 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFlex: Text-Guided Editing of Real Images in Rectified Flow via Mid-Step Feature Extraction and Attention Adaptation
Jul 02, 2025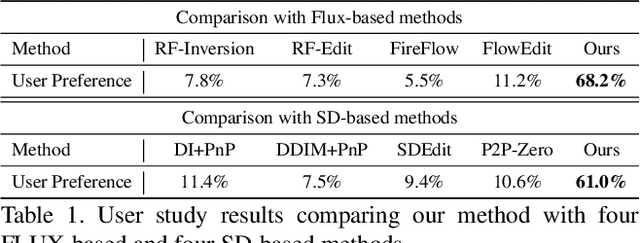

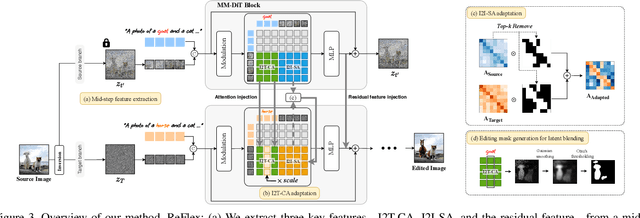

Rectified Flow text-to-image models surpass diffusion models in image quality and text alignment, but adapting ReFlow for real-image editing remains challenging. We propose a new real-image editing method for ReFlow by analyzing the intermediate representations of multimodal transformer blocks and identifying three key features. To extract these features from real images with sufficient structural preservation, we leverage mid-step latent, which is inverted only up to the mid-step. We then adapt attention during injection to improve editability and enhance alignment to the target text. Our method is training-free, requires no user-provided mask, and can be applied even without a source prompt. Extensive experiments on two benchmarks with nine baselines demonstrate its superior performance over prior methods, further validated by human evaluations confirming a strong user preference for our approach.
Towards a Better Evaluation of Out-of-Domain Generalization
Jun 02, 2024The objective of Domain Generalization (DG) is to devise algorithms and models capable of achieving high performance on previously unseen test distributions. In the pursuit of this objective, average measure has been employed as the prevalent measure for evaluating models and comparing algorithms in the existing DG studies. Despite its significance, a comprehensive exploration of the average measure has been lacking and its suitability in approximating the true domain generalization performance has been questionable. In this study, we carefully investigate the limitations inherent in the average measure and propose worst+gap measure as a robust alternative. We establish theoretical grounds of the proposed measure by deriving two theorems starting from two different assumptions. We conduct extensive experimental investigations to compare the proposed worst+gap measure with the conventional average measure. Given the indispensable need to access the true DG performance for studying measures, we modify five existing datasets to come up with SR-CMNIST, C-Cats&Dogs, L-CIFAR10, PACS-corrupted, and VLCS-corrupted datasets. The experiment results unveil an inferior performance of the average measure in approximating the true DG performance and confirm the robustness of the theoretically supported worst+gap measure.
Selectively Informative Description can Reduce Undesired Embedding Entanglements in Text-to-Image Personalization
Mar 22, 2024



In text-to-image personalization, a timely and crucial challenge is the tendency of generated images overfitting to the biases present in the reference images. We initiate our study with a comprehensive categorization of the biases into background, nearby-object, tied-object, substance (in style re-contextualization), and pose biases. These biases manifest in the generated images due to their entanglement into the subject embedding. This undesired embedding entanglement not only results in the reflection of biases from the reference images into the generated images but also notably diminishes the alignment of the generated images with the given generation prompt. To address this challenge, we propose SID~(Selectively Informative Description), a text description strategy that deviates from the prevalent approach of only characterizing the subject's class identification. SID is generated utilizing multimodal GPT-4 and can be seamlessly integrated into optimization-based models. We present comprehensive experimental results along with analyses of cross-attention maps, subject-alignment, non-subject-disentanglement, and text-alignment.
Harmonizing Visual and Textual Embeddings for Zero-Shot Text-to-Image Customization
Mar 21, 2024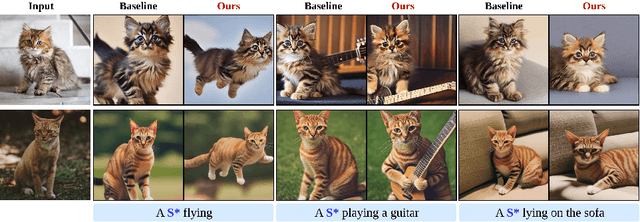
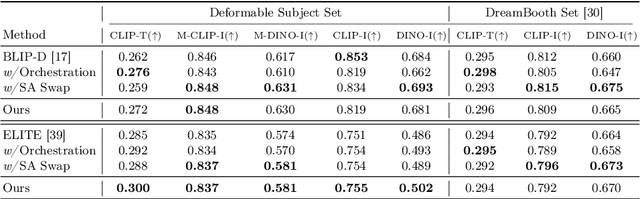
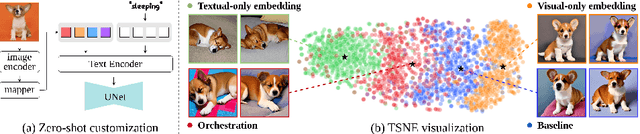
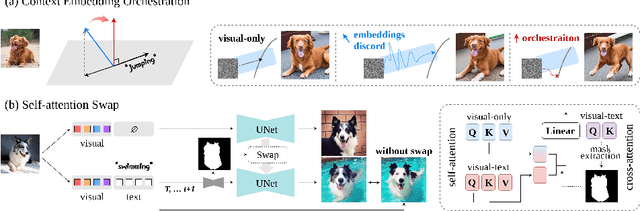
In a surge of text-to-image (T2I) models and their customization methods that generate new images of a user-provided subject, current works focus on alleviating the costs incurred by a lengthy per-subject optimization. These zero-shot customization methods encode the image of a specified subject into a visual embedding which is then utilized alongside the textual embedding for diffusion guidance. The visual embedding incorporates intrinsic information about the subject, while the textual embedding provides a new, transient context. However, the existing methods often 1) are significantly affected by the input images, eg., generating images with the same pose, and 2) exhibit deterioration in the subject's identity. We first pin down the problem and show that redundant pose information in the visual embedding interferes with the textual embedding containing the desired pose information. To address this issue, we propose orthogonal visual embedding which effectively harmonizes with the given textual embedding. We also adopt the visual-only embedding and inject the subject's clear features utilizing a self-attention swap. Our results demonstrate the effectiveness and robustness of our method, which offers highly flexible zero-shot generation while effectively maintaining the subject's identity.
Enhancing Contrastive Learning with Efficient Combinatorial Positive Pairing
Jan 11, 2024In the past few years, contrastive learning has played a central role for the success of visual unsupervised representation learning. Around the same time, high-performance non-contrastive learning methods have been developed as well. While most of the works utilize only two views, we carefully review the existing multi-view methods and propose a general multi-view strategy that can improve learning speed and performance of any contrastive or non-contrastive method. We first analyze CMC's full-graph paradigm and empirically show that the learning speed of $K$-views can be increased by $_{K}\mathrm{C}_{2}$ times for small learning rate and early training. Then, we upgrade CMC's full-graph by mixing views created by a crop-only augmentation, adopting small-size views as in SwAV multi-crop, and modifying the negative sampling. The resulting multi-view strategy is called ECPP (Efficient Combinatorial Positive Pairing). We investigate the effectiveness of ECPP by applying it to SimCLR and assessing the linear evaluation performance for CIFAR-10 and ImageNet-100. For each benchmark, we achieve a state-of-the-art performance. In case of ImageNet-100, ECPP boosted SimCLR outperforms supervised learning.
Evaluating Feature Attribution Methods for Electrocardiogram
Nov 23, 2022



The performance of cardiac arrhythmia detection with electrocardiograms(ECGs) has been considerably improved since the introduction of deep learning models. In practice, the high performance alone is not sufficient and a proper explanation is also required. Recently, researchers have started adopting feature attribution methods to address this requirement, but it has been unclear which of the methods are appropriate for ECG. In this work, we identify and customize three evaluation metrics for feature attribution methods based on the characteristics of ECG: localization score, pointing game, and degradation score. Using the three evaluation metrics, we evaluate and analyze eleven widely-used feature attribution methods. We find that some of the feature attribution methods are much more adequate for explaining ECG, where Grad-CAM outperforms the second-best method by a large margin.