 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCryoFastAR: Fast Cryo-EM Ab Initio Reconstruction Made Easy
Jun 06, 2025Pose estimation from unordered images is fundamental for 3D reconstruction, robotics, and scientific imaging. Recent geometric foundation models, such as DUSt3R, enable end-to-end dense 3D reconstruction but remain underexplored in scientific imaging fields like cryo-electron microscopy (cryo-EM) for near-atomic protein reconstruction. In cryo-EM, pose estimation and 3D reconstruction from unordered particle images still depend on time-consuming iterative optimization, primarily due to challenges such as low signal-to-noise ratios (SNR) and distortions from the contrast transfer function (CTF). We introduce CryoFastAR, the first geometric foundation model that can directly predict poses from Cryo-EM noisy images for Fast ab initio Reconstruction. By integrating multi-view features and training on large-scale simulated cryo-EM data with realistic noise and CTF modulations, CryoFastAR enhances pose estimation accuracy and generalization. To enhance training stability, we propose a progressive training strategy that first allows the model to extract essential features under simpler conditions before gradually increasing difficulty to improve robustness. Experiments show that CryoFastAR achieves comparable quality while significantly accelerating inference over traditional iterative approaches on both synthetic and real datasets.
DRACO: A Denoising-Reconstruction Autoencoder for Cryo-EM
Oct 15, 2024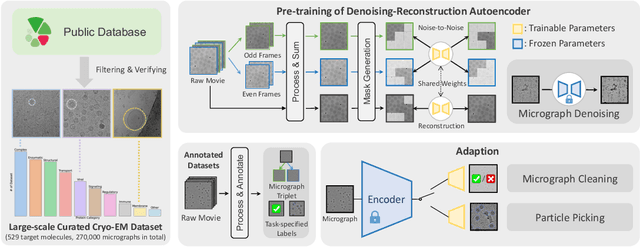
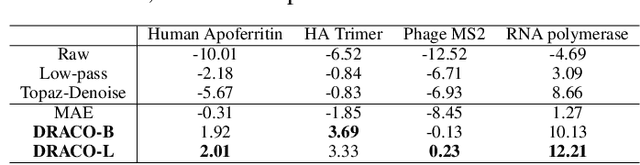
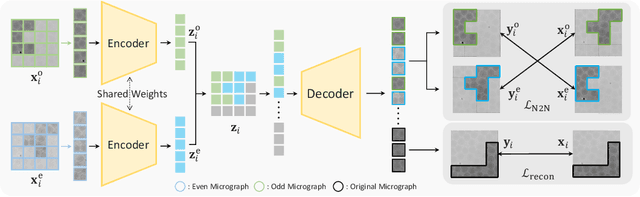

Foundation models in computer vision have demonstrated exceptional performance in zero-shot and few-shot tasks by extracting multi-purpose features from large-scale datasets through self-supervised pre-training methods. However, these models often overlook the severe corruption in cryogenic electron microscopy (cryo-EM) images by high-level noises. We introduce DRACO, a Denoising-Reconstruction Autoencoder for CryO-EM, inspired by the Noise2Noise (N2N) approach. By processing cryo-EM movies into odd and even images and treating them as independent noisy observations, we apply a denoising-reconstruction hybrid training scheme. We mask both images to create denoising and reconstruction tasks. For DRACO's pre-training, the quality of the dataset is essential, we hence build a high-quality, diverse dataset from an uncurated public database, including over 270,000 movies or micrographs. After pre-training, DRACO naturally serves as a generalizable cryo-EM image denoiser and a foundation model for various cryo-EM downstream tasks. DRACO demonstrates the best performance in denoising, micrograph curation, and particle picking tasks compared to state-of-the-art baselines. We will release the code, pre-trained models, and the curated dataset to stimulate further research.
Breaking MLPerf Training: A Case Study on Optimizing BERT
Feb 04, 2024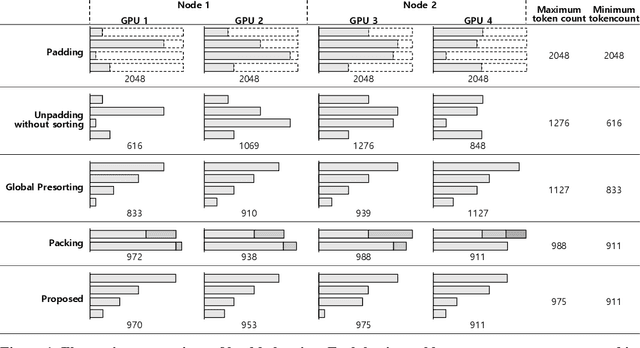
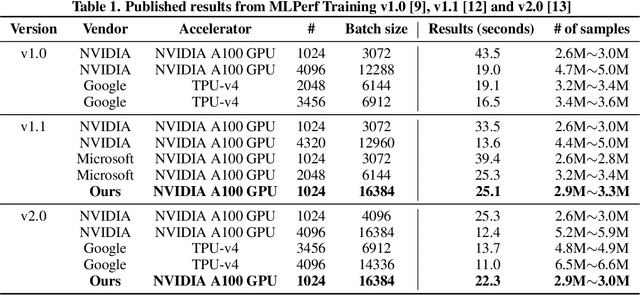
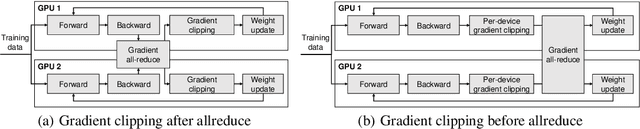
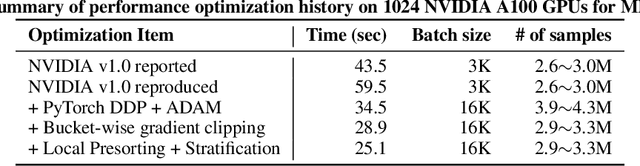
Speeding up the large-scale distributed training is challenging in that it requires improving various components of training including load balancing, communication, optimizers, etc. We present novel approaches for fast large-scale training of BERT model which individually ameliorates each component thereby leading to a new level of BERT training performance. Load balancing is imperative in distributed BERT training since its training datasets are characterized by samples with various lengths. Communication cost, which is proportional to the scale of distributed training, needs to be hidden by useful computation. In addition, the optimizers, e.g., ADAM, LAMB, etc., need to be carefully re-evaluated in the context of large-scale distributed training. We propose two new ideas, (1) local presorting based on dataset stratification for load balancing and (2) bucket-wise gradient clipping before allreduce which allows us to benefit from the overlap of gradient computation and synchronization as well as the fast training of gradient clipping before allreduce. We also re-evaluate existing optimizers via hyperparameter optimization and utilize ADAM, which also contributes to fast training via larger batches than existing methods. Our proposed methods, all combined, give the fastest MLPerf BERT training of 25.1 (22.3) seconds on 1,024 NVIDIA A100 GPUs, which is 1.33x (1.13x) and 1.57x faster than the other top two (one) submissions to MLPerf v1.1 (v2.0). Our implementation and evaluation results are available at MLPerf v1.1~v2.1.