 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Large Language Models with Human Expertise for Disease Detection in Electronic Health Records
Mar 31, 2025Objective: Electronic health records (EHR) are widely available to complement administrative data-based disease surveillance and healthcare performance evaluation. Defining conditions from EHR is labour-intensive and requires extensive manual labelling of disease outcomes. This study developed an efficient strategy based on advanced large language models to identify multiple conditions from EHR clinical notes. Methods: We linked a cardiac registry cohort in 2015 with an EHR system in Alberta, Canada. We developed a pipeline that leveraged a generative large language model (LLM) to analyze, understand, and interpret EHR notes by prompts based on specific diagnosis, treatment management, and clinical guidelines. The pipeline was applied to detect acute myocardial infarction (AMI), diabetes, and hypertension. The performance was compared against clinician-validated diagnoses as the reference standard and widely adopted International Classification of Diseases (ICD) codes-based methods. Results: The study cohort accounted for 3,088 patients and 551,095 clinical notes. The prevalence was 55.4%, 27.7%, 65.9% and for AMI, diabetes, and hypertension, respectively. The performance of the LLM-based pipeline for detecting conditions varied: AMI had 88% sensitivity, 63% specificity, and 77% positive predictive value (PPV); diabetes had 91% sensitivity, 86% specificity, and 71% PPV; and hypertension had 94% sensitivity, 32% specificity, and 72% PPV. Compared with ICD codes, the LLM-based method demonstrated improved sensitivity and negative predictive value across all conditions. The monthly percentage trends from the detected cases by LLM and reference standard showed consistent patterns.
Learning Service Selection Decision Making Behaviors During Scientific Workflow Development
Mar 30, 2024



Increasingly, more software services have been published onto the Internet, making it a big challenge to recommend services in the process of a scientific workflow composition. In this paper, a novel context-aware approach is proposed to recommending next services in a workflow development process, through learning service representation and service selection decision making behaviors from workflow provenance. Inspired by natural language sentence generation, the composition process of a scientific workflow is formalized as a step-wise procedure within the context of the goal of workflow, and the problem of next service recommendation is mapped to next word prediction. Historical service dependencies are first extracted from scientific workflow provenance to build a knowledge graph. Service sequences are then generated based on diverse composition path generation strategies. Afterwards, the generated corpus of composition paths are leveraged to study previous decision making strategies. Such a trained goal-oriented next service prediction model will be used to recommend top K candidate services during workflow composition process. Extensive experiments on a real-word repository have demonstrated the effectiveness of this approach.
Breaking MLPerf Training: A Case Study on Optimizing BERT
Feb 04, 2024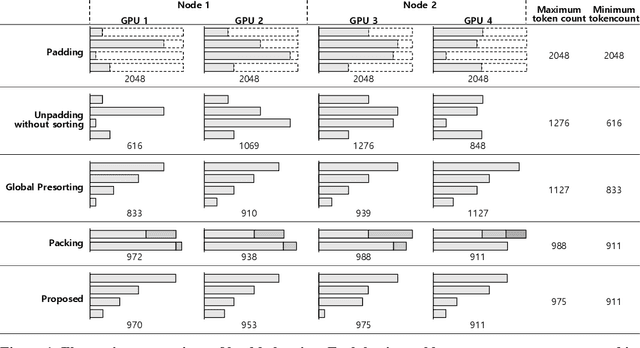
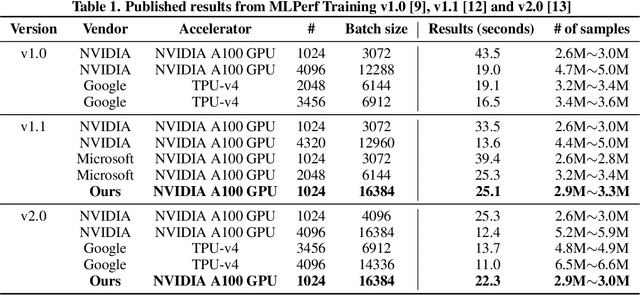
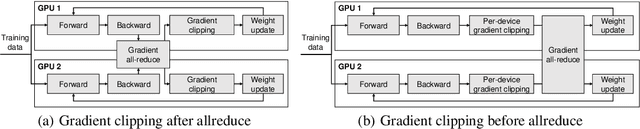
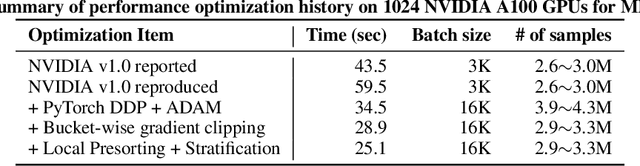
Speeding up the large-scale distributed training is challenging in that it requires improving various components of training including load balancing, communication, optimizers, etc. We present novel approaches for fast large-scale training of BERT model which individually ameliorates each component thereby leading to a new level of BERT training performance. Load balancing is imperative in distributed BERT training since its training datasets are characterized by samples with various lengths. Communication cost, which is proportional to the scale of distributed training, needs to be hidden by useful computation. In addition, the optimizers, e.g., ADAM, LAMB, etc., need to be carefully re-evaluated in the context of large-scale distributed training. We propose two new ideas, (1) local presorting based on dataset stratification for load balancing and (2) bucket-wise gradient clipping before allreduce which allows us to benefit from the overlap of gradient computation and synchronization as well as the fast training of gradient clipping before allreduce. We also re-evaluate existing optimizers via hyperparameter optimization and utilize ADAM, which also contributes to fast training via larger batches than existing methods. Our proposed methods, all combined, give the fastest MLPerf BERT training of 25.1 (22.3) seconds on 1,024 NVIDIA A100 GPUs, which is 1.33x (1.13x) and 1.57x faster than the other top two (one) submissions to MLPerf v1.1 (v2.0). Our implementation and evaluation results are available at MLPerf v1.1~v2.1.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023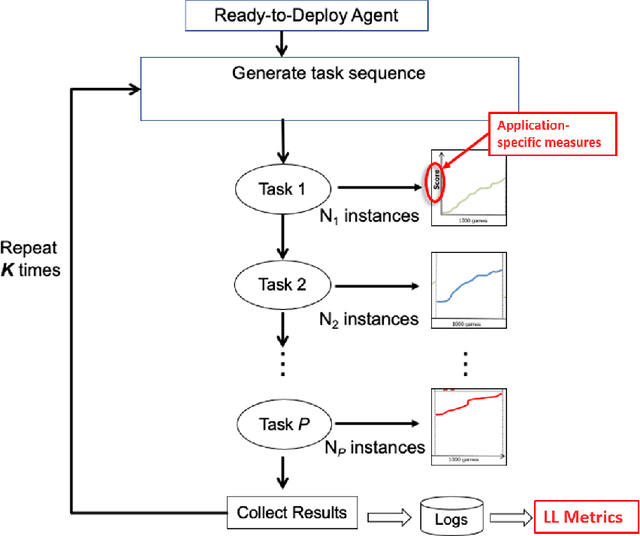


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Goal-Driven Context-Aware Next Service Recommendation for Mashup Composition
Oct 25, 2022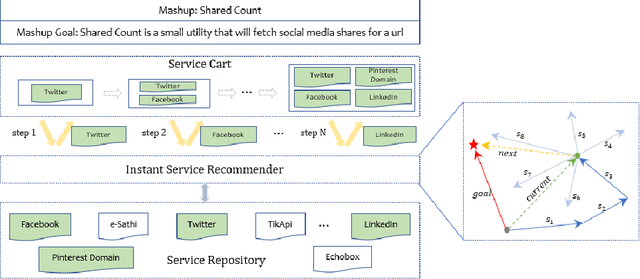

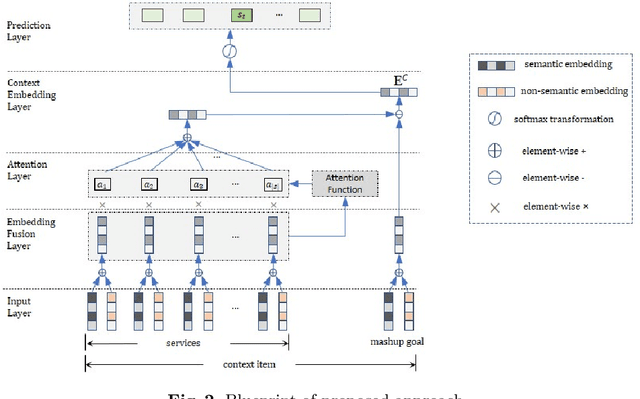
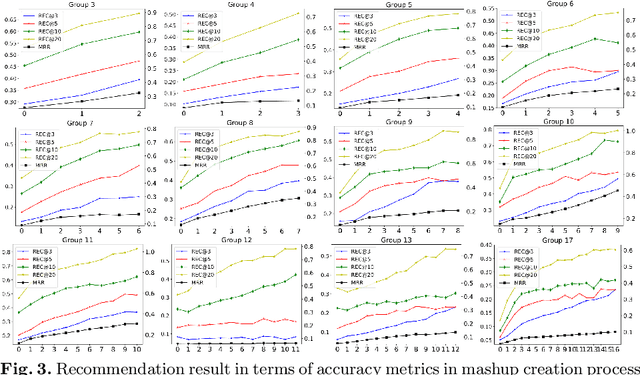
As service-oriented architecture becoming one of the most prevalent techniques to rapidly deliver functionalities to customers, increasingly more reusable software components have been published online in forms of web services. To create a mashup, it gets not only time-consuming but also error-prone for developers to find suitable services from such a sea of services. Service discovery and recommendation has thus attracted significant momentum in both academia and industry. This paper proposes a novel incremental recommend-as-you-go approach to recommending next potential service based on the context of a mashup under construction, considering services that have been selected to the current step as well as its mashup goal. The core technique is an algorithm of learning the embedding of services, which learns their past goal-driven context-aware decision making behaviors in addition to their semantic descriptions and co-occurrence history. A goal exclusionary negative sampling mechanism tailored for mashup development is also developed to improve training performance. Extensive experiments on a real-world dataset demonstrate the effectiveness of our approach.
Learning Context-Aware Service Representation for Service Recommendation in Workflow Composition
May 24, 2022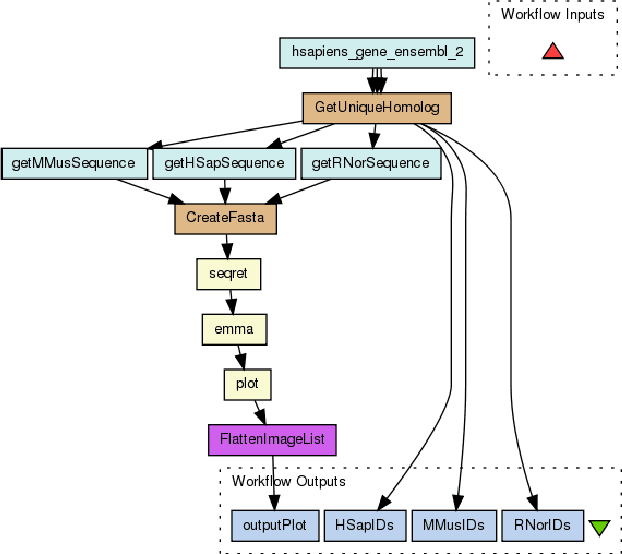
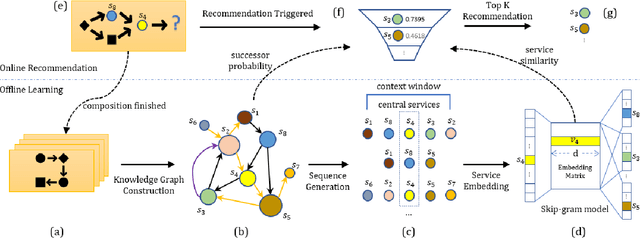
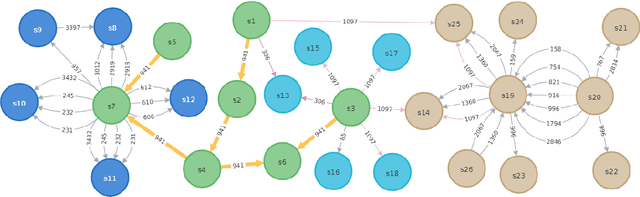
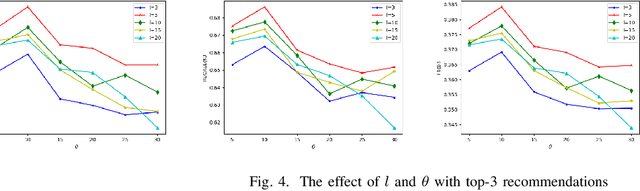
As increasingly more software services have been published onto the Internet, it remains a significant challenge to recommend suitable services to facilitate scientific workflow composition. This paper proposes a novel NLP-inspired approach to recommending services throughout a workflow development process, based on incrementally learning latent service representation from workflow provenance. A workflow composition process is formalized as a step-wise, context-aware service generation procedure, which is mapped to next-word prediction in a natural language sentence. Historical service dependencies are extracted from workflow provenance to build and enrich a knowledge graph. Each path in the knowledge graph reflects a scenario in a data analytics experiment, which is analogous to a sentence in a conversation. All paths are thus formalized as composable service sequences and are mined, using various patterns, from the established knowledge graph to construct a corpus. Service embeddings are then learned by applying deep learning model from the NLP field. Extensive experiments on the real-world dataset demonstrate the effectiveness and efficiency of the approach.
Data-free mixed-precision quantization using novel sensitivity metric
Mar 18, 2021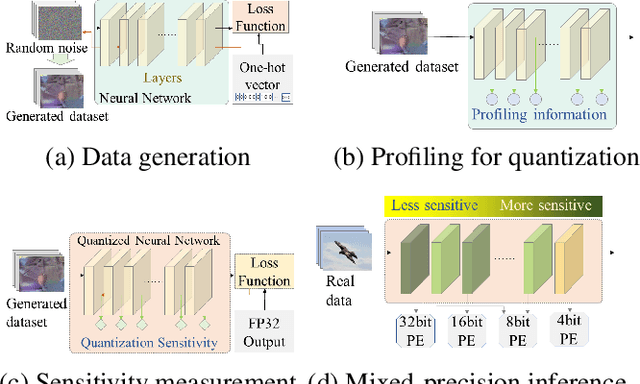
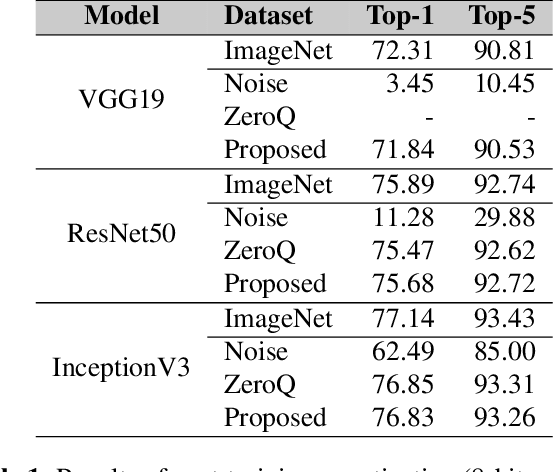
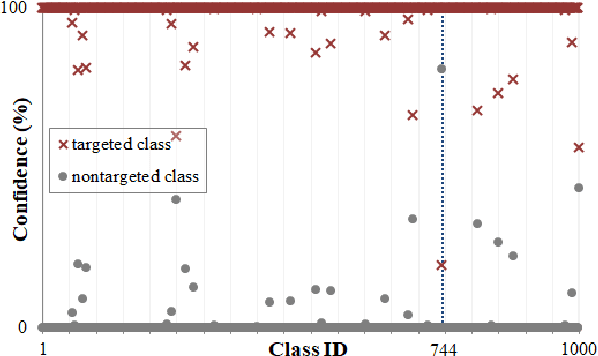
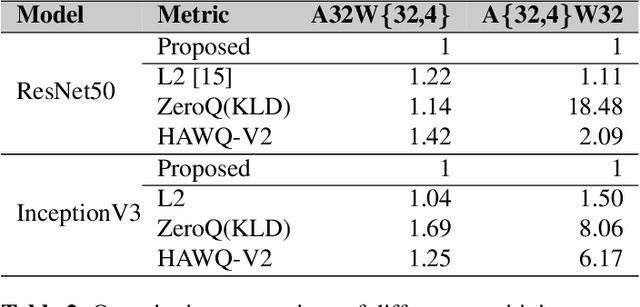
Post-training quantization is a representative technique for compressing neural networks, making them smaller and more efficient for deployment on edge devices. However, an inaccessible user dataset often makes it difficult to ensure the quality of the quantized neural network in practice. In addition, existing approaches may use a single uniform bit-width across the network, resulting in significant accuracy degradation at extremely low bit-widths. To utilize multiple bit-width, sensitivity metric plays a key role in balancing accuracy and compression. In this paper, we propose a novel sensitivity metric that considers the effect of quantization error on task loss and interaction with other layers. Moreover, we develop labeled data generation methods that are not dependent on a specific operation of the neural network. Our experiments show that the proposed metric better represents quantization sensitivity, and generated data are more feasible to be applied to mixed-precision quantization.
Revisiting Classical Bagging with Modern Transfer Learning for On-the-fly Disaster Damage Detector
Oct 04, 2019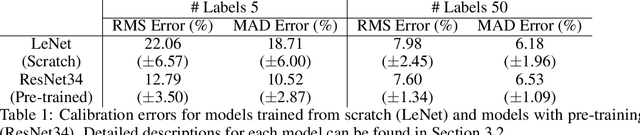
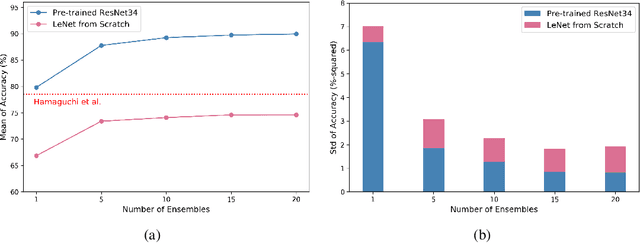
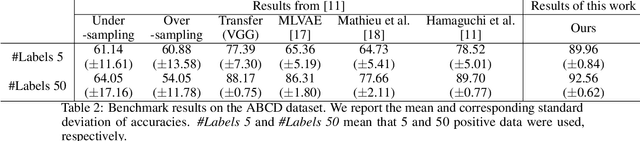
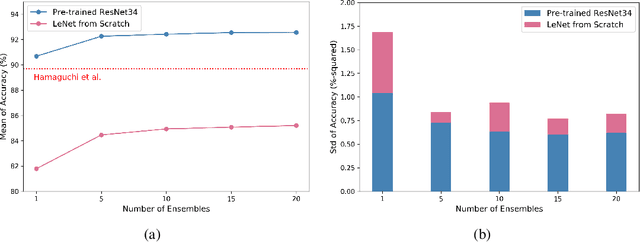
Automatic post-disaster damage detection using aerial imagery is crucial for quick assessment of damage caused by disaster and development of a recovery plan. The main problem preventing us from creating an applicable model in practice is that damaged (positive) examples we are trying to detect are much harder to obtain than undamaged (negative) examples, especially in short time. In this paper, we revisit the classical bootstrap aggregating approach in the context of modern transfer learning for data-efficient disaster damage detection. Unlike previous classical ensemble learning articles, our work points out the effectiveness of simple bagging in deep transfer learning that has been underestimated in the context of imbalanced classification. Benchmark results on the AIST Building Change Detection dataset show that our approach significantly outperforms existing methodologies, including the recently proposed disentanglement learning.
Quantization for Rapid Deployment of Deep Neural Networks
Oct 12, 2018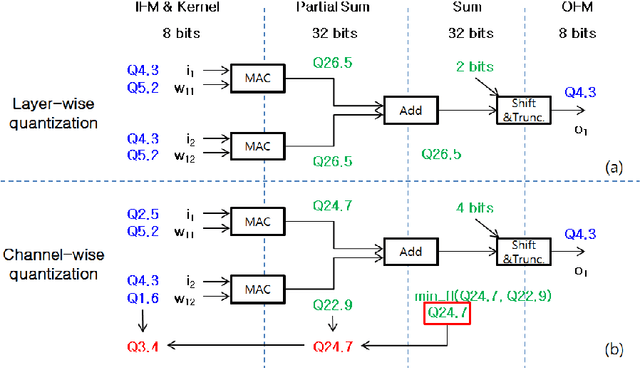
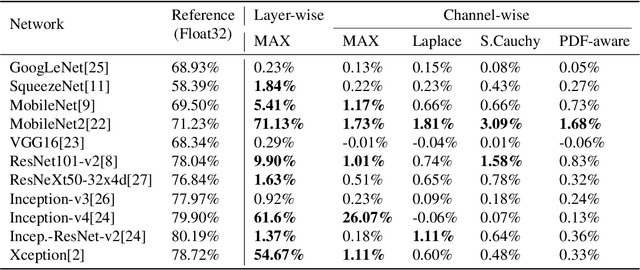
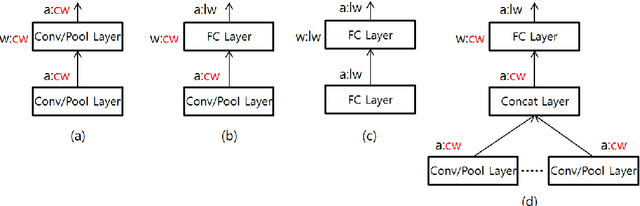

This paper aims at rapid deployment of the state-of-the-art deep neural networks (DNNs) to energy efficient accelerators without time-consuming fine tuning or the availability of the full datasets. Converting DNNs in full precision to limited precision is essential in taking advantage of the accelerators with reduced memory footprint and computation power. However, such a task is not trivial since it often requires the full training and validation datasets for profiling the network statistics and fine tuning the networks to recover the accuracy lost after quantization. To address these issues, we propose a simple method recognizing channel-level distribution to reduce the quantization-induced accuracy loss and minimize the required image samples for profiling. We evaluated our method on eleven networks trained on the ImageNet classification benchmark and a network trained on the Pascal VOC object detection benchmark. The results prove that the networks can be quantized into 8-bit integer precision without fine tuning.
Training Deep Neural Network in Limited Precision
Oct 12, 2018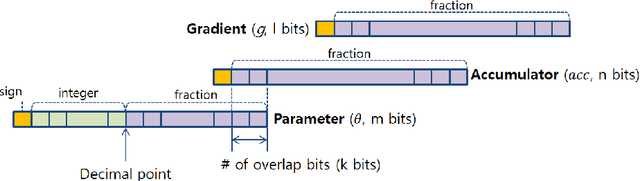
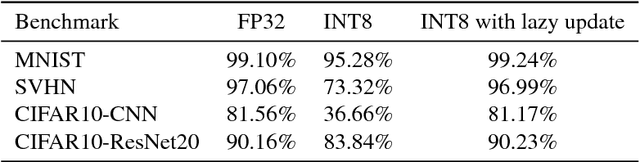
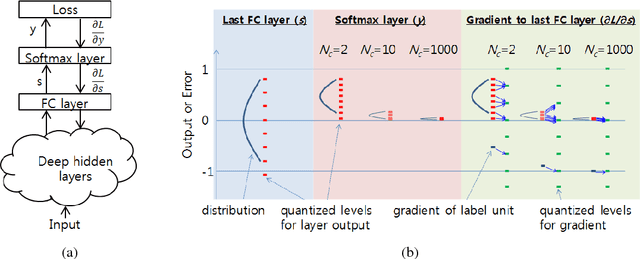
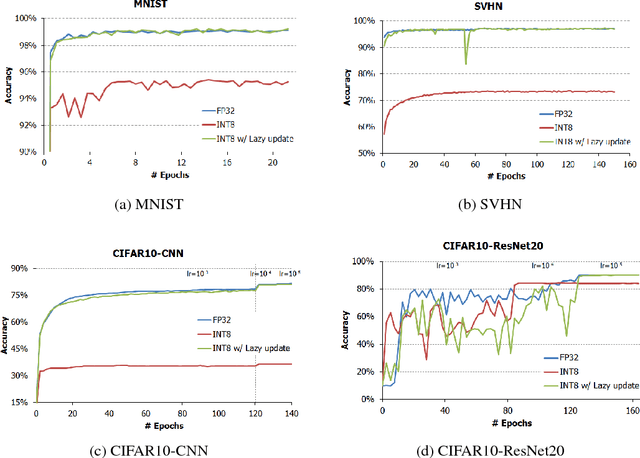
Energy and resource efficient training of DNNs will greatly extend the applications of deep learning. However, there are three major obstacles which mandate accurate calculation in high precision. In this paper, we tackle two of them related to the loss of gradients during parameter update and backpropagation through a softmax nonlinearity layer in low precision training. We implemented SGD with Kahan summation by employing an additional parameter to virtually extend the bit-width of the parameters for a reliable parameter update. We also proposed a simple guideline to help select the appropriate bit-width for the last FC layer followed by a softmax nonlinearity layer. It determines the lower bound of the required bit-width based on the class size of the dataset. Extensive experiments on various network architectures and benchmarks verifies the effectiveness of the proposed technique for low precision training.