 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOS: Directional Object Separation in Text Embeddings for Multi-Object Image Generation
Oct 16, 2025



Recent progress in text-to-image (T2I) generative models has led to significant improvements in generating high-quality images aligned with text prompts. However, these models still struggle with prompts involving multiple objects, often resulting in object neglect or object mixing. Through extensive studies, we identify four problematic scenarios, Similar Shapes, Similar Textures, Dissimilar Background Biases, and Many Objects, where inter-object relationships frequently lead to such failures. Motivated by two key observations about CLIP embeddings, we propose DOS (Directional Object Separation), a method that modifies three types of CLIP text embeddings before passing them into text-to-image models. Experimental results show that DOS consistently improves the success rate of multi-object image generation and reduces object mixing. In human evaluations, DOS significantly outperforms four competing methods, receiving 26.24%-43.04% more votes across four benchmarks. These results highlight DOS as a practical and effective solution for improving multi-object image generation.
Cross-Attention Head Position Patterns Can Align with Human Visual Concepts in Text-to-Image Generative Models
Dec 03, 2024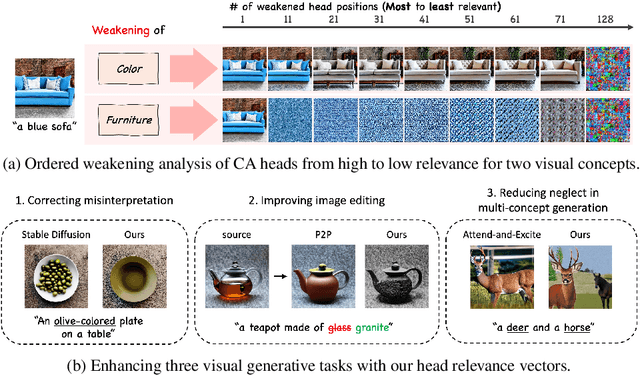
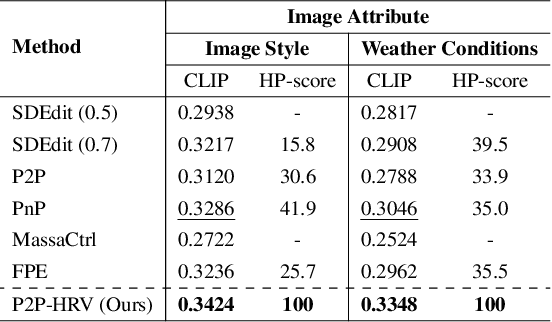
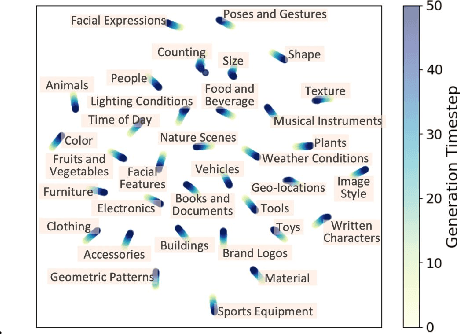

Recent text-to-image diffusion models leverage cross-attention layers, which have been effectively utilized to enhance a range of visual generative tasks. However, our understanding of cross-attention layers remains somewhat limited. In this study, we present a method for constructing Head Relevance Vectors (HRVs) that align with useful visual concepts. An HRV for a given visual concept is a vector with a length equal to the total number of cross-attention heads, where each element represents the importance of the corresponding head for the given visual concept. We develop and employ an ordered weakening analysis to demonstrate the effectiveness of HRVs as interpretable features. To demonstrate the utility of HRVs, we propose concept strengthening and concept adjusting methods and apply them to enhance three visual generative tasks. We show that misinterpretations of polysemous words in image generation can be corrected in most cases, five challenging attributes in image editing can be successfully modified, and catastrophic neglect in multi-concept generation can be mitigated. Overall, our work provides an advancement in understanding cross-attention layers and introduces new approaches for fine-controlling these layers at the head level.