 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Attention Head Position Patterns Can Align with Human Visual Concepts in Text-to-Image Generative Models
Dec 03, 2024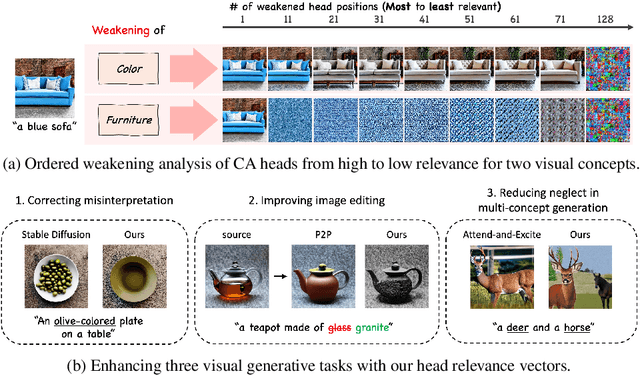
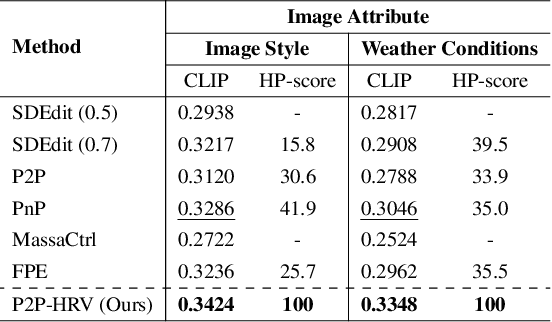
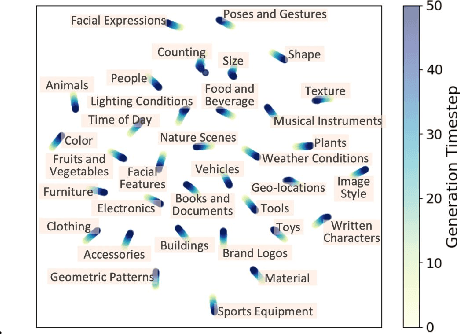

Recent text-to-image diffusion models leverage cross-attention layers, which have been effectively utilized to enhance a range of visual generative tasks. However, our understanding of cross-attention layers remains somewhat limited. In this study, we present a method for constructing Head Relevance Vectors (HRVs) that align with useful visual concepts. An HRV for a given visual concept is a vector with a length equal to the total number of cross-attention heads, where each element represents the importance of the corresponding head for the given visual concept. We develop and employ an ordered weakening analysis to demonstrate the effectiveness of HRVs as interpretable features. To demonstrate the utility of HRVs, we propose concept strengthening and concept adjusting methods and apply them to enhance three visual generative tasks. We show that misinterpretations of polysemous words in image generation can be corrected in most cases, five challenging attributes in image editing can be successfully modified, and catastrophic neglect in multi-concept generation can be mitigated. Overall, our work provides an advancement in understanding cross-attention layers and introduces new approaches for fine-controlling these layers at the head level.
Enhancing Contrastive Learning with Efficient Combinatorial Positive Pairing
Jan 11, 2024In the past few years, contrastive learning has played a central role for the success of visual unsupervised representation learning. Around the same time, high-performance non-contrastive learning methods have been developed as well. While most of the works utilize only two views, we carefully review the existing multi-view methods and propose a general multi-view strategy that can improve learning speed and performance of any contrastive or non-contrastive method. We first analyze CMC's full-graph paradigm and empirically show that the learning speed of $K$-views can be increased by $_{K}\mathrm{C}_{2}$ times for small learning rate and early training. Then, we upgrade CMC's full-graph by mixing views created by a crop-only augmentation, adopting small-size views as in SwAV multi-crop, and modifying the negative sampling. The resulting multi-view strategy is called ECPP (Efficient Combinatorial Positive Pairing). We investigate the effectiveness of ECPP by applying it to SimCLR and assessing the linear evaluation performance for CIFAR-10 and ImageNet-100. For each benchmark, we achieve a state-of-the-art performance. In case of ImageNet-100, ECPP boosted SimCLR outperforms supervised learning.
Evaluating Feature Attribution Methods for Electrocardiogram
Nov 23, 2022



The performance of cardiac arrhythmia detection with electrocardiograms(ECGs) has been considerably improved since the introduction of deep learning models. In practice, the high performance alone is not sufficient and a proper explanation is also required. Recently, researchers have started adopting feature attribution methods to address this requirement, but it has been unclear which of the methods are appropriate for ECG. In this work, we identify and customize three evaluation metrics for feature attribution methods based on the characteristics of ECG: localization score, pointing game, and degradation score. Using the three evaluation metrics, we evaluate and analyze eleven widely-used feature attribution methods. We find that some of the feature attribution methods are much more adequate for explaining ECG, where Grad-CAM outperforms the second-best method by a large margin.
Improving Bi-encoder Document Ranking Models with Two Rankers and Multi-teacher Distillation
Mar 11, 2021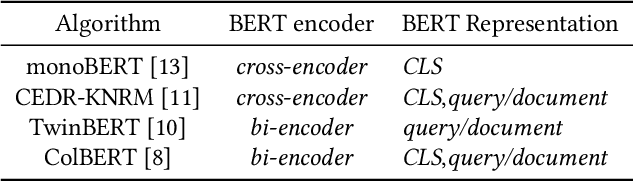
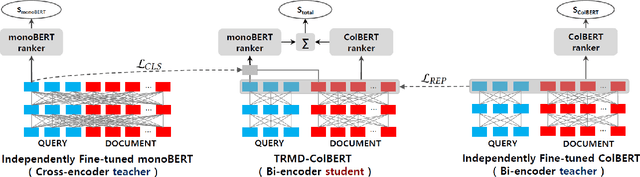
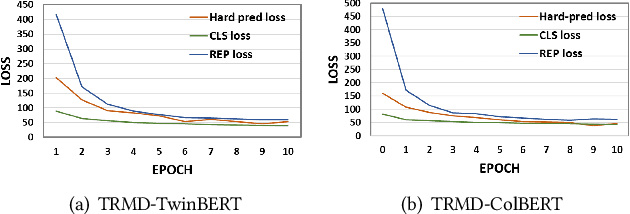
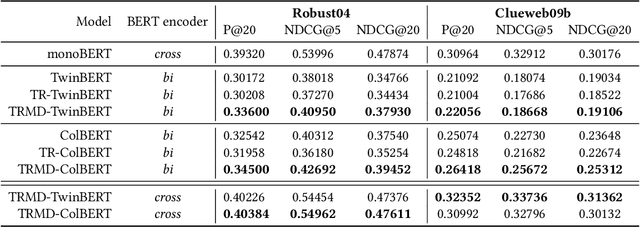
BERT-based Neural Ranking Models (NRMs) can be classified according to how the query and document are encoded through BERT's self-attention layers - bi-encoder versus cross-encoder. Bi-encoder models are highly efficient because all the documents can be pre-processed before the query time, but their performance is inferior compared to cross-encoder models. Both models utilize a ranker that receives BERT representations as the input and generates a relevance score as the output. In this work, we propose a method where multi-teacher distillation is applied to a cross-encoder NRM and a bi-encoder NRM to produce a bi-encoder NRM with two rankers. The resulting student bi-encoder achieves an improved performance by simultaneously learning from a cross-encoder teacher and a bi-encoder teacher and also by combining relevance scores from the two rankers. We call this method TRMD (Two Rankers and Multi-teacher Distillation). In the experiments, TwinBERT and ColBERT are considered as baseline bi-encoders. When monoBERT is used as the cross-encoder teacher, together with either TwinBERT or ColBERT as the bi-encoder teacher, TRMD produces a student bi-encoder that performs better than the corresponding baseline bi-encoder. For P@20, the maximum improvement was 11.4%, and the average improvement was 6.8%. As an additional experiment, we considered producing cross-encoder students with TRMD, and found that it could also improve the cross-encoders.