creation: ForgeIt, which integrates an ever-growing manual through auto-verification to enable precise customization of individual objects, and ArrangeIt, which formulates hierarchical optimization problems to achieve a layout that balances ergonomic and aesthetic considerations. Additionally, our pipeline incorporates a trajectory control agent, allowing users to animate the scene and operate the camera through natural language interactions. Our system is also compatible with off-the-shelf deep 3D generators to enrich scene assets. Through evaluations and comparisons with state-of-the-art methods, we demonstrate the versatility of WorldCraft, ranging from single-object customization to intricate, large-scale interior and exterior scene designs. This system empowers non-professionals to bring their creative visions to life.
ChatCam: Empowering Camera Control through Conversational AI
Sep 25, 2024Cinematographers adeptly capture the essence of the world, crafting compelling visual narratives through intricate camera movements. Witnessing the strides made by large language models in perceiving and interacting with the 3D world, this study explores their capability to control cameras with human language guidance. We introduce ChatCam, a system that navigates camera movements through conversations with users, mimicking a professional cinematographer's workflow. To achieve this, we propose CineGPT, a GPT-based autoregressive model for text-conditioned camera trajectory generation. We also develop an Anchor Determinator to ensure precise camera trajectory placement. ChatCam understands user requests and employs our proposed tools to generate trajectories, which can be used to render high-quality video footage on radiance field representations. Our experiments, including comparisons to state-of-the-art approaches and user studies, demonstrate our approach's ability to interpret and execute complex instructions for camera operation, showing promising applications in real-world production settings.
Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-aware Spatio-Temporal Sampling
Jun 06, 2024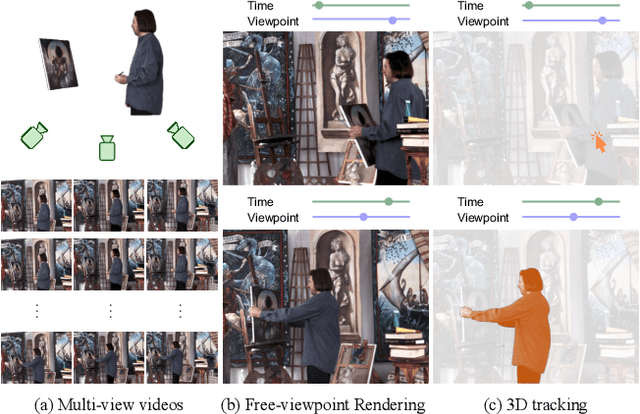
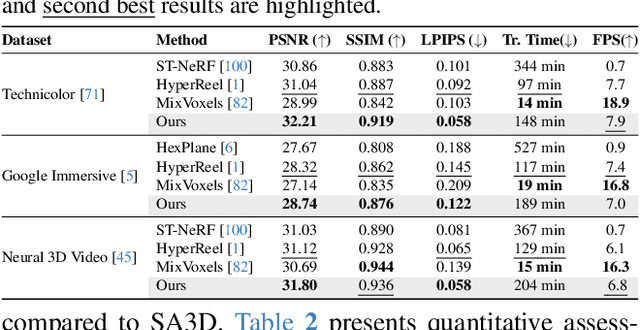
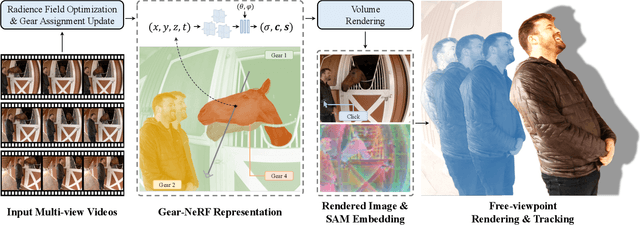
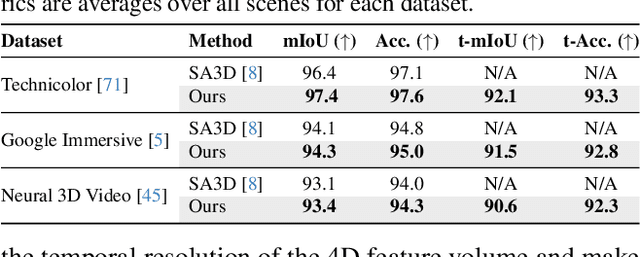
Extensions of Neural Radiance Fields (NeRFs) to model dynamic scenes have enabled their near photo-realistic, free-viewpoint rendering. Although these methods have shown some potential in creating immersive experiences, two drawbacks limit their ubiquity: (i) a significant reduction in reconstruction quality when the computing budget is limited, and (ii) a lack of semantic understanding of the underlying scenes. To address these issues, we introduce Gear-NeRF, which leverages semantic information from powerful image segmentation models. Our approach presents a principled way for learning a spatio-temporal (4D) semantic embedding, based on which we introduce the concept of gears to allow for stratified modeling of dynamic regions of the scene based on the extent of their motion. Such differentiation allows us to adjust the spatio-temporal sampling resolution for each region in proportion to its motion scale, achieving more photo-realistic dynamic novel view synthesis. At the same time, almost for free, our approach enables free-viewpoint tracking of objects of interest - a functionality not yet achieved by existing NeRF-based methods. Empirical studies validate the effectiveness of our method, where we achieve state-of-the-art rendering and tracking performance on multiple challenging datasets.