 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiTab: A Comprehensive Benchmark Suite for Multi-Dimensional Evaluation in Tabular Domains
May 20, 2025Despite the widespread use of tabular data in real-world applications, most benchmarks rely on average-case metrics, which fail to reveal how model behavior varies across diverse data regimes. To address this, we propose MultiTab, a benchmark suite and evaluation framework for multi-dimensional, data-aware analysis of tabular learning algorithms. Rather than comparing models only in aggregate, MultiTab categorizes 196 publicly available datasets along key data characteristics, including sample size, label imbalance, and feature interaction, and evaluates 13 representative models spanning a range of inductive biases. Our analysis shows that model performance is highly sensitive to such regimes: for example, models using sample-level similarity excel on datasets with large sample sizes or high inter-feature correlation, while models encoding inter-feature dependencies perform best with weakly correlated features. These findings reveal that inductive biases do not always behave as intended, and that regime-aware evaluation is essential for understanding and improving model behavior. MultiTab enables more principled model design and offers practical guidance for selecting models tailored to specific data characteristics. All datasets, code, and optimization logs are publicly available at https://huggingface.co/datasets/LGAI-DILab/Multitab.
Towards a Better Evaluation of Out-of-Domain Generalization
Jun 02, 2024The objective of Domain Generalization (DG) is to devise algorithms and models capable of achieving high performance on previously unseen test distributions. In the pursuit of this objective, average measure has been employed as the prevalent measure for evaluating models and comparing algorithms in the existing DG studies. Despite its significance, a comprehensive exploration of the average measure has been lacking and its suitability in approximating the true domain generalization performance has been questionable. In this study, we carefully investigate the limitations inherent in the average measure and propose worst+gap measure as a robust alternative. We establish theoretical grounds of the proposed measure by deriving two theorems starting from two different assumptions. We conduct extensive experimental investigations to compare the proposed worst+gap measure with the conventional average measure. Given the indispensable need to access the true DG performance for studying measures, we modify five existing datasets to come up with SR-CMNIST, C-Cats&Dogs, L-CIFAR10, PACS-corrupted, and VLCS-corrupted datasets. The experiment results unveil an inferior performance of the average measure in approximating the true DG performance and confirm the robustness of the theoretically supported worst+gap measure.
Binning as a Pretext Task: Improving Self-Supervised Learning in Tabular Domains
May 14, 2024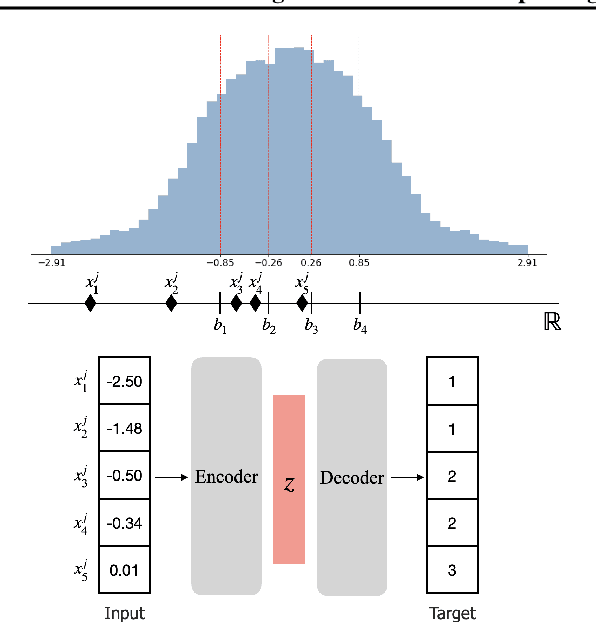
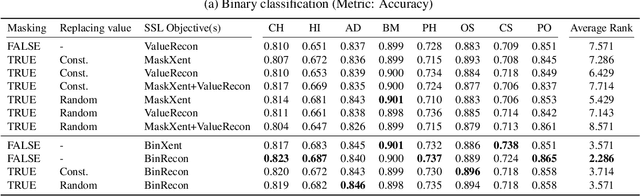
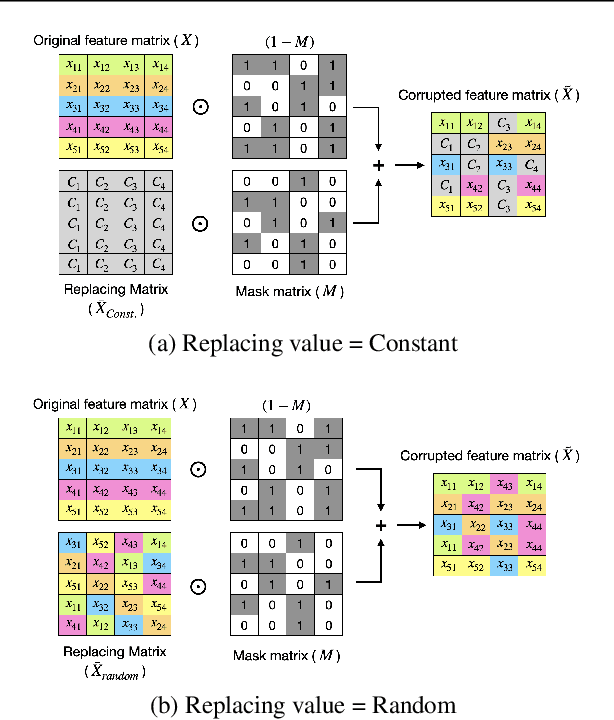
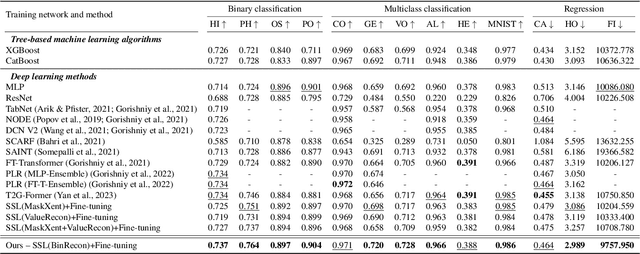
The ability of deep networks to learn superior representations hinges on leveraging the proper inductive biases, considering the inherent properties of datasets. In tabular domains, it is critical to effectively handle heterogeneous features (both categorical and numerical) in a unified manner and to grasp irregular functions like piecewise constant functions. To address the challenges in the self-supervised learning framework, we propose a novel pretext task based on the classical binning method. The idea is straightforward: reconstructing the bin indices (either orders or classes) rather than the original values. This pretext task provides the encoder with an inductive bias to capture the irregular dependencies, mapping from continuous inputs to discretized bins, and mitigates the feature heterogeneity by setting all features to have category-type targets. Our empirical investigations ascertain several advantages of binning: capturing the irregular function, compatibility with encoder architecture and additional modifications, standardizing all features into equal sets, grouping similar values within a feature, and providing ordering information. Comprehensive evaluations across diverse tabular datasets corroborate that our method consistently improves tabular representation learning performance for a wide range of downstream tasks. The codes are available in https://github.com/kyungeun-lee/tabularbinning.
Improving Forward Compatibility in Class Incremental Learning by Increasing Representation Rank and Feature Richness
Mar 22, 2024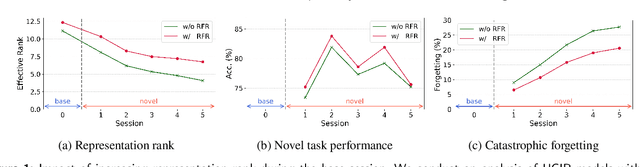
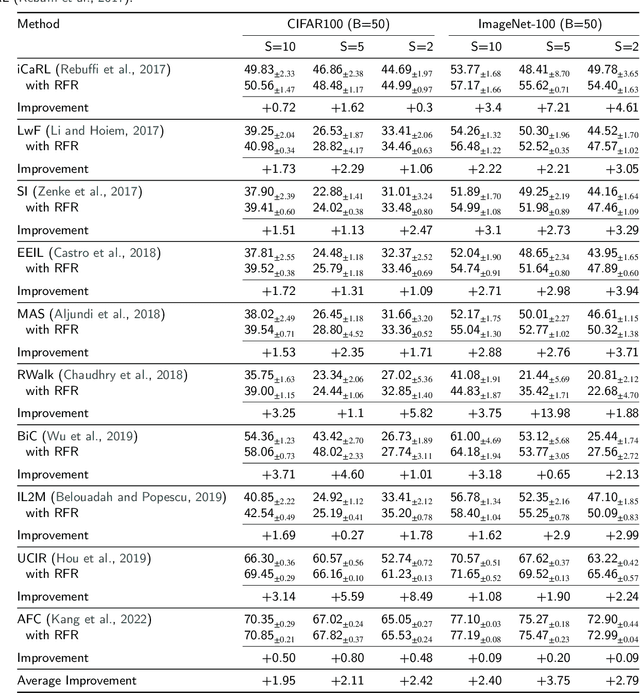
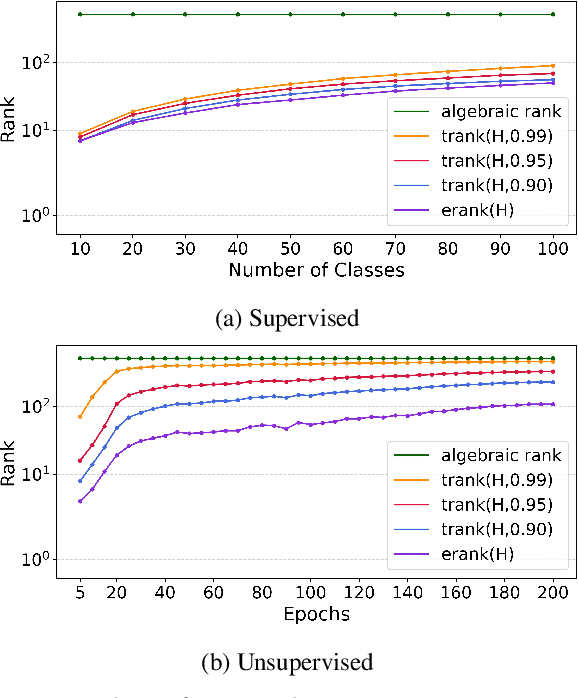
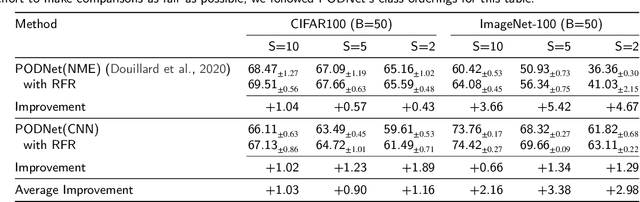
Class Incremental Learning (CIL) constitutes a pivotal subfield within continual learning, aimed at enabling models to progressively learn new classification tasks while retaining knowledge obtained from prior tasks. Although previous studies have predominantly focused on backward compatible approaches to mitigate catastrophic forgetting, recent investigations have introduced forward compatible methods to enhance performance on novel tasks and complement existing backward compatible methods. In this study, we introduce an effective-Rank based Feature Richness enhancement (RFR) method, designed for improving forward compatibility. Specifically, this method increases the effective rank of representations during the base session, thereby facilitating the incorporation of more informative features pertinent to unseen novel tasks. Consequently, RFR achieves dual objectives in backward and forward compatibility: minimizing feature extractor modifications and enhancing novel task performance, respectively. To validate the efficacy of our approach, we establish a theoretical connection between effective rank and the Shannon entropy of representations. Subsequently, we conduct comprehensive experiments by integrating RFR into eleven well-known CIL methods. Our results demonstrate the effectiveness of our approach in enhancing novel-task performance while mitigating catastrophic forgetting. Furthermore, our method notably improves the average incremental accuracy across all eleven cases examined.
A Differentiable Framework for End-to-End Learning of Hybrid Structured Compression
Sep 21, 2023



Filter pruning and low-rank decomposition are two of the foundational techniques for structured compression. Although recent efforts have explored hybrid approaches aiming to integrate the advantages of both techniques, their performance gains have been modest at best. In this study, we develop a \textit{Differentiable Framework~(DF)} that can express filter selection, rank selection, and budget constraint into a single analytical formulation. Within the framework, we introduce DML-S for filter selection, integrating scheduling into existing mask learning techniques. Additionally, we present DTL-S for rank selection, utilizing a singular value thresholding operator. The framework with DML-S and DTL-S offers a hybrid structured compression methodology that facilitates end-to-end learning through gradient-base optimization. Experimental results demonstrate the efficacy of DF, surpassing state-of-the-art structured compression methods. Our work establishes a robust and versatile avenue for advancing structured compression techniques.
Meta-Learning with a Geometry-Adaptive Preconditioner
Apr 04, 2023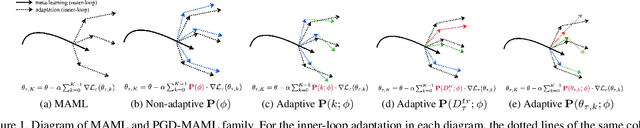

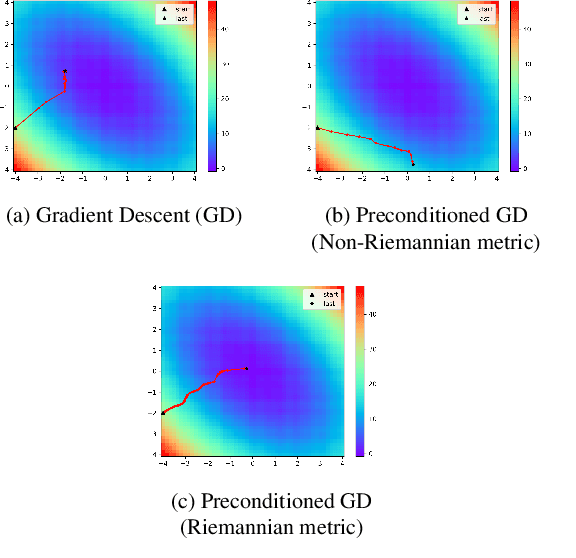
Model-agnostic meta-learning (MAML) is one of the most successful meta-learning algorithms. It has a bi-level optimization structure where the outer-loop process learns a shared initialization and the inner-loop process optimizes task-specific weights. Although MAML relies on the standard gradient descent in the inner-loop, recent studies have shown that controlling the inner-loop's gradient descent with a meta-learned preconditioner can be beneficial. Existing preconditioners, however, cannot simultaneously adapt in a task-specific and path-dependent way. Additionally, they do not satisfy the Riemannian metric condition, which can enable the steepest descent learning with preconditioned gradient. In this study, we propose Geometry-Adaptive Preconditioned gradient descent (GAP) that can overcome the limitations in MAML; GAP can efficiently meta-learn a preconditioner that is dependent on task-specific parameters, and its preconditioner can be shown to be a Riemannian metric. Thanks to the two properties, the geometry-adaptive preconditioner is effective for improving the inner-loop optimization. Experiment results show that GAP outperforms the state-of-the-art MAML family and preconditioned gradient descent-MAML (PGD-MAML) family in a variety of few-shot learning tasks. Code is available at: https://github.com/Suhyun777/CVPR23-GAP.
A Highly Effective Low-Rank Compression of Deep Neural Networks with Modified Beam-Search and Modified Stable Rank
Dec 01, 2021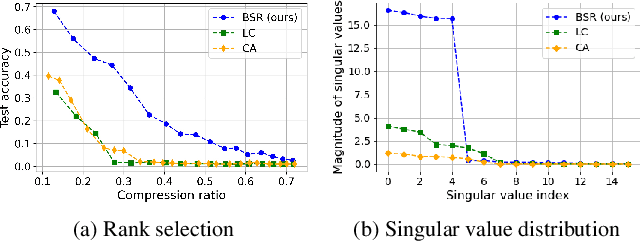
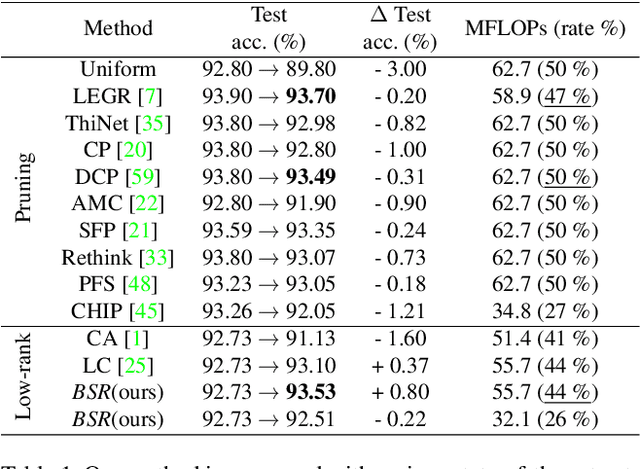
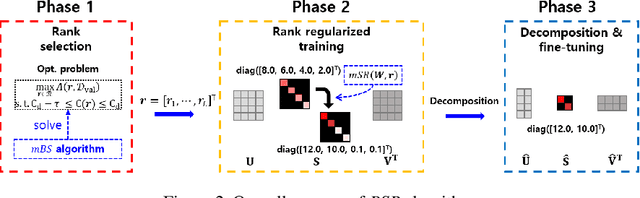

Compression has emerged as one of the essential deep learning research topics, especially for the edge devices that have limited computation power and storage capacity. Among the main compression techniques, low-rank compression via matrix factorization has been known to have two problems. First, an extensive tuning is required. Second, the resulting compression performance is typically not impressive. In this work, we propose a low-rank compression method that utilizes a modified beam-search for an automatic rank selection and a modified stable rank for a compression-friendly training. The resulting BSR (Beam-search and Stable Rank) algorithm requires only a single hyperparameter to be tuned for the desired compression ratio. The performance of BSR in terms of accuracy and compression ratio trade-off curve turns out to be superior to the previously known low-rank compression methods. Furthermore, BSR can perform on par with or better than the state-of-the-art structured pruning methods. As with pruning, BSR can be easily combined with quantization for an additional compression.
Short-term Traffic Prediction with Deep Neural Networks: A Survey
Aug 28, 2020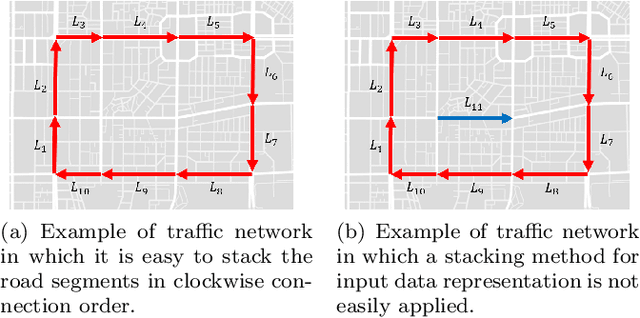
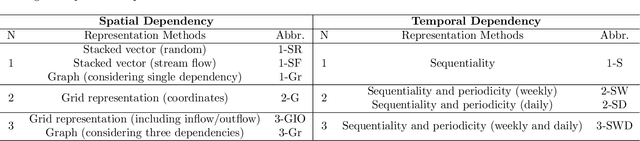
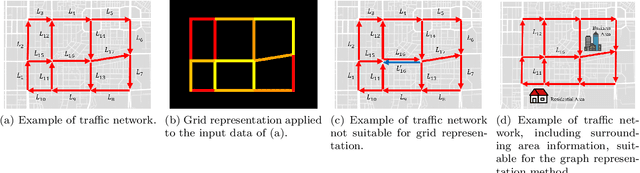
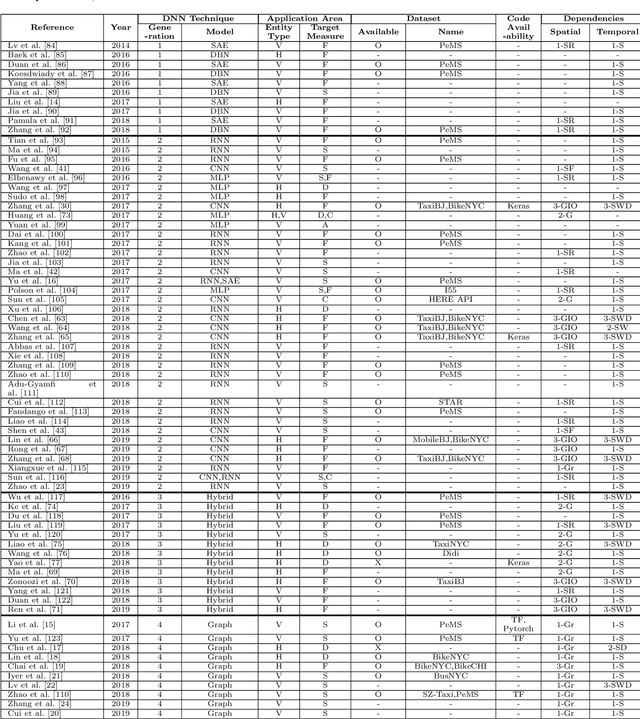
In modern transportation systems, an enormous amount of traffic data is generated every day. This has led to rapid progress in short-term traffic prediction (STTP), in which deep learning methods have recently been applied. In traffic networks with complex spatiotemporal relationships, deep neural networks (DNNs) often perform well because they are capable of automatically extracting the most important features and patterns. In this study, we survey recent STTP studies applying deep networks from four perspectives. 1) We summarize input data representation methods according to the number and type of spatial and temporal dependencies involved. 2) We briefly explain a wide range of DNN techniques from the earliest networks, including Restricted Boltzmann Machines, to the most recent, including graph-based and meta-learning networks. 3) We summarize previous STTP studies in terms of the type of DNN techniques, application area, dataset and code availability, and the type of the represented spatiotemporal dependencies. 4) We compile public traffic datasets that are popular and can be used as the standard benchmarks. Finally, we suggest challenging issues and possible future research directions in STTP.