 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Deep Neural Network in Limited Precision
Oct 12, 2018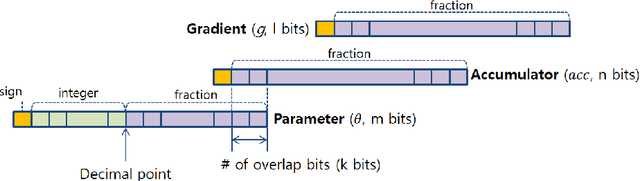
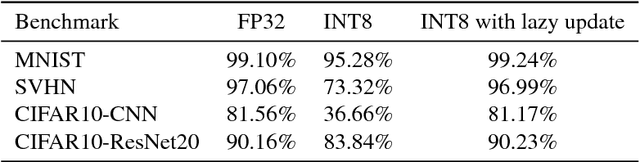
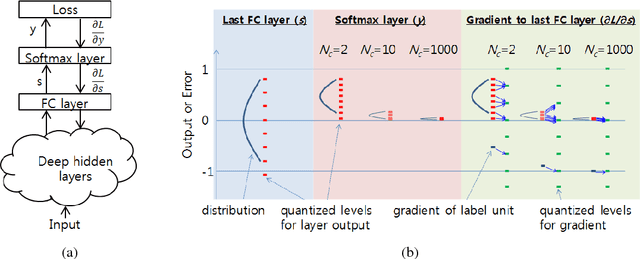
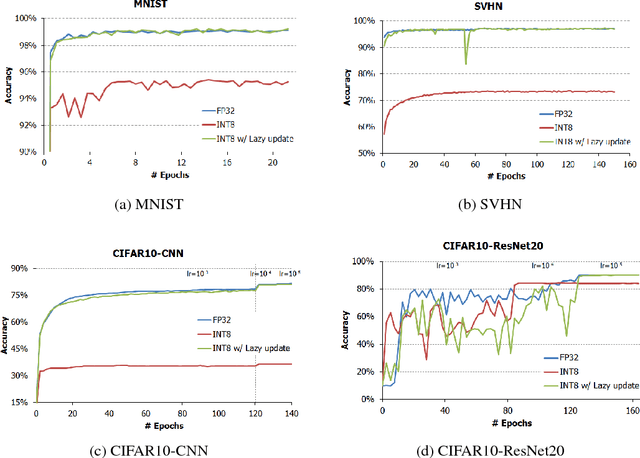
Energy and resource efficient training of DNNs will greatly extend the applications of deep learning. However, there are three major obstacles which mandate accurate calculation in high precision. In this paper, we tackle two of them related to the loss of gradients during parameter update and backpropagation through a softmax nonlinearity layer in low precision training. We implemented SGD with Kahan summation by employing an additional parameter to virtually extend the bit-width of the parameters for a reliable parameter update. We also proposed a simple guideline to help select the appropriate bit-width for the last FC layer followed by a softmax nonlinearity layer. It determines the lower bound of the required bit-width based on the class size of the dataset. Extensive experiments on various network architectures and benchmarks verifies the effectiveness of the proposed technique for low precision training.