 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Negative Guidance in Attention Feature Space for Text-to-Image Generation
May 28, 2026Text-to-image (T2I) models have become increasingly capable of generating high-quality images. Yet, enforcing the explicit absence of a specified object or attribute remains a fundamentally challenging problem. Existing approaches, including prompt negation, post-hoc editing, and negative guidance, remain insufficient for explicit concept suppression, often failing to remove the target concept or degrading overall image quality. To this end, we propose Orthogonal Negative Guidance in attention feature space, a training-free method that operates in the attention output space of MM-DiT-based T2I transformers. Our method orthogonalizes negative-prompt attention features with respect to positive-prompt features and subtracts only the orthogonal component, suppressing unwanted concepts while preserving desired semantics. Experiments on FLUX-dev and FLUX-schnell show that our method achieves favorable trade-offs between concept suppression, prompt alignment, and image quality. In human evaluation, our method outperforms the second-best baseline by 18.78%. We further show that our method supports multi-concept suppression and adjustable concept suppression.
Task-Specific Preconditioner for Cross-Domain Few-Shot Learning
Dec 20, 2024
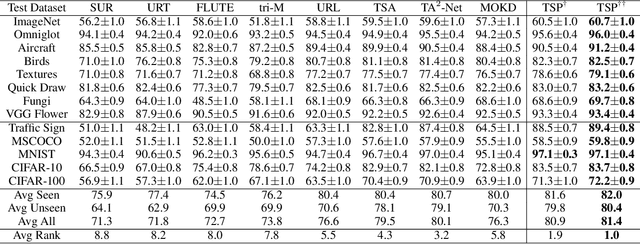
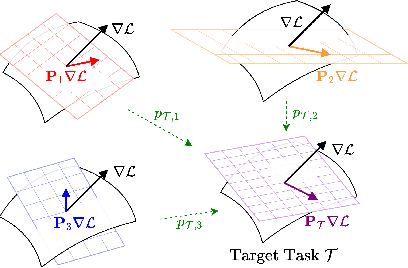
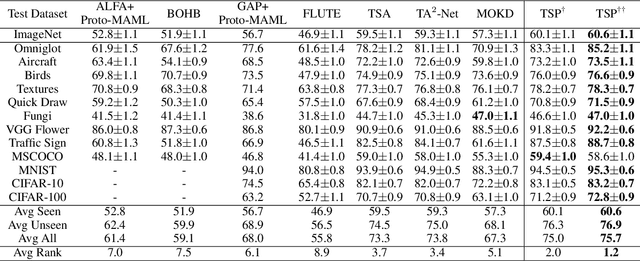
Cross-Domain Few-Shot Learning~(CDFSL) methods typically parameterize models with task-agnostic and task-specific parameters. To adapt task-specific parameters, recent approaches have utilized fixed optimization strategies, despite their potential sub-optimality across varying domains or target tasks. To address this issue, we propose a novel adaptation mechanism called Task-Specific Preconditioned gradient descent~(TSP). Our method first meta-learns Domain-Specific Preconditioners~(DSPs) that capture the characteristics of each meta-training domain, which are then linearly combined using task-coefficients to form the Task-Specific Preconditioner. The preconditioner is applied to gradient descent, making the optimization adaptive to the target task. We constrain our preconditioners to be positive definite, guiding the preconditioned gradient toward the direction of steepest descent. Empirical evaluations on the Meta-Dataset show that TSP achieves state-of-the-art performance across diverse experimental scenarios.
SAAS: Solving Ability Amplification Strategy for Enhanced Mathematical Reasoning in Large Language Models
Apr 08, 2024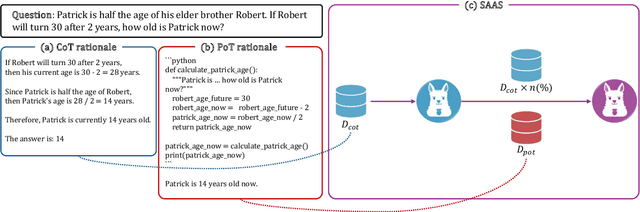
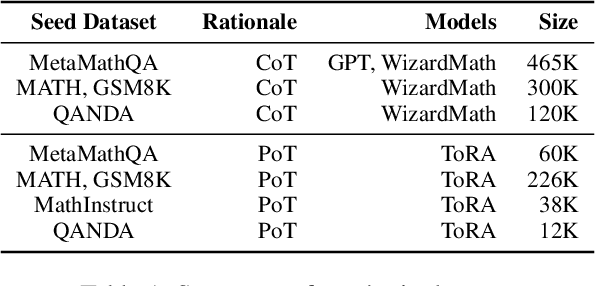

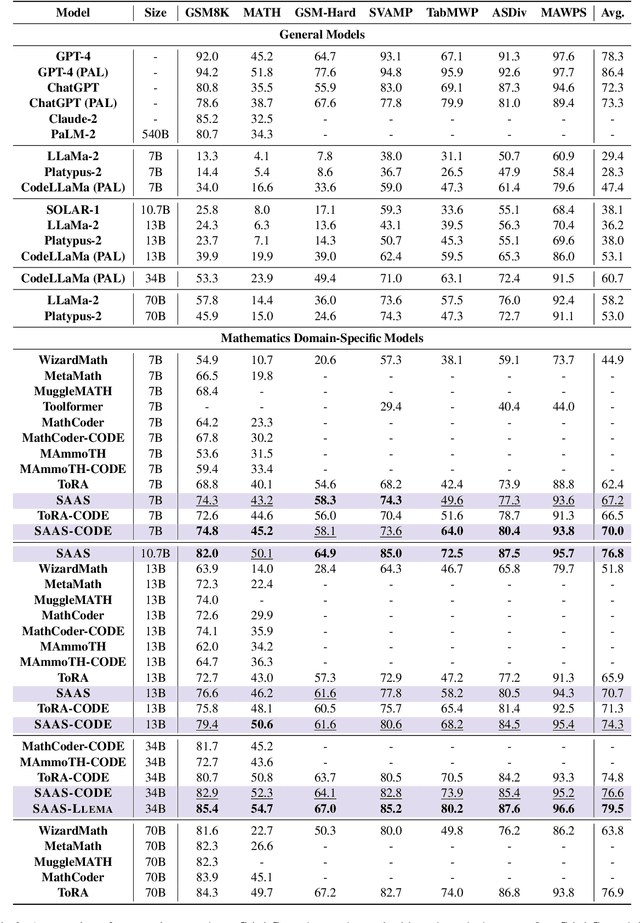
This study presents a novel learning approach designed to enhance both mathematical reasoning and problem-solving abilities of Large Language Models (LLMs). We focus on integrating the Chain-of-Thought (CoT) and the Program-of-Thought (PoT) learning, hypothesizing that prioritizing the learning of mathematical reasoning ability is helpful for the amplification of problem-solving ability. Thus, the initial learning with CoT is essential for solving challenging mathematical problems. To this end, we propose a sequential learning approach, named SAAS (Solving Ability Amplification Strategy), which strategically transitions from CoT learning to PoT learning. Our empirical study, involving an extensive performance comparison using several benchmarks, demonstrates that our SAAS achieves state-of-the-art (SOTA) performance. The results underscore the effectiveness of our sequential learning approach, marking a significant advancement in the field of mathematical reasoning in LLMs.
An Image Grid Can Be Worth a Video: Zero-shot Video Question Answering Using a VLM
Mar 27, 2024



Stimulated by the sophisticated reasoning capabilities of recent Large Language Models (LLMs), a variety of strategies for bridging video modality have been devised. A prominent strategy involves Video Language Models (VideoLMs), which train a learnable interface with video data to connect advanced vision encoders with LLMs. Recently, an alternative strategy has surfaced, employing readily available foundation models, such as VideoLMs and LLMs, across multiple stages for modality bridging. In this study, we introduce a simple yet novel strategy where only a single Vision Language Model (VLM) is utilized. Our starting point is the plain insight that a video comprises a series of images, or frames, interwoven with temporal information. The essence of video comprehension lies in adeptly managing the temporal aspects along with the spatial details of each frame. Initially, we transform a video into a single composite image by arranging multiple frames in a grid layout. The resulting single image is termed as an image grid. This format, while maintaining the appearance of a solitary image, effectively retains temporal information within the grid structure. Therefore, the image grid approach enables direct application of a single high-performance VLM without necessitating any video-data training. Our extensive experimental analysis across ten zero-shot video question answering benchmarks, including five open-ended and five multiple-choice benchmarks, reveals that the proposed Image Grid Vision Language Model (IG-VLM) surpasses the existing methods in nine out of ten benchmarks.
Improving Forward Compatibility in Class Incremental Learning by Increasing Representation Rank and Feature Richness
Mar 22, 2024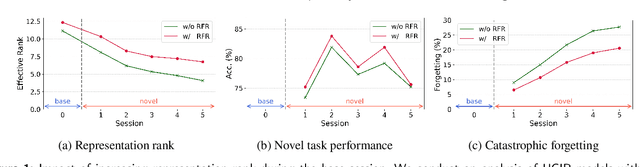
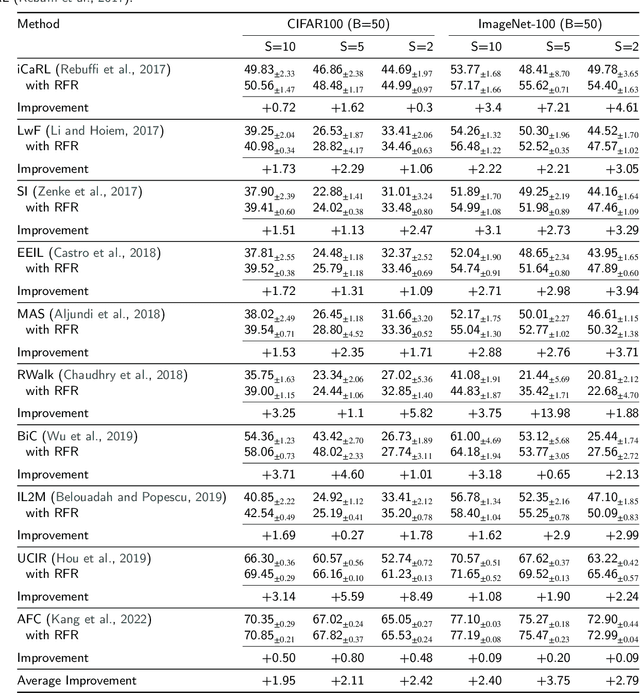
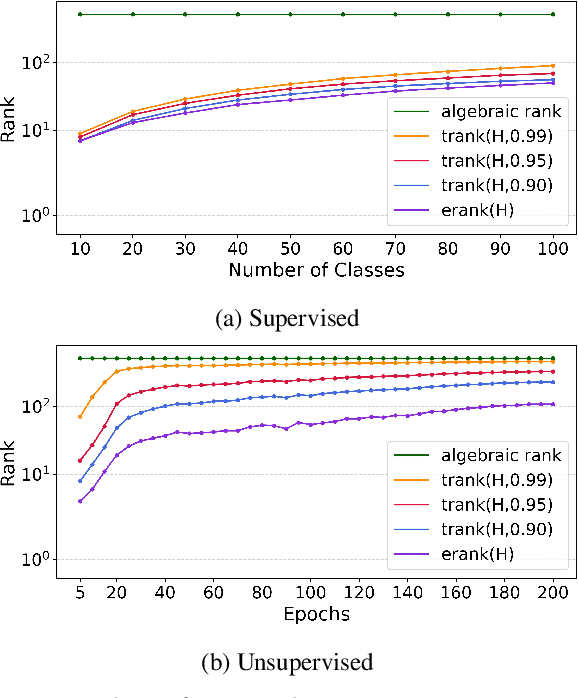
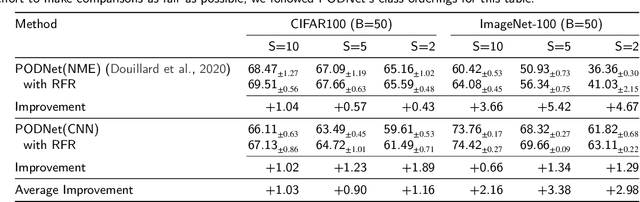
Class Incremental Learning (CIL) constitutes a pivotal subfield within continual learning, aimed at enabling models to progressively learn new classification tasks while retaining knowledge obtained from prior tasks. Although previous studies have predominantly focused on backward compatible approaches to mitigate catastrophic forgetting, recent investigations have introduced forward compatible methods to enhance performance on novel tasks and complement existing backward compatible methods. In this study, we introduce an effective-Rank based Feature Richness enhancement (RFR) method, designed for improving forward compatibility. Specifically, this method increases the effective rank of representations during the base session, thereby facilitating the incorporation of more informative features pertinent to unseen novel tasks. Consequently, RFR achieves dual objectives in backward and forward compatibility: minimizing feature extractor modifications and enhancing novel task performance, respectively. To validate the efficacy of our approach, we establish a theoretical connection between effective rank and the Shannon entropy of representations. Subsequently, we conduct comprehensive experiments by integrating RFR into eleven well-known CIL methods. Our results demonstrate the effectiveness of our approach in enhancing novel-task performance while mitigating catastrophic forgetting. Furthermore, our method notably improves the average incremental accuracy across all eleven cases examined.
Semantics-Preserving Adversarial Training
Sep 23, 2020



Adversarial training is a defense technique that improves adversarial robustness of a deep neural network (DNN) by including adversarial examples in the training data. In this paper, we identify an overlooked problem of adversarial training in that these adversarial examples often have different semantics than the original data, introducing unintended biases into the model. We hypothesize that such non-semantics-preserving (and resultingly ambiguous) adversarial data harm the robustness of the target models. To mitigate such unintended semantic changes of adversarial examples, we propose semantics-preserving adversarial training (SPAT) which encourages perturbation on the pixels that are shared among all classes when generating adversarial examples in the training stage. Experiment results show that SPAT improves adversarial robustness and achieves state-of-the-art results in CIFAR-10 and CIFAR-100.