 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Better Evaluation of Out-of-Domain Generalization
Jun 02, 2024The objective of Domain Generalization (DG) is to devise algorithms and models capable of achieving high performance on previously unseen test distributions. In the pursuit of this objective, average measure has been employed as the prevalent measure for evaluating models and comparing algorithms in the existing DG studies. Despite its significance, a comprehensive exploration of the average measure has been lacking and its suitability in approximating the true domain generalization performance has been questionable. In this study, we carefully investigate the limitations inherent in the average measure and propose worst+gap measure as a robust alternative. We establish theoretical grounds of the proposed measure by deriving two theorems starting from two different assumptions. We conduct extensive experimental investigations to compare the proposed worst+gap measure with the conventional average measure. Given the indispensable need to access the true DG performance for studying measures, we modify five existing datasets to come up with SR-CMNIST, C-Cats&Dogs, L-CIFAR10, PACS-corrupted, and VLCS-corrupted datasets. The experiment results unveil an inferior performance of the average measure in approximating the true DG performance and confirm the robustness of the theoretically supported worst+gap measure.
Enhancing Contrastive Learning with Efficient Combinatorial Positive Pairing
Jan 11, 2024In the past few years, contrastive learning has played a central role for the success of visual unsupervised representation learning. Around the same time, high-performance non-contrastive learning methods have been developed as well. While most of the works utilize only two views, we carefully review the existing multi-view methods and propose a general multi-view strategy that can improve learning speed and performance of any contrastive or non-contrastive method. We first analyze CMC's full-graph paradigm and empirically show that the learning speed of $K$-views can be increased by $_{K}\mathrm{C}_{2}$ times for small learning rate and early training. Then, we upgrade CMC's full-graph by mixing views created by a crop-only augmentation, adopting small-size views as in SwAV multi-crop, and modifying the negative sampling. The resulting multi-view strategy is called ECPP (Efficient Combinatorial Positive Pairing). We investigate the effectiveness of ECPP by applying it to SimCLR and assessing the linear evaluation performance for CIFAR-10 and ImageNet-100. For each benchmark, we achieve a state-of-the-art performance. In case of ImageNet-100, ECPP boosted SimCLR outperforms supervised learning.
Meta-Learning with a Geometry-Adaptive Preconditioner
Apr 04, 2023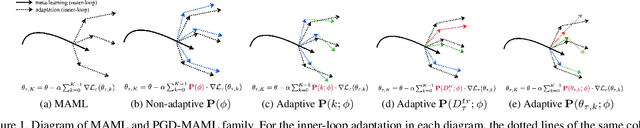

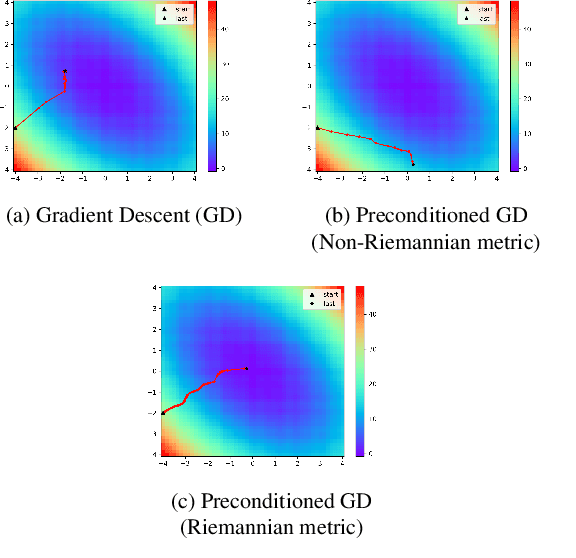
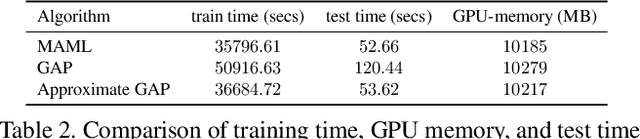
Model-agnostic meta-learning (MAML) is one of the most successful meta-learning algorithms. It has a bi-level optimization structure where the outer-loop process learns a shared initialization and the inner-loop process optimizes task-specific weights. Although MAML relies on the standard gradient descent in the inner-loop, recent studies have shown that controlling the inner-loop's gradient descent with a meta-learned preconditioner can be beneficial. Existing preconditioners, however, cannot simultaneously adapt in a task-specific and path-dependent way. Additionally, they do not satisfy the Riemannian metric condition, which can enable the steepest descent learning with preconditioned gradient. In this study, we propose Geometry-Adaptive Preconditioned gradient descent (GAP) that can overcome the limitations in MAML; GAP can efficiently meta-learn a preconditioner that is dependent on task-specific parameters, and its preconditioner can be shown to be a Riemannian metric. Thanks to the two properties, the geometry-adaptive preconditioner is effective for improving the inner-loop optimization. Experiment results show that GAP outperforms the state-of-the-art MAML family and preconditioned gradient descent-MAML (PGD-MAML) family in a variety of few-shot learning tasks. Code is available at: https://github.com/Suhyun777/CVPR23-GAP.
VNE: An Effective Method for Improving Deep Representation by Manipulating Eigenvalue Distribution
Apr 04, 2023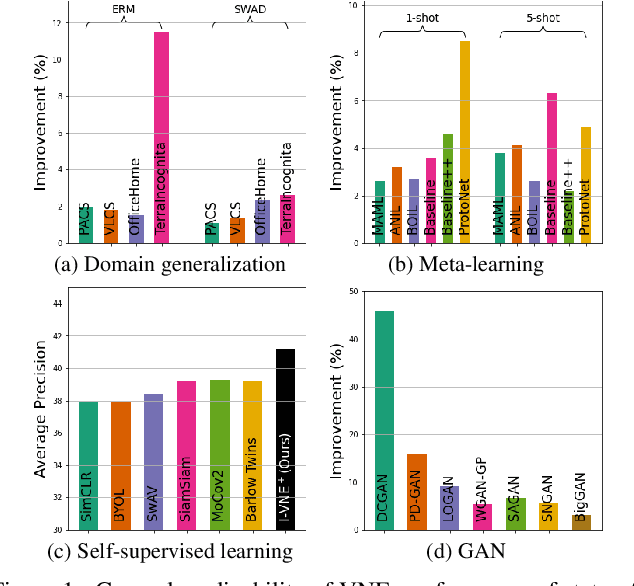
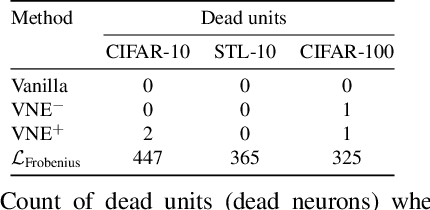
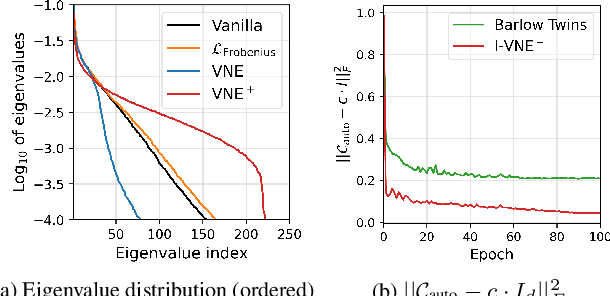
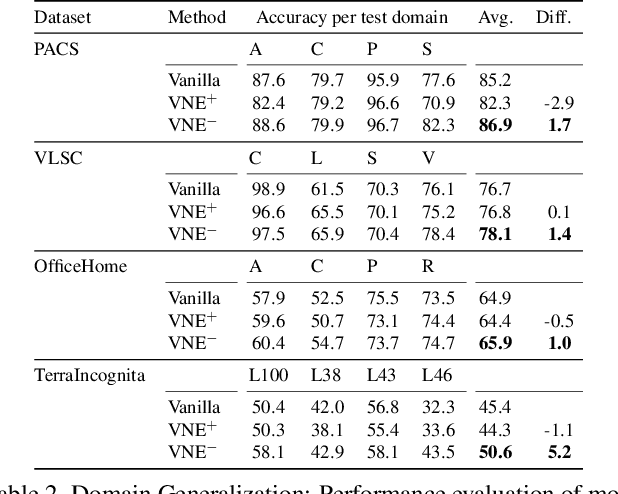
Since the introduction of deep learning, a wide scope of representation properties, such as decorrelation, whitening, disentanglement, rank, isotropy, and mutual information, have been studied to improve the quality of representation. However, manipulating such properties can be challenging in terms of implementational effectiveness and general applicability. To address these limitations, we propose to regularize von Neumann entropy~(VNE) of representation. First, we demonstrate that the mathematical formulation of VNE is superior in effectively manipulating the eigenvalues of the representation autocorrelation matrix. Then, we demonstrate that it is widely applicable in improving state-of-the-art algorithms or popular benchmark algorithms by investigating domain-generalization, meta-learning, self-supervised learning, and generative models. In addition, we formally establish theoretical connections with rank, disentanglement, and isotropy of representation. Finally, we provide discussions on the dimension control of VNE and the relationship with Shannon entropy. Code is available at: https://github.com/jaeill/CVPR23-VNE.
AID-Purifier: A Light Auxiliary Network for Boosting Adversarial Defense
Jul 14, 2021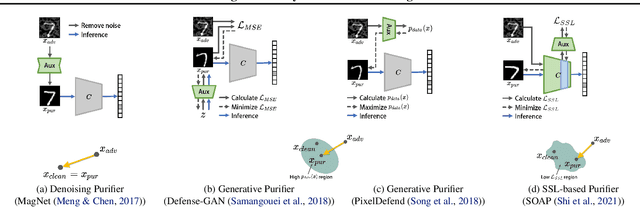
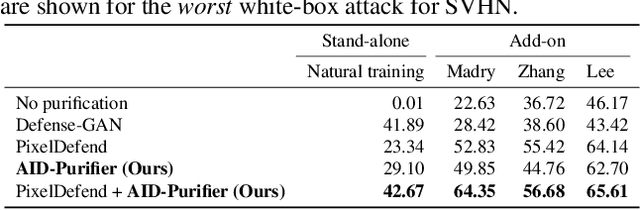
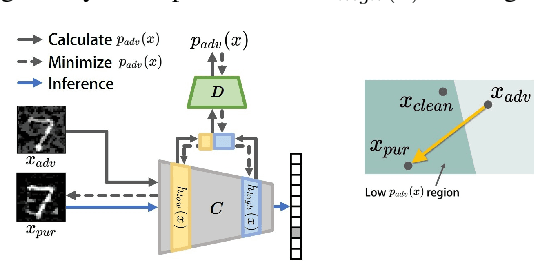

We propose an AID-purifier that can boost the robustness of adversarially-trained networks by purifying their inputs. AID-purifier is an auxiliary network that works as an add-on to an already trained main classifier. To keep it computationally light, it is trained as a discriminator with a binary cross-entropy loss. To obtain additionally useful information from the adversarial examples, the architecture design is closely related to information maximization principles where two layers of the main classification network are piped to the auxiliary network. To assist the iterative optimization procedure of purification, the auxiliary network is trained with AVmixup. AID-purifier can be used together with other purifiers such as PixelDefend for an extra enhancement. The overall results indicate that the best performing adversarially-trained networks can be enhanced by the best performing purification networks, where AID-purifier is a competitive candidate that is light and robust.