 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Key Terms in Prompts for Relevance Evaluation with GPT Models
May 11, 2024



Relevance evaluation of a query and a passage is essential in Information Retrieval (IR). Recently, numerous studies have been conducted on tasks related to relevance judgment using Large Language Models (LLMs) such as GPT-4, demonstrating significant improvements. However, the efficacy of LLMs is considerably influenced by the design of the prompt. The purpose of this paper is to identify which specific terms in prompts positively or negatively impact relevance evaluation with LLMs. We employed two types of prompts: those used in previous research and generated automatically by LLMs. By comparing the performance of these prompts in both few-shot and zero-shot settings, we analyze the influence of specific terms in the prompts. We have observed two main findings from our study. First, we discovered that prompts using the term answerlead to more effective relevance evaluations than those using relevant. This indicates that a more direct approach, focusing on answering the query, tends to enhance performance. Second, we noted the importance of appropriately balancing the scope of relevance. While the term relevant can extend the scope too broadly, resulting in less precise evaluations, an optimal balance in defining relevance is crucial for accurate assessments. The inclusion of few-shot examples helps in more precisely defining this balance. By providing clearer contexts for the term relevance, few-shot examples contribute to refine relevance criteria. In conclusion, our study highlights the significance of carefully selecting terms in prompts for relevance evaluation with LLMs.
* 19pages, 2 figures
On-Off Pattern Encoding and Path-Count Encoding as Deep Neural Network Representations
Jan 17, 2024Understanding the encoded representation of Deep Neural Networks (DNNs) has been a fundamental yet challenging objective. In this work, we focus on two possible directions for analyzing representations of DNNs by studying simple image classification tasks. Specifically, we consider \textit{On-Off pattern} and \textit{PathCount} for investigating how information is stored in deep representations. On-off pattern of a neuron is decided as `on' or `off' depending on whether the neuron's activation after ReLU is non-zero or zero. PathCount is the number of paths that transmit non-zero energy from the input to a neuron. We investigate how neurons in the network encodes information by replacing each layer's activation with On-Off pattern or PathCount and evaluating its effect on classification performance. We also examine correlation between representation and PathCount. Finally, we show a possible way to improve an existing DNN interpretation method, Class Activation Map (CAM), by directly utilizing On-Off or PathCount.
Finding Inverse Document Frequency Information in BERT
Feb 24, 2022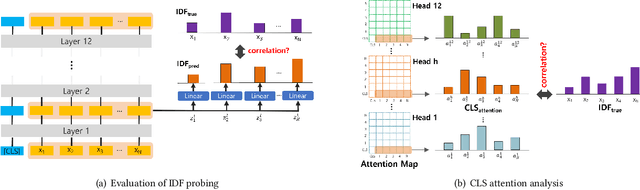

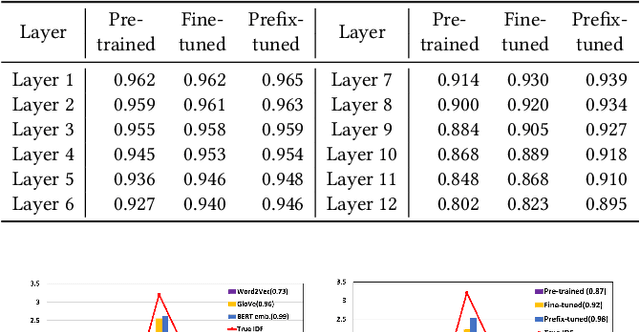

For many decades, BM25 and its variants have been the dominant document retrieval approach, where their two underlying features are Term Frequency (TF) and Inverse Document Frequency (IDF). The traditional approach, however, is being rapidly replaced by Neural Ranking Models (NRMs) that can exploit semantic features. In this work, we consider BERT-based NRMs and study if IDF information is present in the NRMs. This simple question is interesting because IDF has been indispensable for the traditional lexical matching, but global features like IDF are not explicitly learned by neural language models including BERT. We adopt linear probing as the main analysis tool because typical BERT based NRMs utilize linear or inner-product based score aggregators. We analyze input embeddings, representations of all BERT layers, and the self-attention weights of CLS. By studying MS-MARCO dataset with three BERT-based models, we show that all of them contain information that is strongly dependent on IDF.
Semi-Siamese Bi-encoder Neural Ranking Model Using Lightweight Fine-Tuning
Oct 28, 2021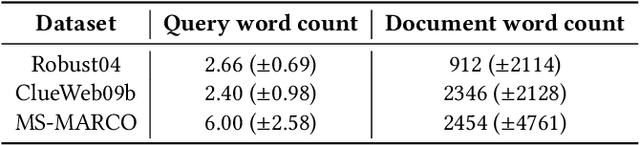
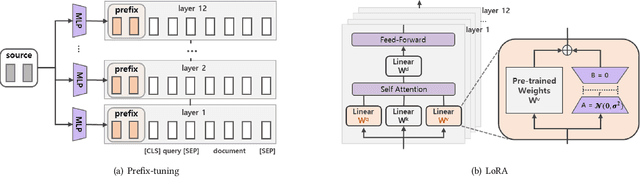

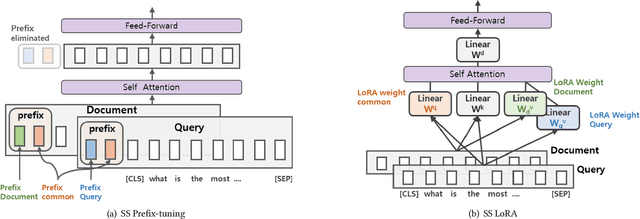
A BERT-based Neural Ranking Model (NRM) can be either a cross-encoder or a bi-encoder. Between the two, bi-encoder is highly efficient because all the documents can be pre-processed before the actual query time. Although query and document are independently encoded, the existing bi-encoder NRMs are Siamese models where a single language model is used for consistently encoding both of query and document. In this work, we show two approaches for improving the performance of BERT-based bi-encoders. The first approach is to replace the full fine-tuning step with a lightweight fine-tuning. We examine lightweight fine-tuning methods that are adapter-based, prompt-based, and hybrid of the two. The second approach is to develop semi-Siamese models where queries and documents are handled with a limited amount of difference. The limited difference is realized by learning two lightweight fine-tuning modules, where the main language model of BERT is kept common for both query and document. We provide extensive experiment results for monoBERT, TwinBERT, and ColBERT where three performance metrics are evaluated over Robust04, ClueWeb09b, and MS-MARCO datasets. The results confirm that both lightweight fine-tuning and semi-Siamese are considerably helpful for improving BERT-based bi-encoders. In fact, lightweight fine-tuning is helpful for cross-encoder, too.
Improving Bi-encoder Document Ranking Models with Two Rankers and Multi-teacher Distillation
Mar 11, 2021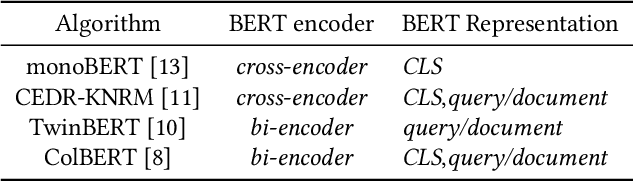
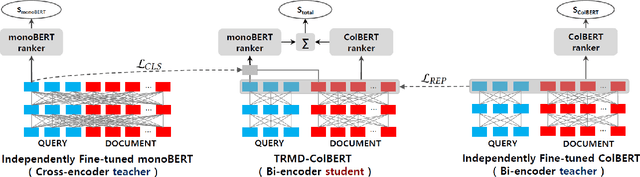
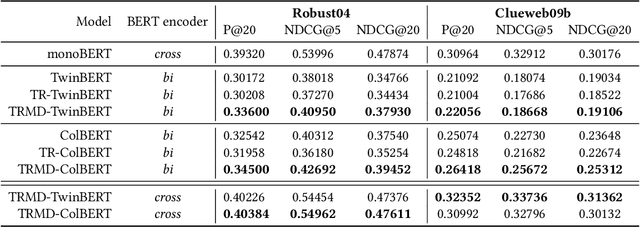
BERT-based Neural Ranking Models (NRMs) can be classified according to how the query and document are encoded through BERT's self-attention layers - bi-encoder versus cross-encoder. Bi-encoder models are highly efficient because all the documents can be pre-processed before the query time, but their performance is inferior compared to cross-encoder models. Both models utilize a ranker that receives BERT representations as the input and generates a relevance score as the output. In this work, we propose a method where multi-teacher distillation is applied to a cross-encoder NRM and a bi-encoder NRM to produce a bi-encoder NRM with two rankers. The resulting student bi-encoder achieves an improved performance by simultaneously learning from a cross-encoder teacher and a bi-encoder teacher and also by combining relevance scores from the two rankers. We call this method TRMD (Two Rankers and Multi-teacher Distillation). In the experiments, TwinBERT and ColBERT are considered as baseline bi-encoders. When monoBERT is used as the cross-encoder teacher, together with either TwinBERT or ColBERT as the bi-encoder teacher, TRMD produces a student bi-encoder that performs better than the corresponding baseline bi-encoder. For P@20, the maximum improvement was 11.4%, and the average improvement was 6.8%. As an additional experiment, we considered producing cross-encoder students with TRMD, and found that it could also improve the cross-encoders.