 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Negative Guidance in Attention Feature Space for Text-to-Image Generation
May 28, 2026Text-to-image (T2I) models have become increasingly capable of generating high-quality images. Yet, enforcing the explicit absence of a specified object or attribute remains a fundamentally challenging problem. Existing approaches, including prompt negation, post-hoc editing, and negative guidance, remain insufficient for explicit concept suppression, often failing to remove the target concept or degrading overall image quality. To this end, we propose Orthogonal Negative Guidance in attention feature space, a training-free method that operates in the attention output space of MM-DiT-based T2I transformers. Our method orthogonalizes negative-prompt attention features with respect to positive-prompt features and subtracts only the orthogonal component, suppressing unwanted concepts while preserving desired semantics. Experiments on FLUX-dev and FLUX-schnell show that our method achieves favorable trade-offs between concept suppression, prompt alignment, and image quality. In human evaluation, our method outperforms the second-best baseline by 18.78%. We further show that our method supports multi-concept suppression and adjustable concept suppression.
DOS: Directional Object Separation in Text Embeddings for Multi-Object Image Generation
Oct 16, 2025



Recent progress in text-to-image (T2I) generative models has led to significant improvements in generating high-quality images aligned with text prompts. However, these models still struggle with prompts involving multiple objects, often resulting in object neglect or object mixing. Through extensive studies, we identify four problematic scenarios, Similar Shapes, Similar Textures, Dissimilar Background Biases, and Many Objects, where inter-object relationships frequently lead to such failures. Motivated by two key observations about CLIP embeddings, we propose DOS (Directional Object Separation), a method that modifies three types of CLIP text embeddings before passing them into text-to-image models. Experimental results show that DOS consistently improves the success rate of multi-object image generation and reduces object mixing. In human evaluations, DOS significantly outperforms four competing methods, receiving 26.24%-43.04% more votes across four benchmarks. These results highlight DOS as a practical and effective solution for improving multi-object image generation.
An Image Grid Can Be Worth a Video: Zero-shot Video Question Answering Using a VLM
Mar 27, 2024



Stimulated by the sophisticated reasoning capabilities of recent Large Language Models (LLMs), a variety of strategies for bridging video modality have been devised. A prominent strategy involves Video Language Models (VideoLMs), which train a learnable interface with video data to connect advanced vision encoders with LLMs. Recently, an alternative strategy has surfaced, employing readily available foundation models, such as VideoLMs and LLMs, across multiple stages for modality bridging. In this study, we introduce a simple yet novel strategy where only a single Vision Language Model (VLM) is utilized. Our starting point is the plain insight that a video comprises a series of images, or frames, interwoven with temporal information. The essence of video comprehension lies in adeptly managing the temporal aspects along with the spatial details of each frame. Initially, we transform a video into a single composite image by arranging multiple frames in a grid layout. The resulting single image is termed as an image grid. This format, while maintaining the appearance of a solitary image, effectively retains temporal information within the grid structure. Therefore, the image grid approach enables direct application of a single high-performance VLM without necessitating any video-data training. Our extensive experimental analysis across ten zero-shot video question answering benchmarks, including five open-ended and five multiple-choice benchmarks, reveals that the proposed Image Grid Vision Language Model (IG-VLM) surpasses the existing methods in nine out of ten benchmarks.
Breaking MLPerf Training: A Case Study on Optimizing BERT
Feb 04, 2024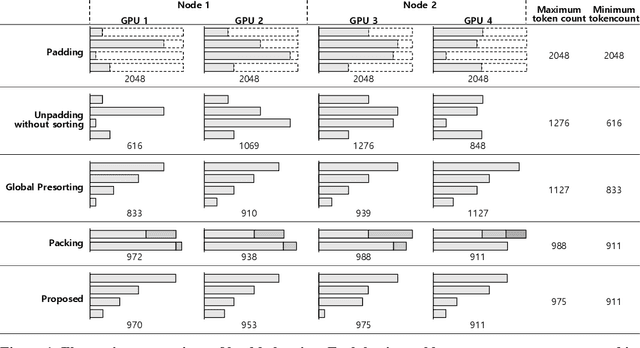
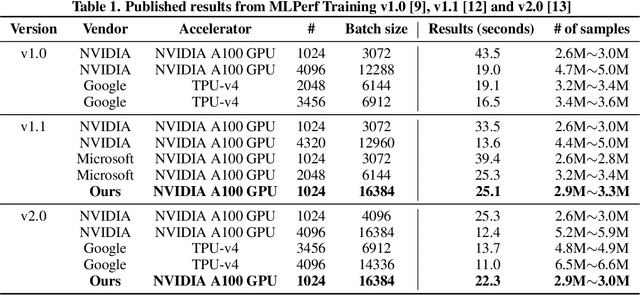
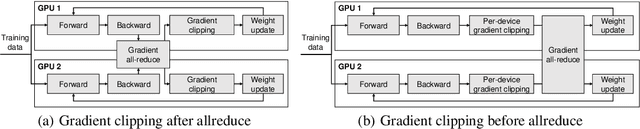
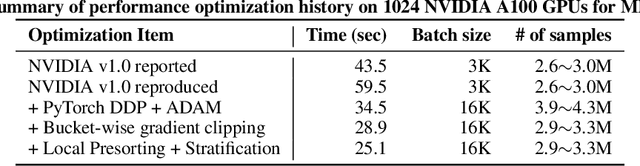
Speeding up the large-scale distributed training is challenging in that it requires improving various components of training including load balancing, communication, optimizers, etc. We present novel approaches for fast large-scale training of BERT model which individually ameliorates each component thereby leading to a new level of BERT training performance. Load balancing is imperative in distributed BERT training since its training datasets are characterized by samples with various lengths. Communication cost, which is proportional to the scale of distributed training, needs to be hidden by useful computation. In addition, the optimizers, e.g., ADAM, LAMB, etc., need to be carefully re-evaluated in the context of large-scale distributed training. We propose two new ideas, (1) local presorting based on dataset stratification for load balancing and (2) bucket-wise gradient clipping before allreduce which allows us to benefit from the overlap of gradient computation and synchronization as well as the fast training of gradient clipping before allreduce. We also re-evaluate existing optimizers via hyperparameter optimization and utilize ADAM, which also contributes to fast training via larger batches than existing methods. Our proposed methods, all combined, give the fastest MLPerf BERT training of 25.1 (22.3) seconds on 1,024 NVIDIA A100 GPUs, which is 1.33x (1.13x) and 1.57x faster than the other top two (one) submissions to MLPerf v1.1 (v2.0). Our implementation and evaluation results are available at MLPerf v1.1~v2.1.